TimeCMA: Towards LLM-Empowered Multivariate Time Series Forecasting via Cross-Modality Alignment (AAAI 2025) 논문리뷰
1. Introduction
다변수 시계열 예측(MTSF)의 성능을 높이기 위해, 시계열과 텍스트를 결합한 LLM 기반 프레임워크인 TimeCMA를 제안함.
Problem Define
-
전통적 딥러닝 모델: 학습 파라미터 수의 한계로 인해 데이터가 부족한 상황(Low-data regime)에서 성능이 급격히 저하됨.
-
기존 LLM 기반 모델: 시계열을 자연어로 변환해 LLM에 입력하나, 시계열 고유의 정보와 텍스트 정보가 복잡하게 얽히는 Data Entanglement 발생.
-
노이즈 문제: 시계열 임베딩과 텍스트를 단순 결합(Concat)할 경우, 텍스트가 시계열 신호의 노이즈로 작용하여 예측 정확도를 떨어뜨림.
보통 LLM 기반 시계열 예측 모델은 시계열을 자연어로 만든 다음 그대로 LLM에 넣는 방식 사용 → 어디서 어떤 정보가 나왔는지 알 수가 없음. 의미(정보)가 섞여있음
반면, TimeCMA의 경우 entangled 하지만 풍부한 자연어 데이터 + disentangle 하지만 상대적으로 약한 시계열 임베딩 모두를 사용해서 성능 향상
Contribution
- Dual-Modality Encoding (이중 경로 인코딩)
두 가지 경로로 데이터를 인코딩하여 상호 보완적인 특징을 학습함.
-
시계열 브랜치 (TS Branch): 정제(Disentangled)된 형태이나 상대적으로 표현력이 약한 시계열 임베딩 생성.
-
LLM 브랜치 (Text Branch): 시계열을 자연어 프롬프트화하여 Robust하고 풍부하지만, 정보가 얽힌(Entangled) 임베딩 생성.
- Cross-Modality Alignment (교차 모달리티 정렬)
-
선택적 정보 추출: 두 임베딩 간의 유사도를 기반으로 LLM 임베딩 중 시계열 특징과 일치하는 핵심 정보만 필터링함.
-
노이즈 제거: 단순 결합 시 발생하는 텍스트 노이즈 문제를 해결하고 정보의 순도를 높임.
- 효율성 및 추론 최적화 (Efficiency)
-
LLM의 고질적인 문제인 연산 비용과 속도를 해결하기 위해 두 가지 최적화 기법을 도입함.
-
Last-Token 집중 설계:
- 텍스트 프롬프트의 마지막 토큰에 모든 핵심 시퀀스 정보가 응축되도록 유도함.
- 추론 시 LLM의 전체 토큰이 아닌 마지막 토큰 임베딩만 사용하여 연산량 급감. -
Inference 속도 개선:
- 마지막 토큰 임베딩을 저장(Caching)하여 재사용하는 구조를 통해 실시간 예측 환경에서도 빠른 대응이 가능함.
- 결과적으로 LLM의 강력한 추론 능력을 유지하면서도 계산 비용을 대폭 낮춤.
2. Related Work
Related Work는 생략하도록 한다.
