Process Concept
- process는 OS로부터 CPU 자원을 할당받아 실행중인 프로그램을 뜻한다.
- dynamic entity인 process는 static entity인 program은 가지지 않는 다음의 특징들을 보인다.
Process Address Space
- 모든 process는 address space라는 주소 공간이 반드시 필요하다.
- 이는 virtual memory 상의 해당 process를 위한 주소 공간이다.
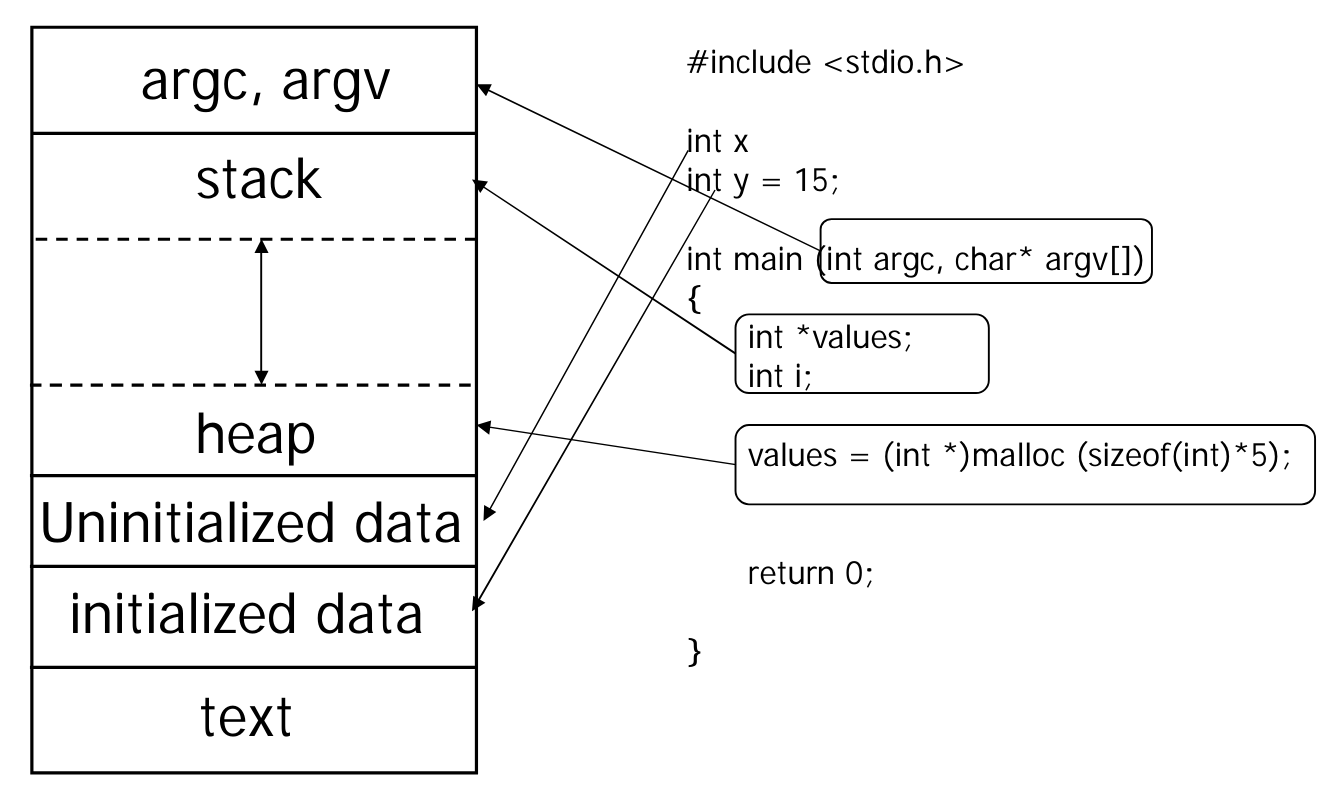
- address space의 구성 요소는 다음과 같다
- argc, argv: main 함수의 argument들이 저장된다.
- stack: local variables, parameters 저장
- heap: 동적으로 할당한 공간
==> stack과 heap의 크기는 process 실행 동안 계속해서 바뀐다. - data: global variables 저장
- text: program code 저장
Process State
- process의 상태를 나타내는 개념으로, process가 살아있는 동안 state는 계속해서 바뀐다.
- new: process가 생성된 직후의 상태
- running: CPU 자원을 할당받고 실행중인 상태
- waiting: I/O operation 요청 이후 기다리는 상태
- ready: 실행 될 준비를 완료했으나 아직 scheduler에게 선택받지 못한 상태
- terminated: 실행이 완전히 종료된 상태
-
process는 state를 전이하며 살아있는 dynamic entity이고, 전이 과정은 아래의 state diagram으로 나타낼 수 있다.

-
interrput: scheduler가 다른 process를 선택하면, 실행 중이던 process는 running에서 ready state로 전이한다. 이에 더불어, 다른 프로세스의 starvation 을 방지하기 위해 프로세스에는 timer 이 달려 있다. 이 timer 가 끝나 다른 프로세스에게 자원을 양도할 때도 running 에서 ready 로 전이된다.
-
scheduler dispatch: 위와 반대로 scheduler에게 선택되어 ready에서 running state로 전이하는 과정이다. scheduler는 ready 상태인 process 중 실행시킬 프로세스를 선택하는 역할을, dispatcher은 실제 context switching을 담당한다. 새로운 프로세스에 CPU 자원을 할당하고, 기존 프로세스의 register 값들을 해당 PCB에 저장 및 새로운 PCB 값들을 불러와 새로운 메모리에 불러온다.
