개요
1. 데이터 프로파일링이란?
1) 데이터 내 값의 분포, 변수간의 관계, 결측값 존재 유무 등을 분석 (본격적인 전처리 과정 전, 데이터의 형태를 파악하는 의미가 있음)
2) EDA를 수행하는것이라고도 불림
2. EDA(탐색적 데이터 분석)란?
1) 수집한 데이터를 분석하기 전에 그래프나 통계적인 방법을 이용하여 다양한 각도에서 데이터의 특징을 파악하고 자료를 직관적으로 바라보는 분석 방법
2) EDA를 통해서 데이터 전처리, 피쳐 엔지니어링의 방향을 확보가능

3. EDA 프로세스
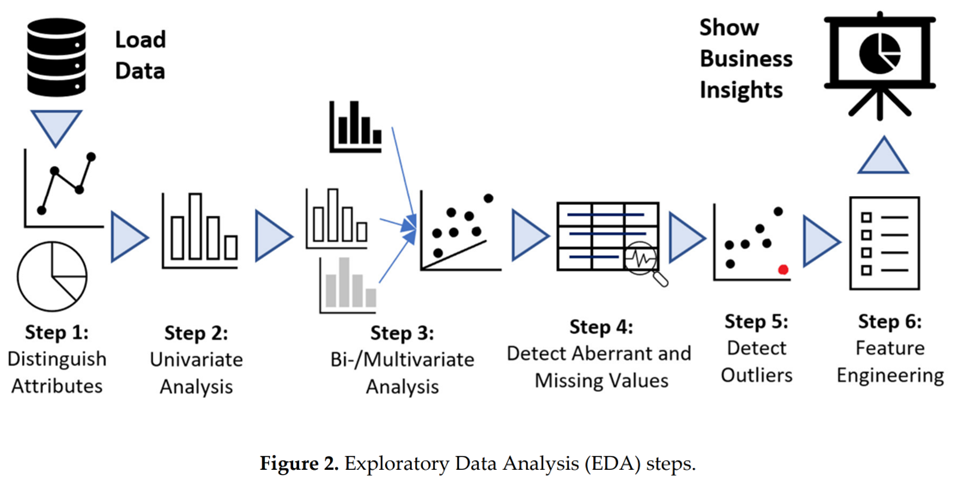
Step 1: 데이터의 속성(변수, feature) 확인
Step 2: 각 피쳐별 단변량 데이터 분석
Step 3: 피쳐간 상관관계 분석
Step 4: 결측치 처리
Step 5: 이상치 처리
Step 6: 피쳐 엔지니어링을 통한 피쳐 선택, 추가, 삭제
Python 패키지 별 데이터프로파일링 코드
1. klib
1) klib이란?
- Pandas 데이터프레임을 기반으로 데이터전처리 및 프로파일링을 제공해주는 패키지
- 데이터 품질평가, 데이터 전처리, 관계시각화를 목적으로 사용
- 속도가 상당히 빠르며, 유려한 시각화 기능을 제공
2) 사용가능한 메서드 모음
- klib.describe(시각화 메서드)
klib.cat_plot(df) # 범주형 변수 프로파일링
klib.corr_mat(df) # 상관관계 매트릭스
klib.corr_plot(df) # 상관관계
klib.dist_plot(df) # 분포
klib.missingval_plot(df) # 결측치- klib.clean(데이터정제 메서드)
klib.data_cleaning(df) # 데이터 유형변경, 중복/결측치행 삭제등등..
klib.clean_column_names(df) # 컬럼명 변경
klib.convert_datatypes(df) # 데이터 유형 변경
klib.drop_missing(df) # 결측행 삭제
klib.mv_col_handling(df) # 피처 삭제
klib.pool_duplicate_subsets(df) # 중복 데이터 삭제- klib.preprocess(데이터 전처리)
klib.train_dev_test_split(df) # 데이터세트 분리
klib.feature_selection_pipe() # 피쳐 선택
klib.num_pipe() # 수치형 데이터 처리
klib.cat_pipe() # 범주형 데이터 처리
klib.preprocess.ColumnSelector() # 피쳐 선택
klib.preprocess.PipeInfo() # 전처리 파이프 라인처리3) 예시코드
# klib, pandas, seaborn라이브러리 불러오기
import klib
import pandas as pd
import seaborn as sns # 예시데이터(타이타닉) 사용하기위함
df = sns.load_dataset("titanic")
df.head()
# 결측치에 대한 프로파일링 그래프
klib.missingval_plot(df)
# 양의 상관관계 그래프
klib.corr_plot(df, split='pos')
# 음의 상관관계 그래프
klib.corr_plot(df, split='neg')
# 변수(피처)간 상관관계 그래프
klib.corr_plot(df, target='age')
# 각종 분포 그래프
klib.dist_plot(df)
# 데이터 정제(결측치나 중복된 행같은 것들을 자동으로 제거해줌)
df_cleaned = klib.data_cleaning(df)2. ydata-profiling
1) ydata-profiling(구 pandas-profiling)이란?
- 프로파일링을 손쉽게 수행할 수 있는 기능을 모아놓은 강력한 패키지
- 타입추론 / 단변량 분석 / 다변량 분석 / 시계열 / 텍스트 분석
/ 파일 및 이미지 분석 / 데이터 세트 비교등의 기능을 지님 - 실행속도가 느리다는 단점이 있음
2) 예시코드
- 필요한 패키지 가져오기
import numpy as np
import pandas as pd
from ydata_profiling import ProfileReport- 테스트 데이터 만들기
df = pd.DataFrame(np.random.rand(100, 5), columns=["a", "b", "c", "d", "e"])
print(df.head()) # 모양 확인- 프로파일링 레포트 생성
profile = ProfileReport(df, title="Ydata Profiling Report")
# HTML 보고서와 유사한 방식으로 셀에 직접 포함
profile.to_notebook_iframe()
# HTML로 별도 저장
profile.to_file("../data/my_profiling_report.html")- NLP(자연어 처리)를 위한 네이버 영화 리뷰 데이터 프로파일링
- 사전에 ko_test.csv 다운로드 필요함
- 아래는 형식만 참고하고, 그때그때 필요한 데이터를 프로파일링하면 됨
import pandas as pd
movie_df = pd.read_csv('../data/ko_test_label.csv', sep = ',')
print(movie_df.head(5))
# 프로파일링 레포트 생성
pf_movie = ProfileReport(movie_df, title="네이버 영화 리뷰 데이터에 대한 프로파일링 보고서")
pf_movie.to_notebook_iframe()
# HTML로 별도 저장
pf_movie.to_file("../data/review_profiling_report.html")3. PyGWalker
1) PyGWalker란?
- PyGWalker는 시각화를 이용한 탐색적 데이터 분석을 하는데 사용되는Python 라이브러리
- pandas 데이터 프레임을 시각적 탐색을 위한 Tableau 스타일 사용자 인터페이스로 제공
- 간단한 끌어서 놓기 작업으로 데이터를 분석하고 패턴을 시각화 가능
2) 예시 코드
- 필요 패키지 가져오기
import pandas as pd
import pygwalker as pyg- Pandas 데이터프레임으로 pygwalker 실행
# seaborn에서 타이타닉데이터를 가져옴
import seaborn as sns
df_titanic = sns.load_dataset('titanic')
# pygwalker 실행(gwalker에 저장)
gwalker = pyg.walk(df_titanic).display_on_jupyter()
Data Scientist