Optimization
- 딥러닝 모델은 gradient descent 를 이용해 model parameter 를 최적화한다
cf) model parameter, hyperparameter 의 차이?
- model parameter : W, b 등 모델이 학습 과정에서 업데이트하는 값
- hyperparameter : 사용자가 정의해주는 값으로, 학습하지 않는다
- 하지만 일반적인 GD 는 매우 많은 파라미터들을 업데이트하기엔 힘들다
Stochastic GD (SGD)
- mini batch 내의 파라미터들을 한 번에 최적화
- 일반적인 GD 보다 훨씬 빠르게 optimization 가능
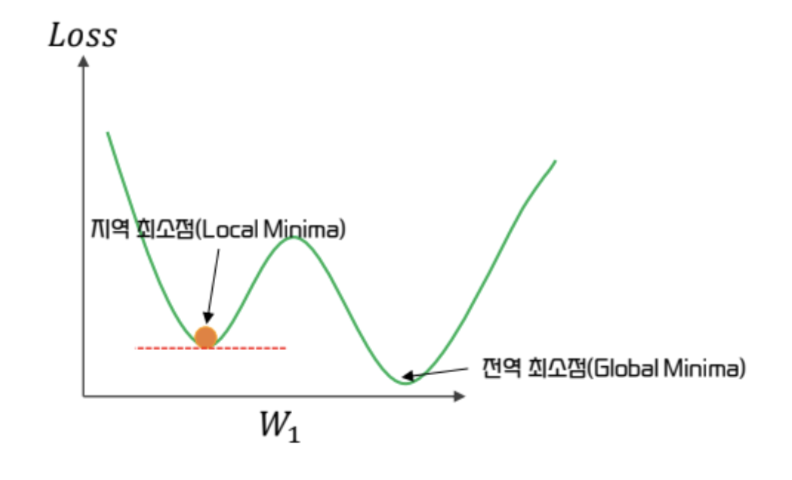
- 하지만, 일반적인 GD 와 마찬가지로 다음의 단점들이 존재한다
- 적합한 lr 을 찾아야 한다
- local minima 에 갇혀 global minima 를 찾지 못할 수 있다.
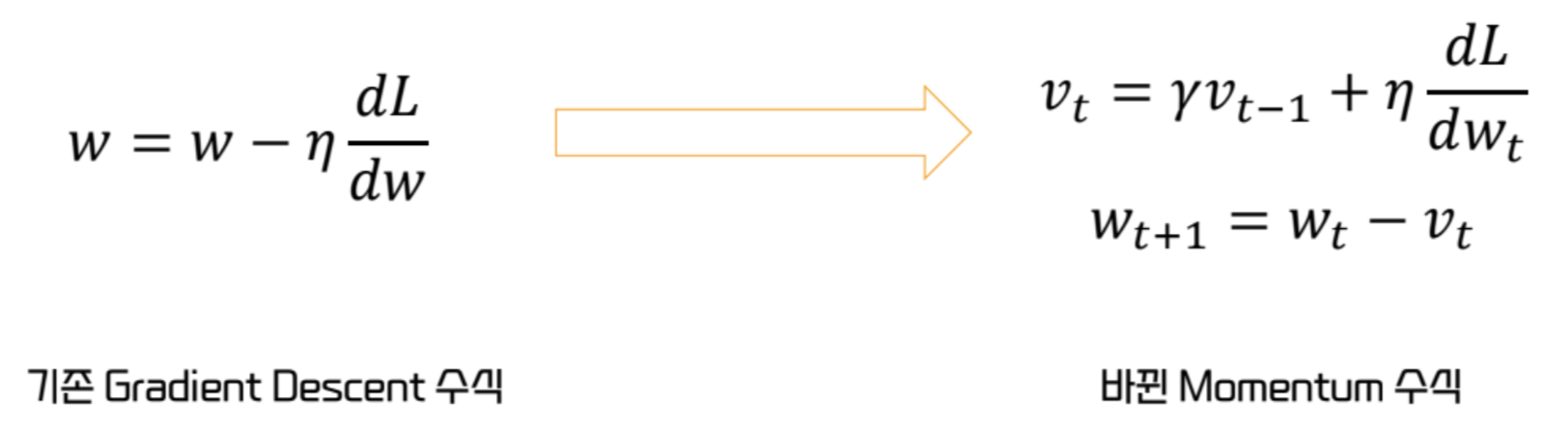
Momentum
- 가속도의 개념을 활용한 방식
- 값이 클수록, 기울기가 가파를수록 더 많은 양을 update 할 수 있도록 조치
=> 이전의 기울기 값들을 일정 수준 반영시켜 신규 가중치로 사용