3. Methodology
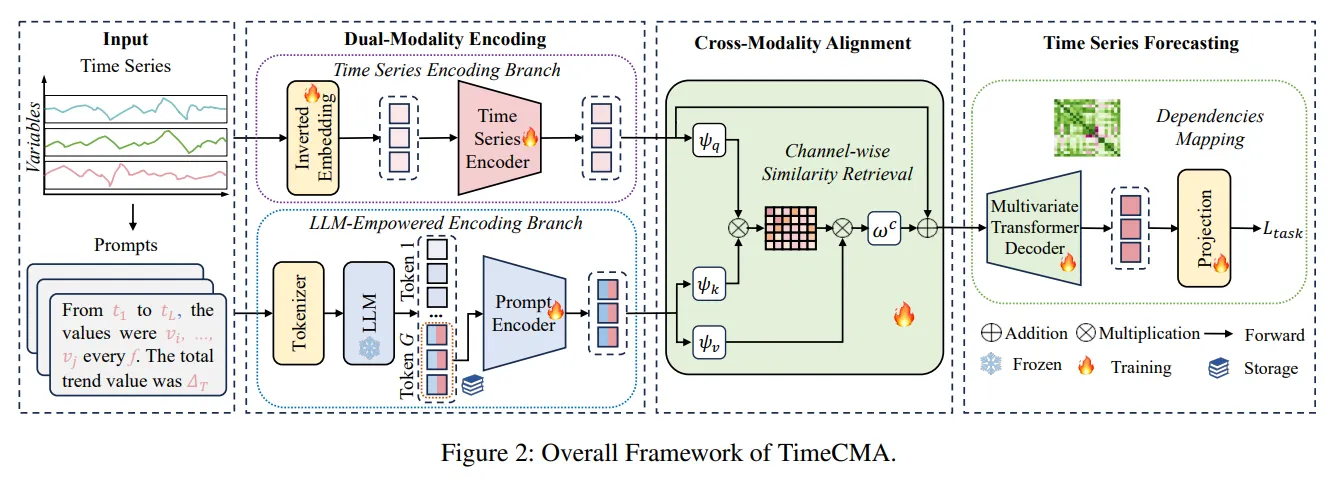
3.1 Dual-Modality Encoding
Time Series Encoding Branch
- 시계열 데이터를 전통적인 딥러닝 방식으로 처리하는 브랜치
(1) 입력 데이터 정의
X_T ∈ ℝ^(T × N)T: 시계열의 길이 (time steps)N: 변수 개수 (예: 온도, 습도, 인구수 등)
즉, 각 열이 하나의 변수이고 각 행이 시간에 따른 값을 의미
(2) Inverted Embedding
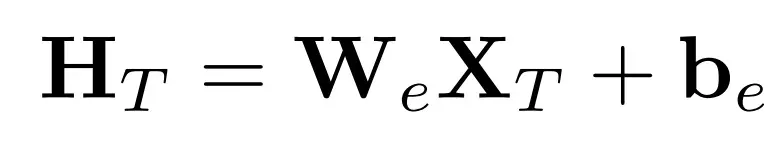
X_T: 원래 시계열 데이터 (T × N)W_e: 학습 가능한 가중치 (C × T)b_e: bias (C × N)H_T: 최종 시계열 임베딩 (C × N) — 각 변수마다 하나의 벡터
즉, 각 변수에 대해 하나의 벡터 표현(embedding)을 만들어냄.
-
"변수가 곧 토큰이다"
변수 단위 토큰화: 하나의 변수(Channel)가 가진 전체 시계열 데이터를 단일 '토큰'으로 정의함. -
통념의 전환: 시점(Time-step)마다 벡터를 만드는 기존 방식과 달리, 변수별로 하나의 임베딩 벡터를 생성함.
-
기존 방식과 비교

(3) 시계열 정규화 (Reversible Instance Normalization)
- 시계열 변수들의 분포 차이(distribution shift)를 줄이기 위해 입력
X_T를 평균 0, 표준편차 1로 정규화
(4) TSEncoder: Pre-LN Transformer 사용
- H_T 벡터들을 Transformer로 처리하여 시계열 간 상호작용 학습
- 여기서 Pre-LN (Pre-LayerNorm) 구조 사용:
- 원래 Transformer는 "Attention → FFN → LayerNorm"
- Pre-LN은 "먼저 LayerNorm → Attention/FFN"→ 학습 안정성 및 수렴 속도 향상됨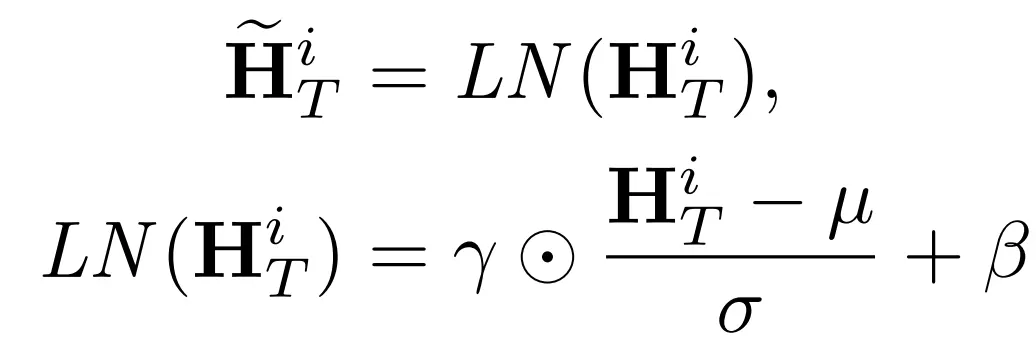
H_T^i: i번째 layer의 입력He_T^i: i번째 layer의 normalized outputμ,σ: 평균과 표준편차γ,β: 학습 가능한 scaling/shift 파라미터
→ 이 과정을 거치며 변수 간 표현을 학습하게 됨.