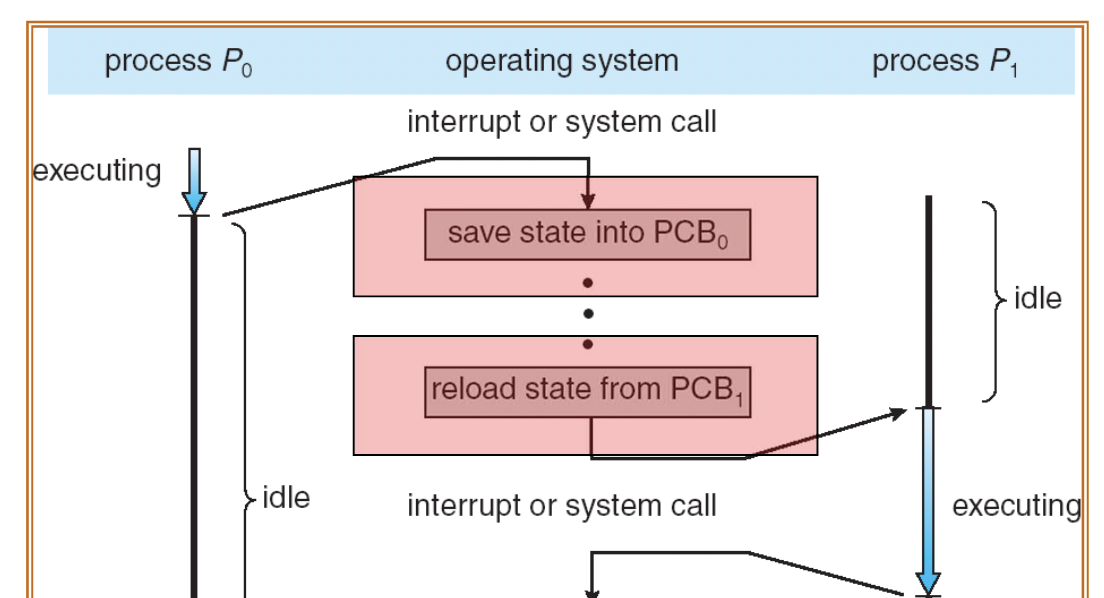
-
I/O event: I/O event가 일어나면 실행 중이던 프로세스는 waiting state로 전이되며, interrupt가 도착하면 ready state로 가 scheduling을 기다린다.
Process Control Block (PCB)
- state, program counter, register 값 등 process의 모든 정보를 담은 data structure이다.
- program counter은 실행해야 할 코드를 가리키고, register 값들은 multiprogramming에서 context switch가 일어날 때 correctness를 보장하기 위해 저장해야 한다.
- context switch가 일어나면, 실행중이던 process는 ready state로 전환되며, 그 시점의 register 값들을 저장한다. 다시 running state로 전환될 때 저장한 register 값들을 불러와 다시 사용한다.
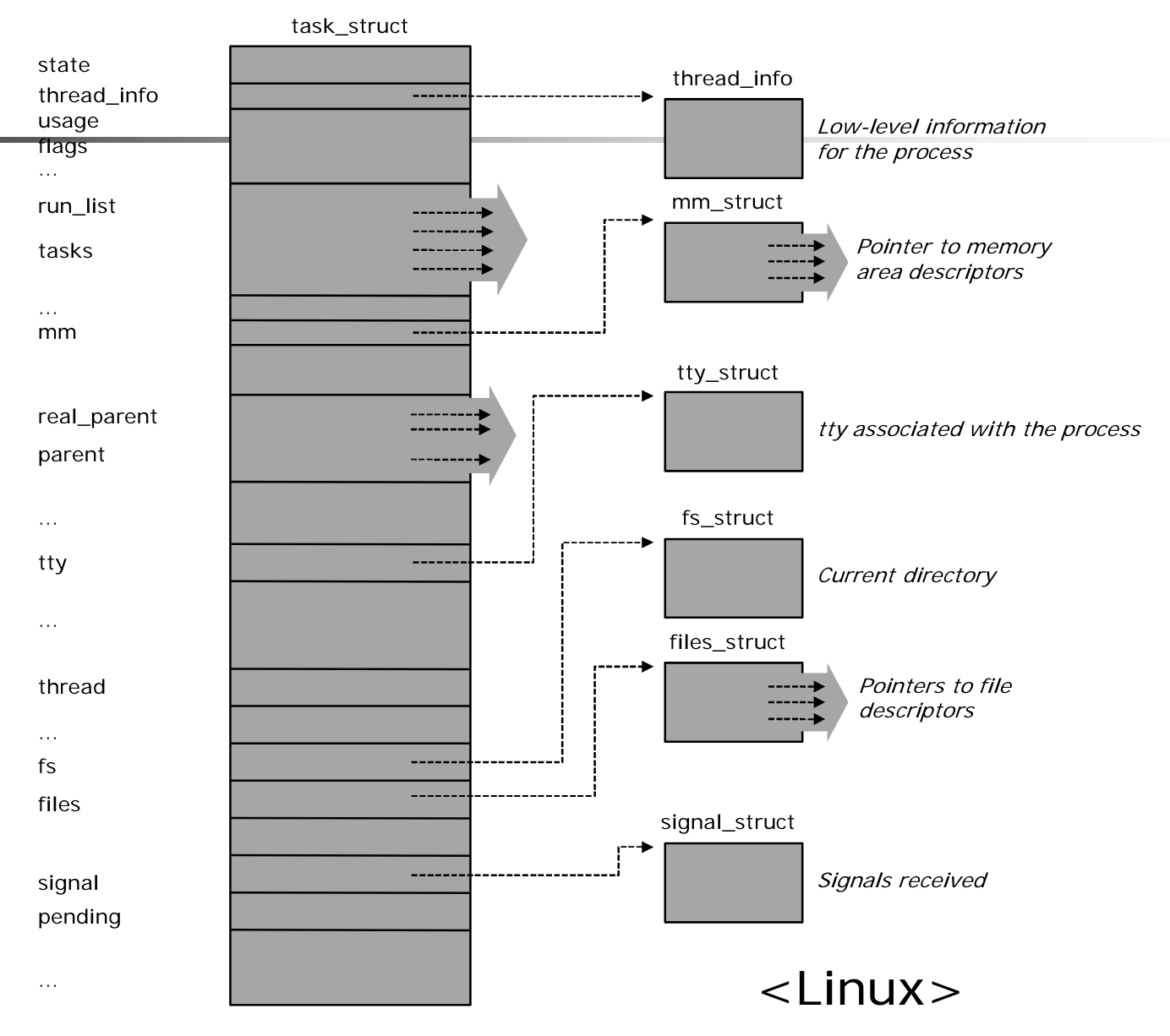
- 다음은 LINUX의 PCB인 process descriptor이다.
