Vanishing Gradient
- 신경망을 무턱대고 깊게 만들기 시작하면 다양한 문제가 발생
- overfitting
- vainshing gradient
- loss landscape problem
- Vanishing Gradient 는 레이어가 많아질수록 매개변수들에 대한 기울기가 사라지는 문제
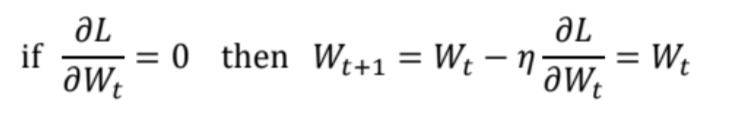
- 기울기가 0이면 학습에 의한 parameter 갱신이 일어나지 않는다.
- 작은 크기의 기울기가 반복되면 이들이 곱해지면서 신경망이 깊어질수록 기울기가 점점 "소멸"된다
- 이로 인해 학습이 제대로 되지 않고, 훈련 데이터 조차 제대로 맞추지 못하는 underfitting 발생
- sigmoid 를 활성화 함수로 이용한 경우를 살펴보자
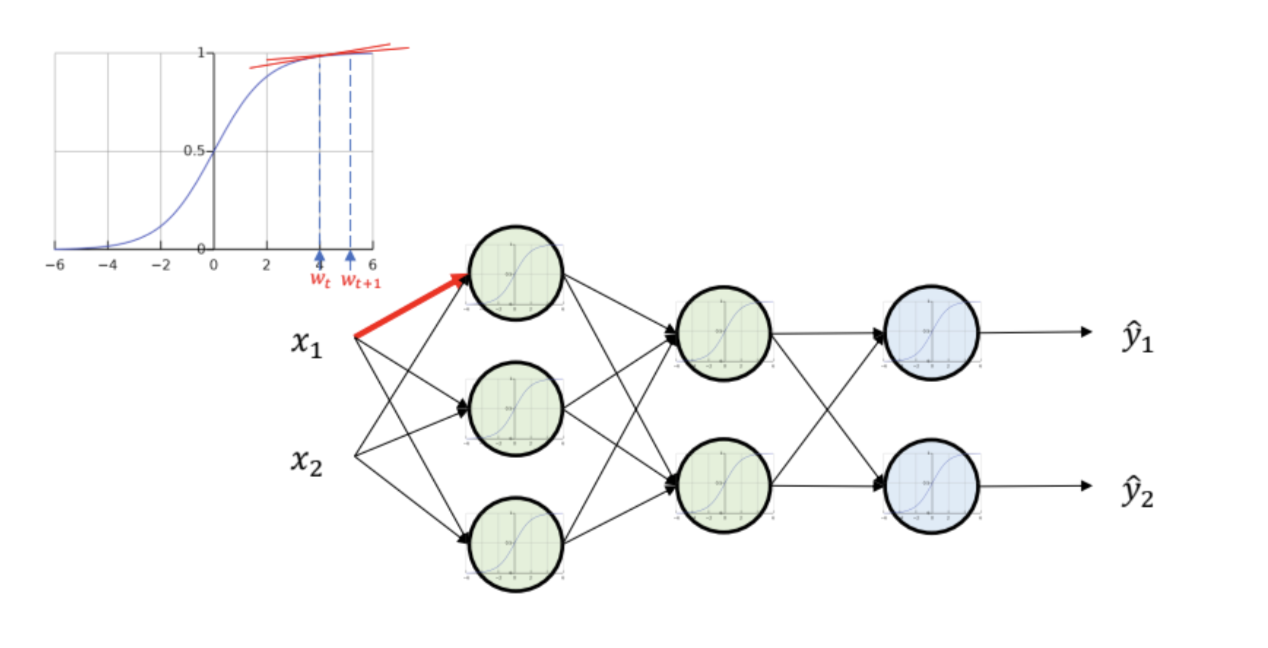
- sigmoid 의 최대 기울기는 0.25
- 역전파를 통해 도함수를 구할 때, 최대 0.25의 값이 곱해지면서 Vanishing Gradient 가 발생
- 또한, sigmoid 는 가중치가 갱신되어도 기울기가 거의 변하지 않는다
ReLU
ReLU 를 통한 기울기 소실 개선
- 앞의 sigmoid 에서 앞 층의 기울기가 너무 작아 기울기가 소실되었다