3.2 LLM-Empowered Encoding Branch
(1) Pre-trained LLM: GPT-2
- GPT-2는 텍스트 입력을 받아 고차원 임베딩으로 바꾸는 모델
- 여기서 중요한 건:
- GPT-2는 파라미터를 모두 동결 (frozen): 학습하지 않음
- 단지, 텍스트를 임베딩으로 바꾸는 역할만 수행
(2) Tokenizer 처리
PS ∈ ℝ^(S × N) → PG ∈ ℝ^(G × N)PS: 입력 프롬프트 텍스트 (ex. “The temp readings were 23.4, 24.1, 25.0”)PG: 토크나이저로 바꾼 GPT-2의 token ID
각 시계열 변수마다 1개의 프롬프트 문장을 만듭니다 (즉, N개의 프롬프트 → 각각 G개의 token)
(3) GPT-2 인코딩 구조**
Transformer 디코더 구조를 따릅니다. 수식 정리해보면:
- Position Encoding 추가
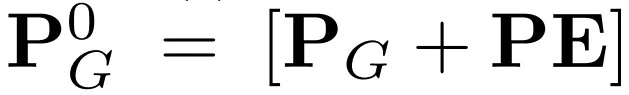
- GPT-2의 i번째 Layer 처리
- (9) Multi-head masked self-attention (MMSA)
- (10) Feed-forward network
- (11) MMSA 내부 연산
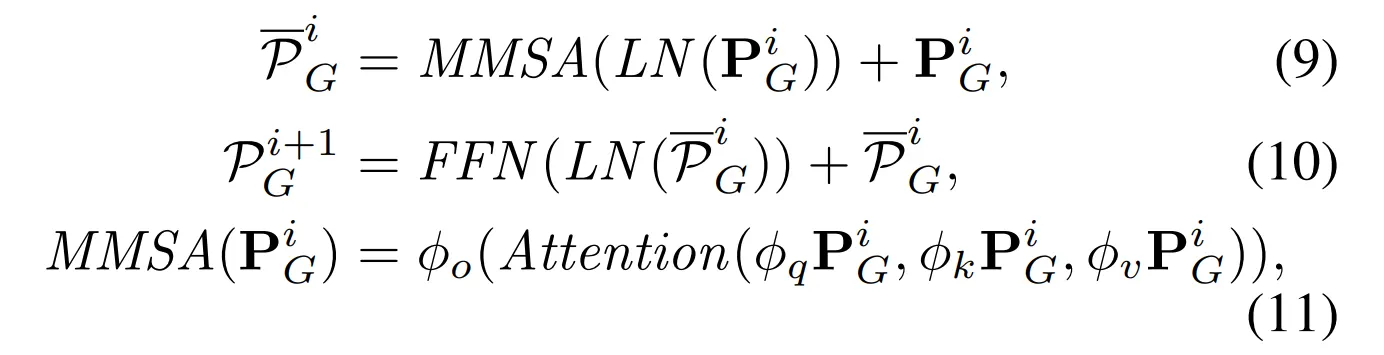
→ 여기서 ϕₒ, ϕ_q, ϕ_k, ϕ_v는 각각 Output / Query / Key / Value를 위한 선형변환
(4) Last Token Embedding 저장
왜 GPT-2에서 나온 전체 토큰이 아니라 "마지막 토큰"만 쓰는가?