- thread_info: register 정보를 비롯한 하드웨어 연관 정보들을 담는다.
- mm_struct: page table에 접근하여 address space 내의 정보를 확인하는 포인터를 담는다.
- fs_struct: 현재 열려있는 파일들의 정보를 담는다.
Process Scheduling
- Process Scheduling은 queue에서 대기중인 프로세스 중 하나를 선택해 실행시키는 작업이다.
Process scheduling queue
- 프로세스들이 대기하는 queue에는 세 가지 종류가 있고, scheduler의 종류에 따라 참고하는 queue가 다르다.
- Job Queue: 모든 프로세스들이 대기하는 곳이다. 이를 참고하는 작업은 job scheduling 으로, main memory에 load해 ready queue에 올릴 프로세스를 선택하는 것이다. 다만, 현재는 프로세스를 고르지 않고 모든 프로세스를 다 실행하기 때문에 의미가 퇴색됐다.
- Ready Queue: ready 상태인 프로세스들이 대기하는 곳이다. 이를 참고하는 작업은 CPU scheduling으로, 우리가 흔히 말하는 scheduling 이다.
- Device Queue: I/O operation을 실행하기 위해 대기중인 프로세스들이 모인다.
- 프로세스들은 실행되는 동안 위의 queue들을 이동한다.
I/O bound & CPU bound
- 그렇다면, scheduler은 어떤 프로세스에게 우선권을 줄까?
- 프로세스는 아래의 두 종류로 분류될 수 있다.
- I/O bound: CPU 연산보다 I/O operation이 많은 프로세스다.
- CPU bound: 반대로 I/O operation보다 CPU 연산이 많은 프로세스다.
- I/O bound process는 상대적으로 짧은 CPU burst (data를 주고 받는 대기시간)을 가진다. 이로 인해 CPU를 더 짧게 사용하고, 더 많은 process를 실행시키기 위해 scheduler는 I/O bound process를 우선적으로 선택한다.
Schedulers
- 앞서 설명한 것 처럼 scheduler들은 다음의 세 종류로 구분된다.
- Long term scheduler (job scheduler)
- main memory에 load해 ready queue에 올릴 프로세스를 선택하는 작업이다. long term 이기 때문에 긴 주기를 가지고 실행된다.
- 최종적으로 실행시킬 프로세스의 수를 결정하는 역할을 한다 (controls the degree of multiprogramming). 너무 많은 프로세스를 실행시키면 시스템이 불안정해지기 때문에, 이는 system stability와 직결된다.
- 하지만, 요즘은 프로세스를 전부 실행시키고, 여력이 되지 않는다면 process kill을 하는 방식으로 진행되기 때문에 의미가 퇴색되었다.
- Short term scheduler (CPU scheduler)
- 우리가 흔히 말하는 scheduler로, ready queue에서 다음으로 실행될 프로세스를 선택한다.
- 아주 짧은 주기로 실행되기 때문에, 반복문 등을 포함하지 않는 간단한 코드로 구현되어야 한다.
- Medium term scheduler
- swapping 을 결정하는 scheduler 이다. 프로세스를 실행하다가 CPU 자원이 부족하면 (memory가 꽉 차면) 어떤 프로세스들을 main memory 에서 swap in / swap out 할지 결정한다.
Context Switch
- scheduler에 의해 실행중인 프로세스가 바뀌는 것을 context switch라고 한다.
- context switch가 일어나면, 새로운 프로세스에 CPU 자원을 할당하고, 기존 프로세스의 register 값들을 해당 PCB에 저장 및 새로운 register 값들을 불러와 새로운 PCB에 불러온다.
- 하지만 이 과정은 유효한 일은 아니기 때문에, overhead 로 간주된다. 그러므로 다음의 방법들을 통해 context switching 의 overhead 를 줄이는 것이 관건이다.
- starvation 이 일어나지 않는 선에서 context switch 자체의 횟수를 줄인다. (OS level 의 해결법)
- SUN UltraSPARC architecture 활용 : context switch 과정에서 많은 수의 레지스터를 이용한다. 레지스터가 많아지면 main memory 접근 필요성이 줄고, PCB에 load / save 하는 과정이 간소화 될 수 있기에 overhead 가 감소한다.
- ARM architecture 활용 : ARM 은 multiple load / store 명령어를 제공한다. 이를 통해 여러 번의 연산을 하나의 명령어 처리할 수 있어 속도가 빠르다.