=> 기울기가 작지 않은 활성화 함수를 사용한다면? - ReLU 는 입력값이 양수면 기울기가 1이기 때문에 기울기가 0이 되는 것을 방지
- 음수가 입력되면 미분값이 0이 되긴 하지만, 양수가 입력된 쪽의 기울기와 더해지기 때문에 영향이 적다
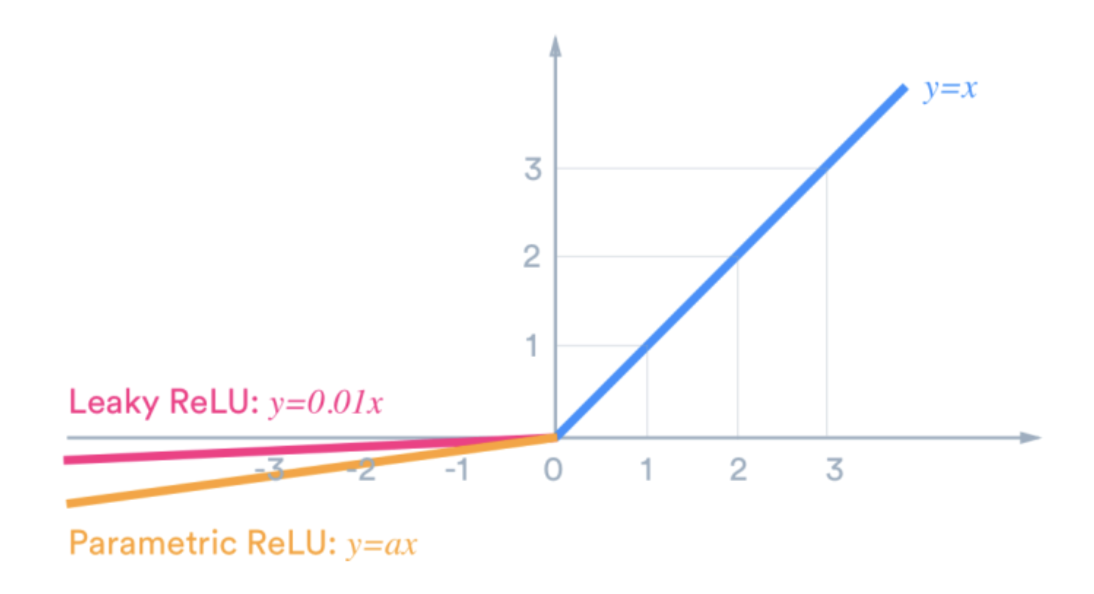
- 음수 부분의 기울기를 학습할 수 있는 ReLU 의 변형도 존재한다
Batch Normalization
- 어떤 mini batch 내의 데이터가 한 쪽으로 편향되면?
- 모두 양수라면, ReLU 의 비선형성 손실
- 모두 음수라면, ReLU 의 결과가 0이 되어 Vanishing Gradient 발생
- 이런 현상을 막기 위해, 모든 batch 들의 데이터 분포를 재배치하는 방식 이용
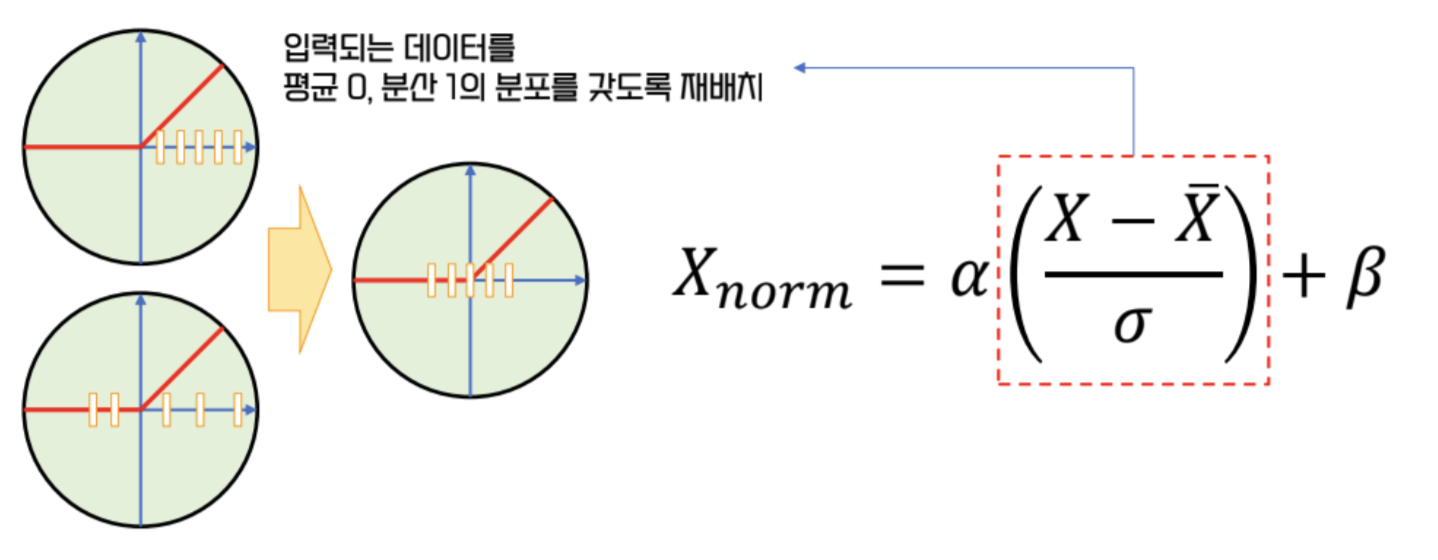
- 입력되는 데이터를 평균 0, 분산 1의 분포를 가지도록 재배치
- layer 가 많아져도 데이터 편향으로 인한 문제를 방지할 수 있다
- 비선형성을 살리면서 기울기 소실을 막을 수 있는 계수를 모델이 학습한다
- 는 분산과 관련된 계수 => 데이터가 얼마나 넓게 퍼지는가?
- 는 데이터가 재배치될 평균을 의미

인하대학교 컴퓨터공학과