- GPT-2는 masked self-attention 구조라서 마지막 토큰은 앞선 모든 토큰의 정보를 집약한 요약본 역할
→ 효율성 ↑, 성능 유지
LN = {l₁, ..., l_N} ∈ ℝ^(N × E)LN: N개의 변수 각각에 대한 마지막 토큰 임베딩 (각 크기 E)
이걸 저장해놓고 계속 재활용함 (GPT2 파라미터 업데이트 안하니까) → 학습 속도와 추론 속도 개선
(5) PromptEncoder 정의**
- GPT-2를 거쳐 나온 마지막 토큰 임베딩(LN)을 후처리해서, 시계열 임베딩과 결합 가능한 형태로 바꾸는 Transformer 인코더 역할
3.3 Cross-Modality Alignment
(1) Linear 변환 (공통 공간으로 투영)
먼저 시계열 임베딩 H_T와 LLM 임베딩 L_N을 동일한 임베딩 공간으로 바꾸기 위해,
3개의 선형 레이어를 사용
ψ_q(H_T) → Query
ψ_k(L_N) → Key
ψ_v(L_N) → Value이건 Self-Attention의 구조를 그대로 따름
(2) Channel-wise 유사도 계산
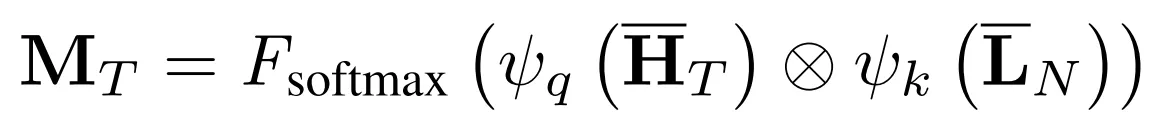
⊗: 행렬 곱M_T: 유사도 매트릭스 (C × E)- 시계열 임베딩의 각 채널(C)이 LLM 임베딩의 각 차원(E)에 얼마나 주목할지를 나타냄
- softmax: attention 가중치 정규화
→ 각 시계열 채널이 어떤 LLM 표현 차원을 참고할지 선택
(3) 임베딩 정제 및 결합
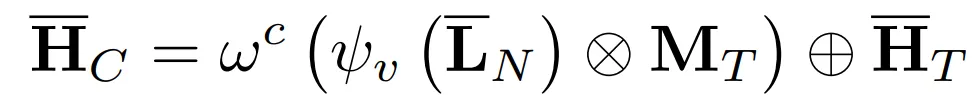
ψ_v(L_N) ⊗ M_T: LLM 표현에서 주목할 부분만 추출 (attention-based aggregation)ω_c: 또 다른 선형 레이어로 변환⊕ H_T: 시계열 원본과 합쳐서 residual connection → 원래 시계열 구조를 유지하면서 LLM 정보 덧입힘
3.4 Time Series Forecasting
(1) 입력: Cross-Modality 임베딩
- 시계열 브랜치와 LLM 브랜치가 결합된 고차원 벡터를 입력으로 사용함.
- 각 변수(Variable)별로 길이 를 가진 임베딩을 보유한 상태임.
(2) Layer Norm: 정규화
- 학습 과정에서 발생하는 내부 공변량 변화(Internal Covariate Shift)를 방지하고 학습의 안정성을 높임. 각 임베딩의 스케일을 일정하게 맞춰주어 모델이 특정 변수에 편향되지 않도록 함.
(3) Masked Multi-Head Self Attention (MMSA)
- Inverted Embedding 구조를 취하고 있으므로, 시간축이 아닌 변수 간의 상관관계(Inter-variable correlation)를 집중적으로 학습함. Masking을 통해 예측 시점 이후의 정보 간섭을 차단하며 데이터의 인과 관계를 보존함.
(4) 두번째 LayerNorm + Cross Attention
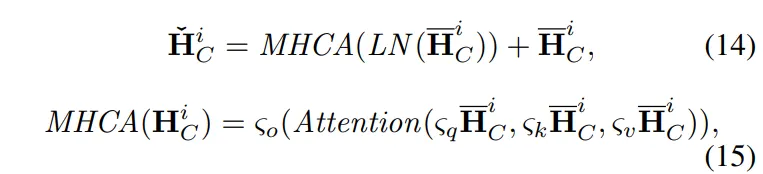
- 두 모달리티(시계열/텍스트) 간의 정보를 교차 참조하여, 시계열 예측에 가장 최적화된 특징을 다시 한번 정렬함.