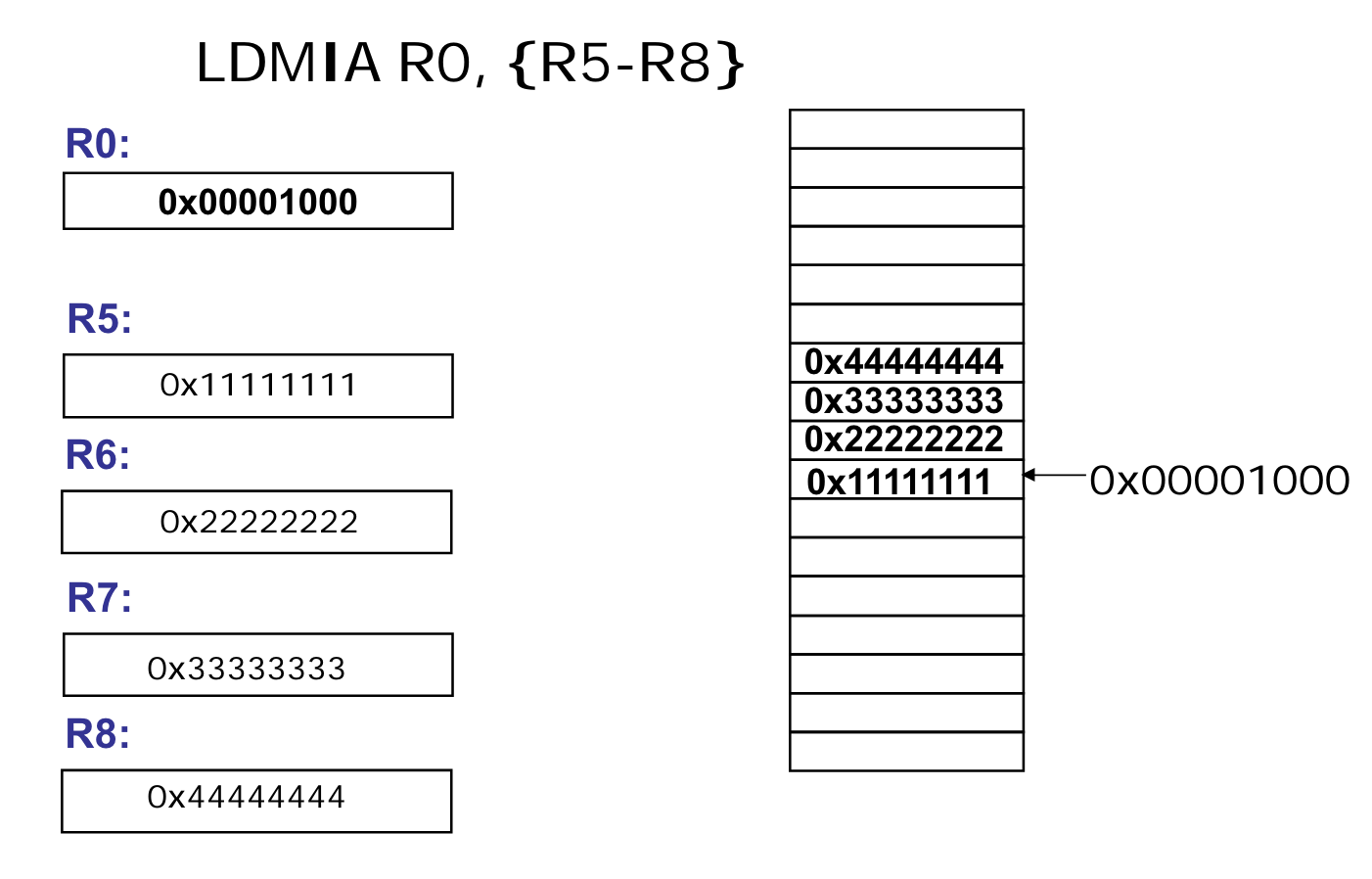
위 그림에서 하나의 명령어로 4개의 레지스터 값을 한 번에 불러올 수 있다. ARM 이 아니었다면, 각각의 값에 대해 하나씩의 명령어가 필요했을 것이다.
Operation on Processes
Process Creation
- 프로세스는 parent process 에서 호출된 fork()에 의해 생성된다. 이로 인해 트리 형태의 tree of processes 가 형성된다.
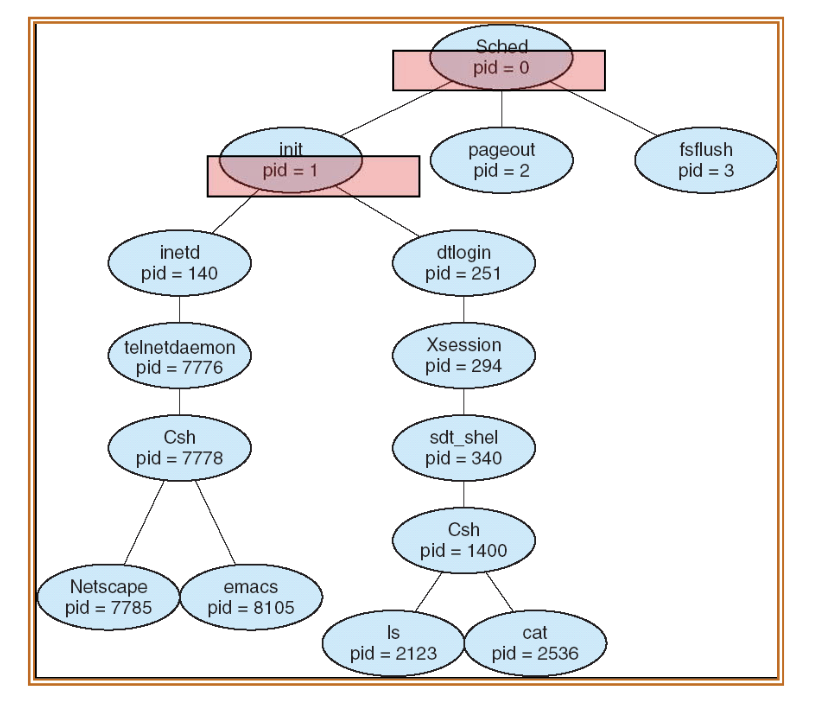
- 이 때, 부모와 자식은 별도의 프로세스로 구분되며, 각각의 프로세스는 process ID (PID) 로 구분된다.
