DB 인덱스
DB 인덱스란?
책으로 비유하면 목차같은 개념이다.
우리가 원하는 파트를 보고 싶을 때 목차에서 먼저 해당 파트가 어느 부분에 있는지 확인하면 한장씩 넘길 때보다 더 빨리 찾을 수 있다.
DB에서도 마찬가지로 테이블에 대해 검색속도를 높혀주는 자료구조로써 역할을 한다.
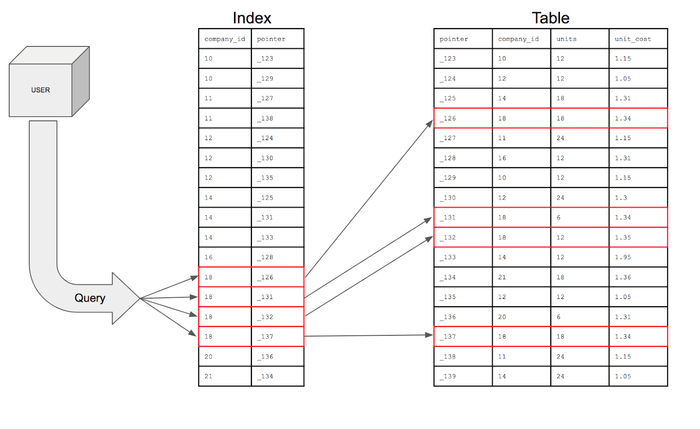
인덱스 생성원리
테이블의 인덱스를 생성할 때, 특정컬럼의 데이터를 정렬하여 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장한다.
DBMS의 인덱스 관리방법 및 인덱스 단점
인덱스는 항상 정렬된 상태를 유지해야 빠르게 탐색이 가능하다.
그러므로 삽입, 삭제, 갱신 연산이 수행되고 난 후에는 인덱스에 다음과 같은 연산을 추가적으로 수행한다.
삽입: 새로운 데이터에 대한 인덱스블록 추가
삭제: 삭제하는 데이터의 인덱스블록을 사용하지 않는다는 작업을 추가
갱신: 기존 인덱스블록은 사용하지 않음 처리 및 갱신된 데이터에 대해 인덱스 블록 추가
이러한 추가적인 연산들 때문에 오버헤드가 발생한다.
또한 인덱스를 관리하기 위해 약 10%의 추가적인 공간이 필요하다.
삭제, 갱신 연산이 빈번한 컬럼에 대해 인덱스를 생성하면 인덱스의 크기가 커지게 되어 오히려 성능이 저하된다.
그 이유는 위에서 설명한 것처럼 삭제와 갱신 연산은 기존의 인덱스블록을 삭제하거나 덮어씌우는게 아니라 사용하지 않음 처리를 하기 때문에 실제 테이블의 데이터보다 더 많은 인덱스블록을 가지게 되기 때문이다.
인덱스의 장점
테이블을 생성한 후 데이터 삽입을 하면 데이블의 레코드는 내부적으로 데이터의 순서와 상관없이 저장된다. 이때 WHERE절을 사용하여 조회를 하면 Full Scan을 통해 조건 비교를 하게된다.
하지만 인덱스에는 데이터가 정렬이 이미 되어있으니, 데이터를 빨리 탐색할 수 있게 된다.
이러한 장점으로 인해 몇가지 조건에도 효율성이 증대될 수 있다.
WHERE절의 효율성
위에서 설명한 것과 같이 미리 정렬이 되어있으니 Full Scan을 통해 비교를 할 필요가 없어 효율성이 높아진다.
ORDER BY절의 효율성
ORDER BY의 정렬 과정은 부하가 매우 큰 작업이다. 하지만 인덱스에는 정렬이 되어있으니 정렬과정을 거칠 필요가 없어 효율이 높아진다.
MIN, MAX의 효율적인 처리
인덱스 블록의 시작값과 마지막 값만을 가져오면 되니 효율적이다.
인덱스를 사용하면 좋은 경우
- 규모가 작지 않은 테이블
- 삽입, 삭제, 갱신이 자주 발생하지 않는 컬럼
- 분포도가 높은 컬럼
인덱스 생성전략
- 조건절에 자주 등장하는 컬럼을 사용
- 항상 = 으로 비교되는 컬럼
- 분포도가 높은 컬럼(데이터 중복이 최소화 된 데이터)
- ORDER BY 절에서 자주 사용되는 컬럼
- 조인 조건으로 자주 사용되는 컬럼