(5) Projetion Layer → 예측 값 생성
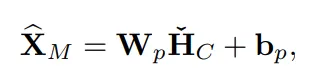
W_p: 선형 weight matrixb_p: bias- 입력
Ȟ_C ∈ ℝ^(C × N)→ 출력X̂_M ∈ ℝ^(M × N)
각 변수에 대해 미래 M타임스텝 예측값 생성됨
(6) Denormalization
- 모델 성능 향상을 위해 전처리 단계에서 정규화(Standardization 등)했던 데이터를 실제 물리적인 수치로 다시 되돌리는 과정임.
(7) Loss 계산 식
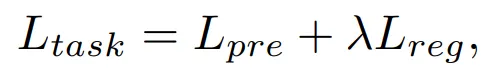
예측 손실 (Prediction Loss: MSE)
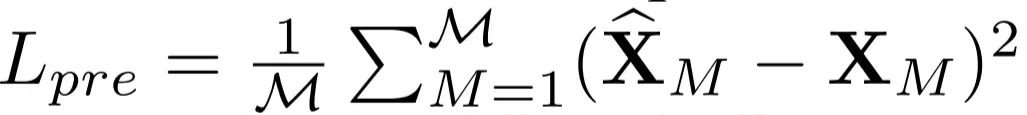
- 정규화 손실 (Regularization Loss): 모델 파라미터의 L2 norm
→ 람다로 두 loss의 비중 조절
4. Experiment
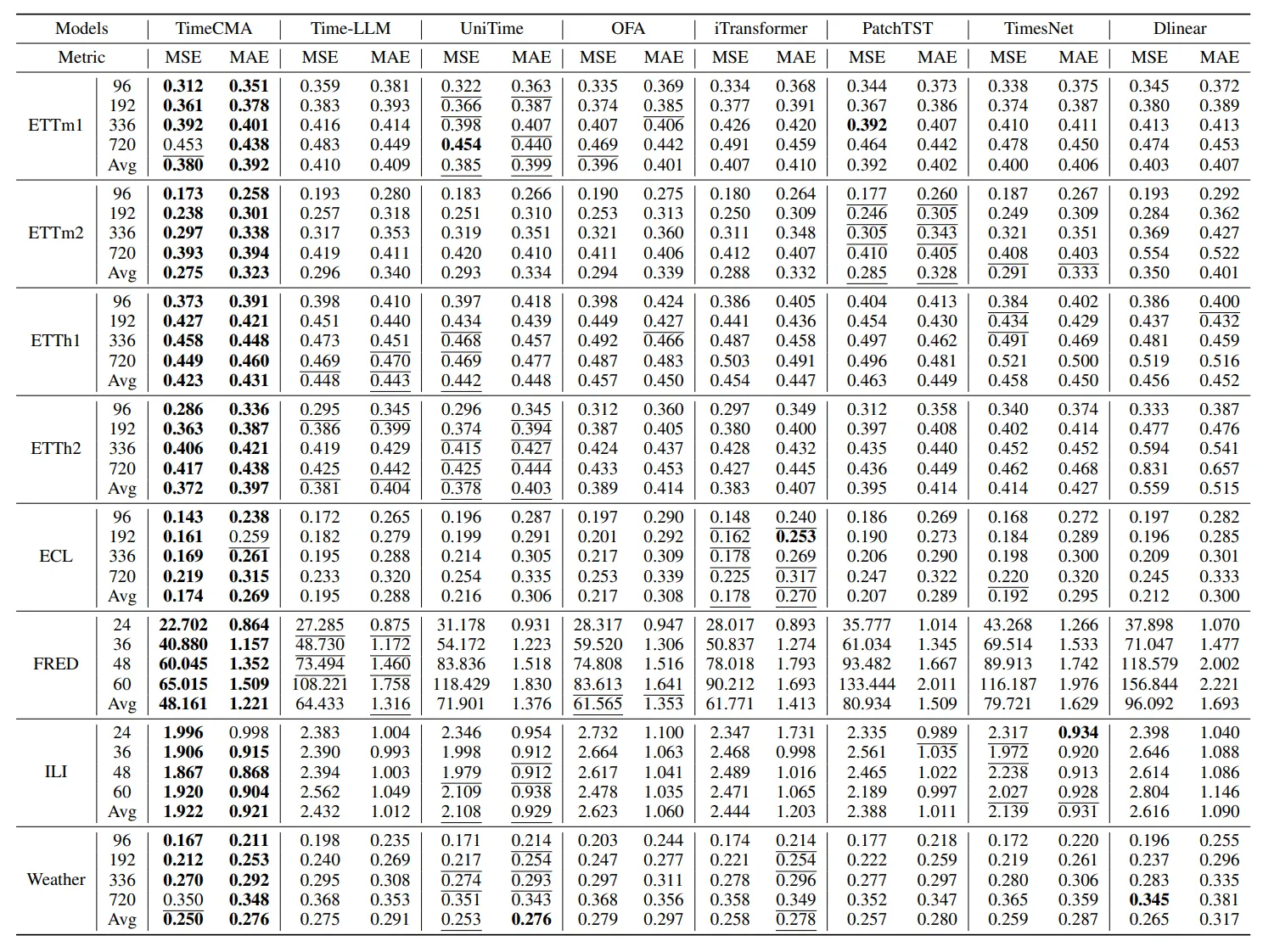
(1) 성능 비교 실험
- 총 8개의 벤치마크 데이터셋, prompt 기반 LLM, 시계열 전용 LLM, Transformer 계열, 선형, CNN과 비교