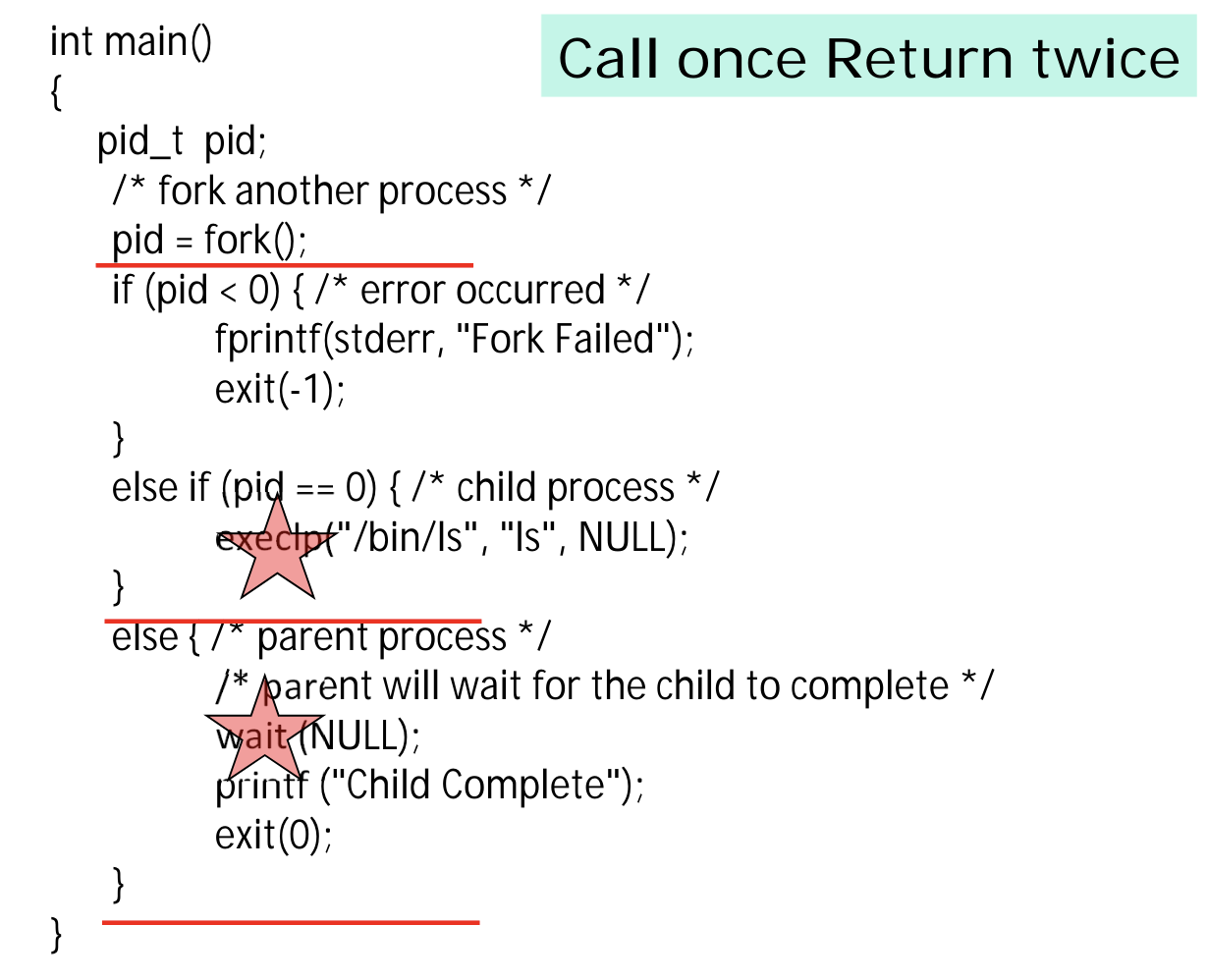
- fork()는 부모와 자식을 구분하기 위해 두 개의 return 값을 가진다. 하나는 부모의 PID, 다른 하나는 자식의 PID다. 이를 "Call once, return twice" 라 한다.
- 프로세스가 생성될 때는 다음의 특징들을 가진다.
- 자식 프로세스는 부모의 자원 중 일부분을 공유 받는다. 부모가 연 파일 등은 공유 받지만, 별개의 프로세스이기 때문에 PCB 등은 각자 가진다.
- 기본적으로 부모와 자식은 concurrently 수행된다. 하지만, 자식이 terminate 될 때까지 부모가 기다리는 경우도 있다. 이 경우 parent 에서 wait()을 호출하고 waiting state로 전이되며, 부모의 program counter 가 wait() 에서 대기한다. 이때, 자식이 terminate 됐는데도 부모가 wait()을 종료하지 않으면 (child not reaped by the parent), 자식은 zombie process 가 된다.
- 생성 직후, 자식은 부모의 address space 를 복제해 온다. 별도의 프로세스이기 때문에, 공유하는 것은 아니고, 복제본일 뿐이다. 복제 이후 자식에서 exec() 을 호출해, 자신이 하고자 하는 일의 코드를 불러와 text area 에 덮어쓴다.
Process Termination
process termination 은 방법에 따라 두 가지로 분류될 수 있다.
1. exit
- 프로세스가 마지막 명령어를 수행하고, OS 에게 종료를 요청하는 자발적 termination 이다.
- 프로세스가 terminate 되면, OS 에서 할당한 자원을 회수하고, 해당 프로세스의 부모에게 메시지를 전송한다.
- abort
- 부모에 의해 강제적으로 종료되는 타의적 termination 이다.
- 자식이 할당된 자원보다 더 많은 자원을 사용하려고 하거나, 자식이 하는 일이 더 이상 필요하지 않을 때 일어난다.
