- 과거에는 DB 정규화 기반 서비스를 이용
- ETL: 데이터를 수집함에 있어서, schema 에 맞게 변환 후 적재가 이루어짐
- Extract -> Transfrom -> Load
- 현재는 발생하는 데이터의 양이 방대해져, ETL 로는 관리가 힘들어짐
- ELT: 데이터가 저장된 후 목적에 맞게 변환된다.
- RDB 가 아니어도 사용 가능하다 (NoSQL 등)
Data Storage
Data Lake
- 데이터를 전처리를 거치지 않고 무작정 쌓아두는 곳
- log 기록이 쌓이는 disk 등
- 이런 데이터를 모두 RDB 에 적재하는 것은 느린 작업이 될 수 있다.
- Lake 구축에는 주로
Hadoop 을 이용한 분산처리가 이용된다 - "당근, 감자, 고구마가 모두 섞여 자라는 밭"
Data Warehouse
- Data Lake 에 쌓인 데이터들을 이용해 가치를 창출해야 하는 경우를 생각해보자
- 이를 위해 data 를 목적에 맞게 분류해 저장하는 곳을 Data Warehouse 라고 한다
- Lake 에서 Warehouse 로 넘어오는 과정에서 일어나는 일들:
- 분류 작업
- 전처리
- ML / DL 등의 연산
- 위 작업을 위해 schema 작성이 필요할 수 있다.
- "당근 / 감자 / 고구마를 분류한 창고"
Data Mart
- 전처리를 거친 완벽한 상태의 데이터들이 적재됨
- 사용자가 실제로 접근하는 곳
- schema 필수
- "판매되기 위한 준비를 완료한 야채들이 진열된 상점"
Data Mart 구축
- 데이터 분석에서 우리가 중요하게 생각할 점은 aggregation 을 적용하는 것이다.
- 우리가 이용할 MySQL 에서는 groupby 를 통해 일어난다.
- 이를 위해서는 column 에 기준 정보가 중복되면 안된다
Melting
- data 를 세로 (long format) 으로 정렬

- 위 데이터는 판매 정보에 분기별 정보가 포함된 wide format
- wide format 은 분석 보다는 "보기 좋은" 데이터
- 데이터 분석의 관점에서는 wide format 은 data warehouse 가 된다
- aggregation function 적용이 용이하지 않기 때문
- aggregation 을 위해 한 column 내에 있는 기준 정보를 분리해준다
- melting 을 거치면 다음과 같게 변형된다
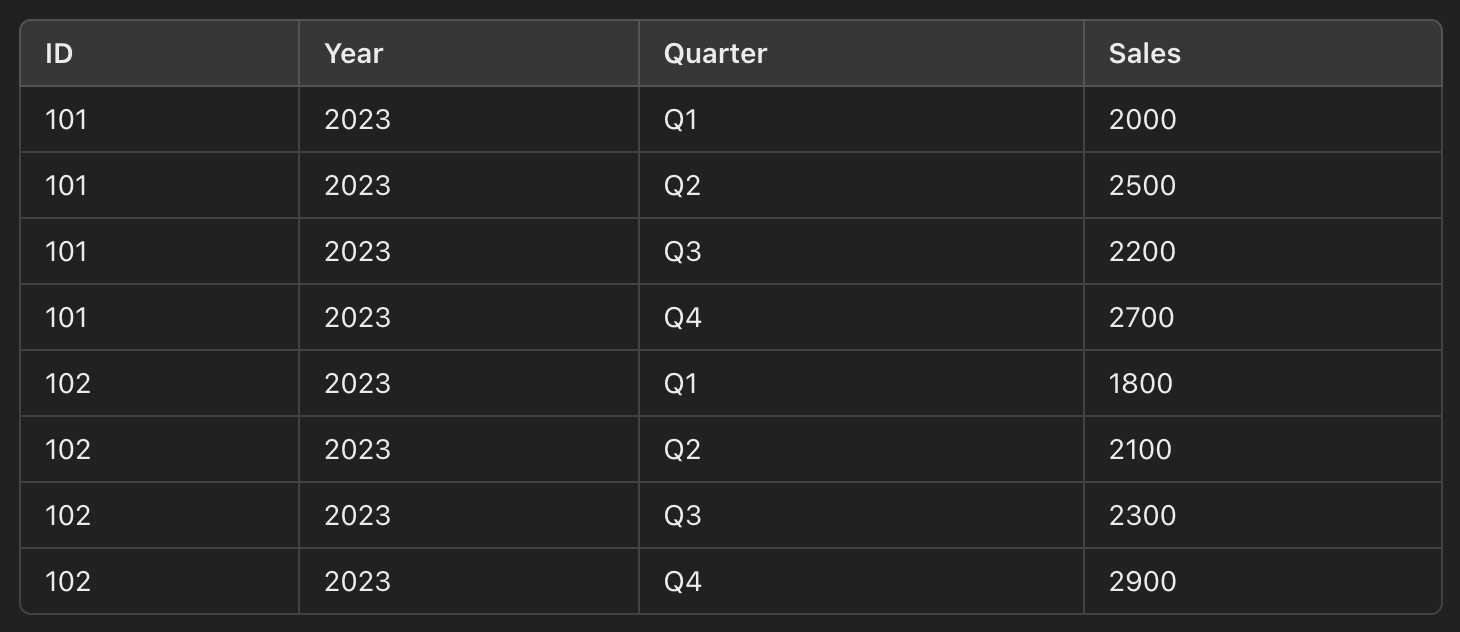
- 이제 연도별, 분기별, ID 별 aggregation 이 가능한 형태가 되었다.
- 데이터 분석의 관점에서는 long format 이 data mart 가 된다
CROSS JOIN (Cartesian Join)
- key 를 사용하지 않고, 모든 행에 대해 조합을 수행
- 중복 데이터가 많이 나온다
- 개발 목적으로는 거의 사용하지 않지만, 데이터 분석에서는 적극적으로 활용
- cartesian join 의 결과물을 case when 을 이용해 코드화를 시켜주는 것이 melting
WITH ~ AS
- subquery 는 현재 잘 사용되지 않는다. 이를 WITH~AS 로 대체한다
- 특히 from 에 들어가는 subquery 는 WITH~AS 로 대체하는 것이 좋다
- subquery 에서 조회할 결과를 미리 임시 table 형식으로 만든다
- 임시 table 이기 때문에 1회성. VIEW 와는 다르다
WITH <table_name> AS(
<subquery>
)
# 임시 table 을 만들고 이후 사용
SELECT * FROM <table_name>;
인하대학교 컴퓨터공학과