→ LLM base 모델이 딥러닝이나 linear한 전통적인 모델보다 성능이 나음
→ Inverted embedding is essential for capturing multivariate dependencies
- Inverted embedding은 변수가 많은 데이터셋에서 더 강력한 성능을 발휘
- 결론: LLM + Prompt + Inverted 구조 조합이 매우 효과적
(2) Ablation Studies of Model Design
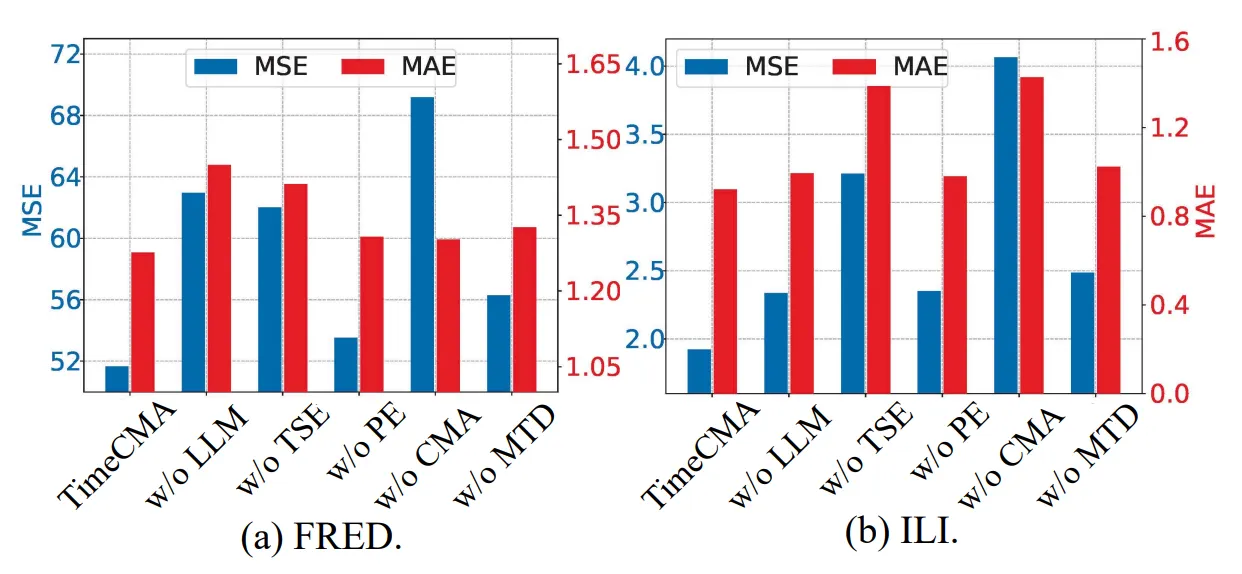
- Cross-modality alignment는 단순한 concat보다 훨씬 효과적
- 시계열 인코더와 LLM 브랜치가 모두 필요
- PromptEncoder는 있어도 좋지만, 성능 기여는 상대적으로 낮음
(3) Ablation Studies of Model Design
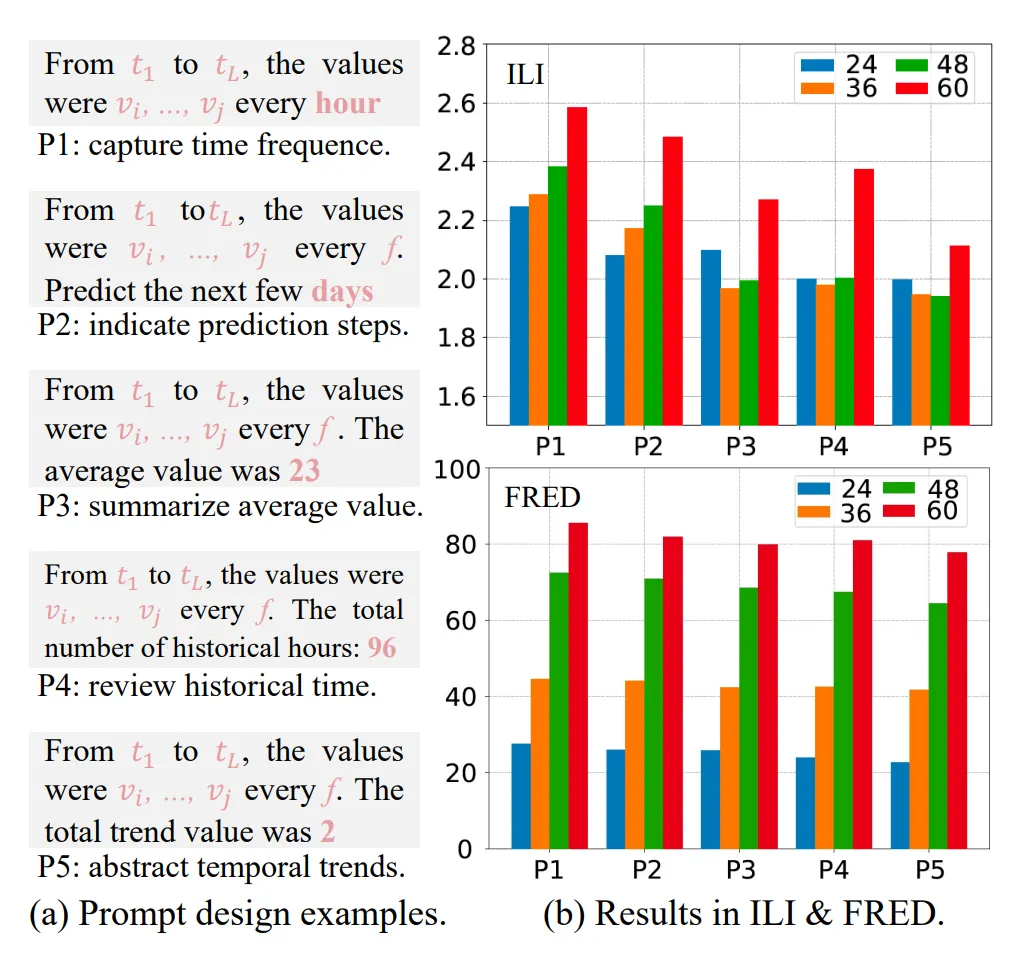
- 실험 내용 5가지 종류의 프롬프트를 실험 (Fig. 4a 참조)
- Prompt 1: capture time frequence
- Prompt 2: indicate prediction steps
- Prompt 3: summarize average value
- Prompt 4: review historical time
- Prompt 5: 추세 요약 (trend abstraction)
MSE 기준 숫자가 마지막 토큰으로 끝나는 프롬프트가 성능이 좋음
- Prompt 5 > Prompt 3 > Prompt 2 순
- Prompt 5는 추세 요약이므로 가장 유익한 정보 포함
- Prompt 3는 평균값 기반이라 불필요한 노이즈 포함 가능
- Prompt 1, 2는 문장형태가 많아 성능 낮음
(4) Last Token Attention Analysis (GPT-2 마지막 토큰집중 분석)
- 방법:
- 프롬프트를 텍스트 영역 / 시계열 수치 영역으로 나눔
- GPT-2 마지막 레이어에서 마지막 토큰 <ΔT>가 어디에 attention을 주는지 시각화
-
결과 (Fig. 5 참조):
-
GPT-2의 마지막 토큰은 텍스트보다 시계열 값에 더 집중함
-
→ 이는 "프롬프트 안에 포함된 수치 정보"가 실제로 LLM 임베딩 품질에 영향을 주는 걸 의미