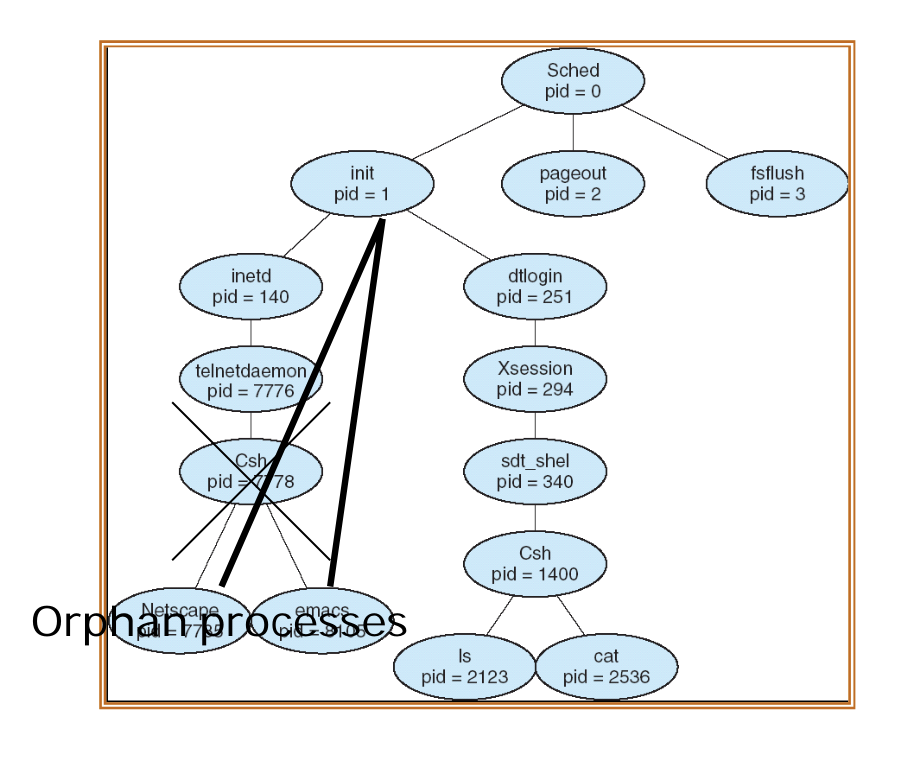
어떤 프로세스가 abort 되면, 그 자식들은 어떻게 될까? OS 에 따라 두 가지 처리 방식이 있다.
1. Cascading Termination (계단식 종료) : 부모가 종료되면 자식의 실행을 허용하지 않는 OS 에서 사용한다. 부모부터 마지막 자식까지 순차적으로 종료된다.
2. Orphan Process : 부모가 종료 되어도, 자식의 실행을 허용하는 경우이다. 말 그대로 부모가 없는 프로세스가 생기는 것이다. 이 경우, tree of processes 구조를 유지하기 위해 아래의 그림처럼 위쪽의 init process 를 orphan process 의 부모로 할당한다. Zombie process 와 다른 점을 주의깊게 봐두자.
Inter process Communication (IPC)
- 프로세스끼리 정보를 공유해 cooperating process 가 되면, 여러 장점들이 있다.
- 파일 시스템, 데이터베이스 접근 또는 메모리 공간 등의 정보 공유
- 여러 프로세스가 특정 작업을 분담하여 병렬로 수행함으로써, 시스템의 전반적인 성능과 처리량을 향상
- cooperating process 를 만들기 위해서는, 프로세스 간의 communication 이 필요하다. 이때, 다른 프로세스의 address space 를 직접 접근할 수 없으므로, kernel 의 도움을 받아 communication link 를 만들어야 한다.
Shared Memory
- 프로세스들이 공유 memory 공간에 read / write 를 하며 IPC를 수행하는 방법이다.
- 서로 다른 프로세스의 공간에 접근하는 방법으로 kernel의 도움을 받아 일부 영역을 open 해 공유하는 것이다.
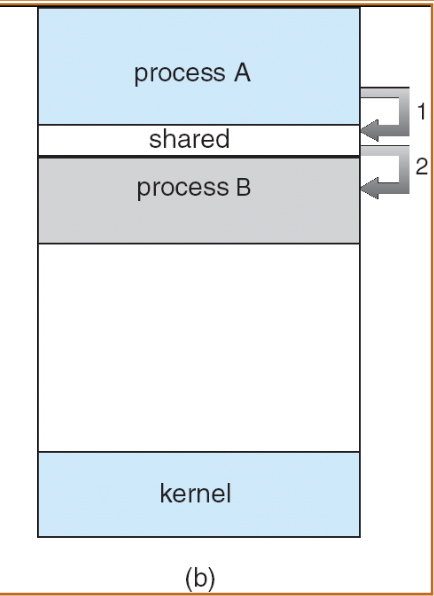
- process B 가 shmget() 을 호출해 공유 영역을 만든다.
- process A 가 shmat() 을 호출해 공유 영역을 자신의 address space 에 추가한다.
- A와 B는 shared region 위에서는 서로가 write 한 정보를 read 하며 IPC 를 수행한다.
- shmdt() 를 호출하면 shared region이 address space 에서 detach 된다.
- 위에 등장한 함수들은 system call 이다. Shared memory 기법에서는 shared memory 에 관한 작업을 수행할 때 system call 이 필요한 것이다. 다시 말해, read 와 write 시에는 system call 이 필요 없다.
Producer-Consumer Problem
- producer 은 정보를 생산하는 쪽, consumer 은 producer 가 생산한 정보를 받아 소비하는 쪽이다.
- shared memory 이용 시 둘 간의 synchronization 이 있어야 안정적으로 정보를 주고받을 수 있다.
- synchronization 기법 중 가장 흔하게 이용되는 것에는 spin lock 이 있다.