- 이전 단계와 현재 단계의 기울기를 더한다
=> 같은 방향이었다면 더 많이 갱신할 수 있다
=> 하지만, 다른 방향이라면 오히려 감쇄되는 역효과 존재 - : 모멘텀 계수 => 이전 기울기를 어느 정도 잊게 해준다
- 모멘텀의 일반화 수식을 살펴보자
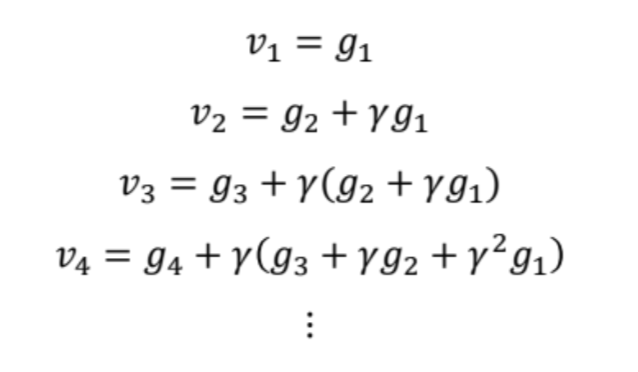
- 시간이 갈수록 앞 step 의 기울기가 미치는 영향이 점점 줄어든다
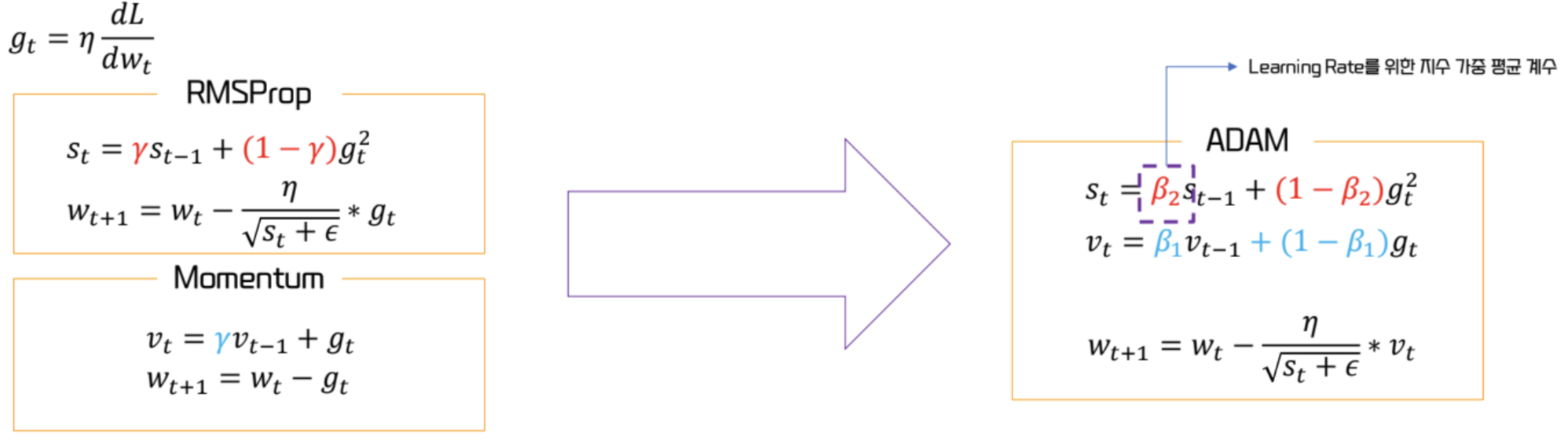
Adaptive Gradient (AdaGrad)
- 적응형 기울기를 사용
- 가중치마다 서로 다른 learning rate 를 사용
적게 변화된 가중치에는 큰 lr 적용
크게 변화된 가중치에는 작은 lr 적용

- 기울기의 부호가 아닌 크기가 중요하기 때문에 제곱을 해준다
- 는 분모가 0이 되는 것을 방지
- 분모가 양수이기 때문에 lr 은 점점 작아진다
=> lr 이 과하게 작아지면 학습이 진행되지 않는 문제 발생
RMSProp
- AdaGrad 에서 lr 이 과하게 작아지는 문제 개선
- 를 단순히 더하는 것이 아닌, 지수 가중 평균법 이용

ADAM (Adaptive Moment Estimation)

인하대학교 컴퓨터공학과