Spin Lock
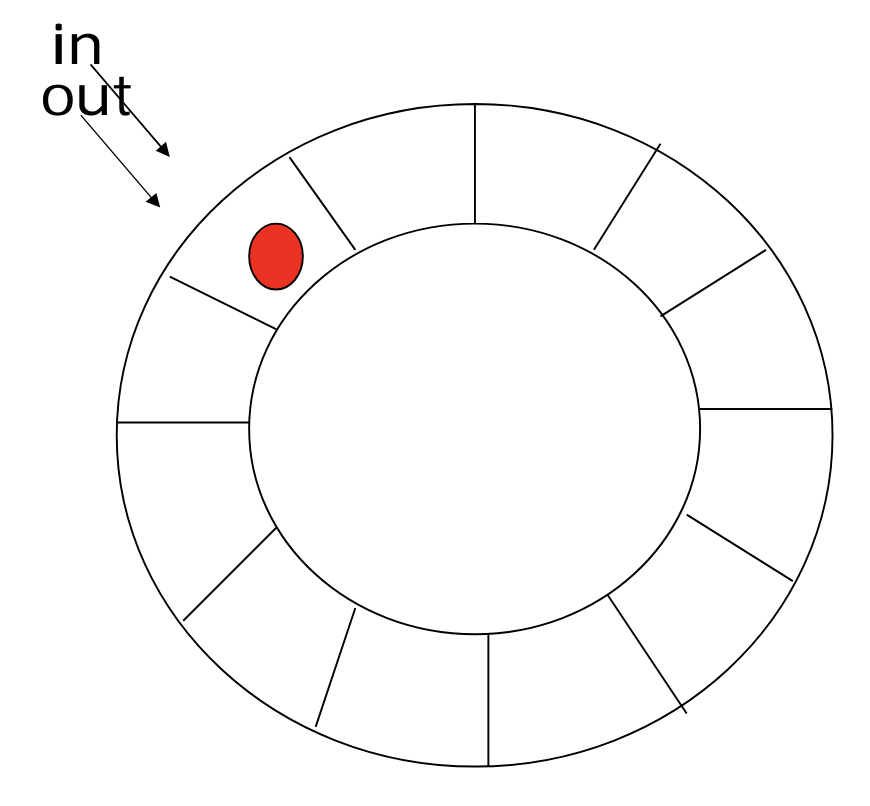
spin lock 은 while loop을 이용한 synchronization 기법이다.
- producer 와 consumer 의 동기화를 위해 생산되고 소비될 정보를 담는 buffer 라는 공유 공간을 만든다.
- buffer 에는 두 개의 포인터가 있다. 비어있는 첫 위치를 가리키는 in 과, 채워져 있는 첫 위치를 가리키는 out 이다.
#DEFINE BUFFER_SIZE 10 // 크기가 10으로 제한된 bounded buffer
typedef struct{
...
} item; // item이라는 이름의 data 구조체
item buffer[BUFFER_SIZE]; // 환형 배열로 buffer 구현
int in = 0;
int out = 0; // 두 포인터의 위치 초기화- 위 코드는 초기 설정으로, 크기 10의 buffer 를 선언하고, 두 포인터의 위치를 0으로 초기화한다.
- buffer 에 data 가 들어오고 나갈 때마다 포인터를 이동시키며 작동한다. 이때, 신경써야 할 조건이 두 가지가 있는데, buffer 가 empty 일 때와 full 일 때다.
- empty 라면 소비할 data 가 없으므로 consumer 를, full 이라면 받을 공간이 없으므로 producer 를 대기시켜야 하는데, 여기서 while loop 을 이용하는 것이다.
//producer
while (true){
while (((in + 1) % BUFFER_SIZE) == out)
// 환형 배열로 구현된 buffer이 full 인 상태
; // while loop 내에선 아무것도 수행하지 않고 lock
buffer[in] = item; // lock을 벗어나면 buffer에 다시 item을 삽입
in = (in + 1) % BUFFER_SIZE; // in 위치 한 칸 이동
}
//consumer
while (true){
while (in == out)
// 두 포인터가 일치할 때이므로 empty 상태
; // while loop 내에선 아무것도 수행하지 않고 lock
item = buffer[out]; // lock을 벗어나면 buffer에서 item을 꺼내 소비
out = (out + 1) % BUFFER_SIZE; // out 위치 한 칸 이동
}- producer 와 consumer 의 코드에 각각 body 가 비어 있는 while loop 이 하나씩 있다. 조건이 만족되는 동안 다음 command 가 실행되지 않고 while loop 을 반복하면 소위 lock 이 걸리는 것이다. 이때, 코드 자체는 실행 중이기 때문에 lock 상태이더라도 running state 에 있다.
Message Passing
- shared memory 와는 달리 공유 자원 없이 IPC 를 수행하는 방법이다.
- read 와 write 대신 지속적인 호출이 필요한 send 와 recieve 를 사용한다.
- 일반적으로 logical communication link 를 이용한다.
- 두 가지 방식이 있다.
- Direct Communication
- 두 프로세스가 1대1로 직접 연결되는 방식이다.
- 1대1 연결이기 때문에 서로의 PID를 명시해야 한다.
- PID 를 명시하면 link 가 자동으로 생성된다는 장점이 있지만, 상대의 PID 를 미리 다 알아야 하고, 이를 코드에 포함시켜야 한다는 점이 번거롭다.
- Indirect Communication
- kernel 내에 생성되는 mailbox 라는 자료구조를 이용해 IPC 를 지원하는 방법이다. mailbox 가 communication link 의 역할을 하는 것이다.
- 상대의 PID 대신 mailbox 의 주소를 명시한다.
- mailbox 공유에 성공만 한다면 link 가 생성되어 자유도가 높지만, 구현에 여러 issue 가 있다.
Mailbox Sharing Issues
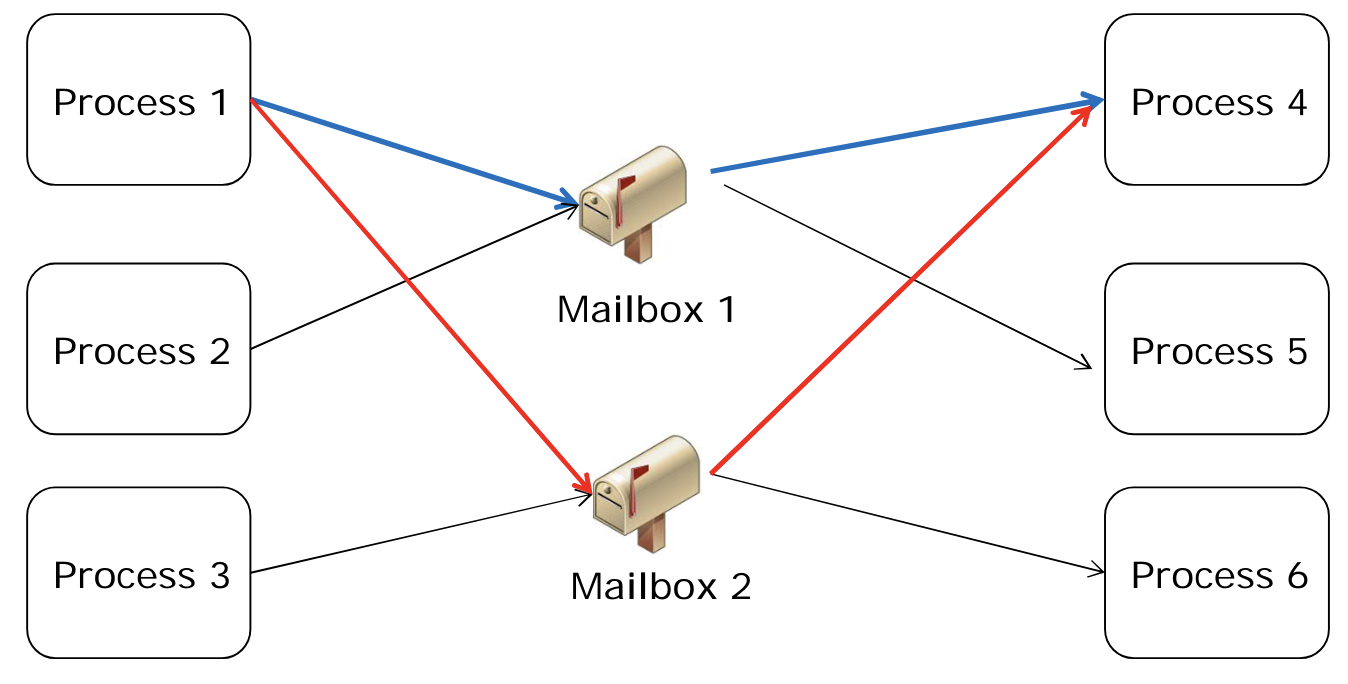
- 하나의 mailbox 가 여러개의 프로세스와 연결될 수 있다. 그림에서는 mailbox 1이 process 1, 2, 4, 5와 연결되고, 이들 사이에서 자유롭게 link 생성이 가능하다.
- 한 쌍의 프로세스에 여러 개의 link 가 생성될 수 있다. process 1 과 4 사이에는 파란색과 빨간색 link 가 있다.
- 이런 특성으로 인해 구현 시 문제가 발생할 수 있다. process 1 이 mailbox 1에 메시지를 보내면, 4와 5가 이를 수신할 수 있다. 만약 두 프로세스가 동시에 수신을 시도한다면, 메시지는 어디로 가야 할까? 이에 대한 해결책은 다음과 같다
- 한 link 가 최대 2개의 프로세스와 연관될 수 있도록 제한하기
- Broadcasting : 수신을 시도한 모든 프로세스가 메시지를 받을 수 있게 한다.
- 한번에 한 프로세스만 받을 수 있도록 허용한다.
- sender 로 하여금 reciever 를 선택할 수 있도록 한다. 이는 direct 와 indirect communication 을 합친 방법이다.
- 응용 프로그램이 위의 option 중 하나를 선택할 수 있도록 kernel 이 primitive 를 준다.
Mailbox Synchronization
- message passing 은 sender, reciever가 block 되어 있는지 여부에 따라 blocking, non-blocking 의 두 가지 옵션이 있다.
- programmer 가 둘 중에 선택할 수 있도록 kernel 이 primitive 를 준다.
- blocking send : 메시지가 mailbox 또는 reciever 에 도착할 때 까지 send() 실행 시점에서 block 되어 다음 line 을 실행하지 않고 대기한다.
- non-blocking send : 메시지 도착 여부와 상관 없이 다음 line 수행
- blocking recieve : blocking send 와 같은 맥락이지만, sender 이 아닌 reciever 가 waiting state 로 전이한다. 메시지 도착 시 ready state 로 간다.
- non-blocking recieve : 메시지 도착 여부와 상관 없이 다음 line 수행
- blocking send/recieve 는 메시지가 도착해야 다음 line 을 수행하기 때문에 synchronous, 반대로 non-blocking send/recieve 는 asynchronous 한 것으로 간주된다.
- synchronous 는 작업들이 순서대로 실행되며, 한 작업이 완료된 후에 다음 작업이 시작되는 방식을 의미한다.
지금까지 살펴본 IPC 방법들을 비교하면 다음과 같다
| message passing | shared memory | |
|---|---|---|
| communication link | kernel 내의 mailbox | shared memory space |
| system call | data 전송, mailbox 생성 시 | shared memory 관련 작업 시 |
| synchronization | kernel 에서 지원 | spin lock 을 비롯한 method 필요 |
