RNN structure
- RNN 은 보통 시계열 데이터를 학습하고 예측하기 위한 알고리즘이다.
- 단어의 등장 순서가 바뀌면 문장의 의미도 바뀌기 때문에, 문장도 시계열 데이터라고 볼 수 있다.
- 순서 개념이 없는 FCN 과 달리, RNN 은 cell 이라는 구조를 이용해 시간적인 정보를 유지한다.
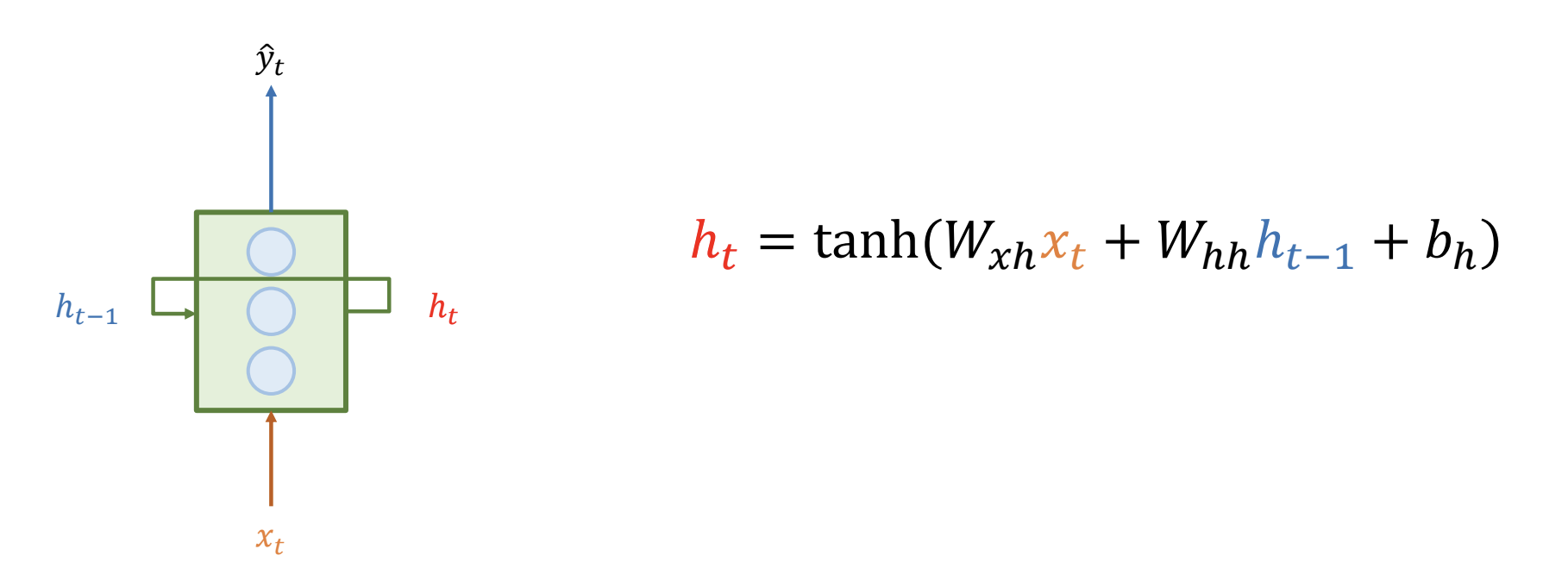
- cell 에는 FCN 과 유사한 역할을 하는 hidden unit 이 존재한다
- hidden unit 은 단어에 대해 모델이 이해한 정보의 요약이다
- 즉, "어떤 단어에 대한 생각" 에 비유할 수 있다.
- cell 은 두 개의 입력을 받는다
- : 현 시점의 입력값
- : 이전 시점의 hidden state
- 이들을 통해 두 개의 출력값이 나온다
- : 현 시점의 hidden state
- : 현 상태의 결과
- RNN 에서는 위 사진과 같은 연산이 이루어진다
- : 현 시점의 입력값과 곱해지는 가중치
- : 이전 시점의 hidden state 와 곱해지는 가중치
- : hidden unit 의 bias
- 위 과정은 하나의 cell 에서 timesteps 만큼 반복된다
Numpy 를 통한 RNN 동작 과정 이해
- cell 정의
import numpy as np
# RNN이 몇 번 펼쳐질 것인가? => 문장의 길이
timesteps = 10 # 문장의 길이 t
# RNN의 입력. 일반적으로는 단어의 벡터 차원
input_size = 4 # 단어의 차원 D
# RNN cell에서 hidden unit의 갯수 (cell 용량)
hidden_size = 8- 입력 데이터 및 hidden state 정의
# RNN 입력 데이터 (projection layer)
inputs = np.random.random((timesteps, input_size)) # D x t
# hidden state
hidden_state_t = np.zeros((hidden_size,)) # h_0 = 0- cell 뉴런의 가중치 정의
W_x = np.random.random((hidden_size, input_size))
W_h = np.random.random((hidden_size, hidden_size))
b = np.random.random((hidden_size,))- RNN 작동
total_hidden_states = []
# RNN 작동
# 단어 벡터 하나씩 순서대로 꺼낸다
for input_t in inputs:
# output_t 가 실제로는 h_t 의 역할 (현 시점의 hidden state)
output_t = np.tanh(W_x @ input_t + W_h @ hidden_state_t + b)
# 각 시점의 은닉 상태의 값을 계속해서 기록
total_hidden_states.append(list(output_t))
hidden_state_t = output_t
# 출력 시 값을 깔끔하게 만들어줌
total_hidden_states = np.stack(total_hidden_states, axis=0)
print(total_hidden_states)>>> [[0.57233133 0.83320468 0.62405135 0.5563321 0.73192675 0.75505076
0.76346329 0.60714161]
[0.99970929 0.99934681 0.9984037 0.99568118 0.99852231 0.99908636
0.99948534 0.99836627]
[0.99996845 0.99974602 0.99983944 0.99857436 0.99958013 0.99974239
0.99980824 0.99979578]
[0.99998353 0.99992415 0.99991764 0.99967546 0.99969424 0.99987357
0.99983488 0.99987852]
[0.99997063 0.99985376 0.9999276 0.99925842 0.99982861 0.99987391
0.99987287 0.99986328]
[0.99996383 0.99974692 0.99985283 0.99863859 0.99954205 0.99976828
0.99978305 0.99979495]
[0.99998859 0.99992327 0.99991825 0.99944892 0.99989465 0.99988418
0.99994144 0.99990164]
[0.99998844 0.99994257 0.9999174 0.99947613 0.99985617 0.99991842
0.99993841 0.99990751]
[0.99998721 0.99991942 0.99992409 0.9995987 0.99986405 0.99986662
0.99991239 0.99989391]
[0.99998451 0.99989823 0.99988029 0.9995821 0.99958533 0.9998003
0.99980867 0.99985471]]Deep RNN
- RNN layer 가 여러 겹 쌓인 구조
Bidirectional RNN
- 순방향과 역방향 두 개의 RNN을 결합하여 시퀀스 데이터를 처리
- 입력 시퀀스의 과거 및 미래의 정보를 모두 활용하여 더 풍부한 정보 제공
BPTT (Back Propagation Through Time)
- RNN 의 오차역전파 방식
- RNN 은 하나의 cell 의 hidden unit 들에 대한 가중치를 업데이트 해야 한다.
- 각 timestep 별 기울기를 따로 저장했다가, 하나의 가중치를 업데이트 해야 한다.
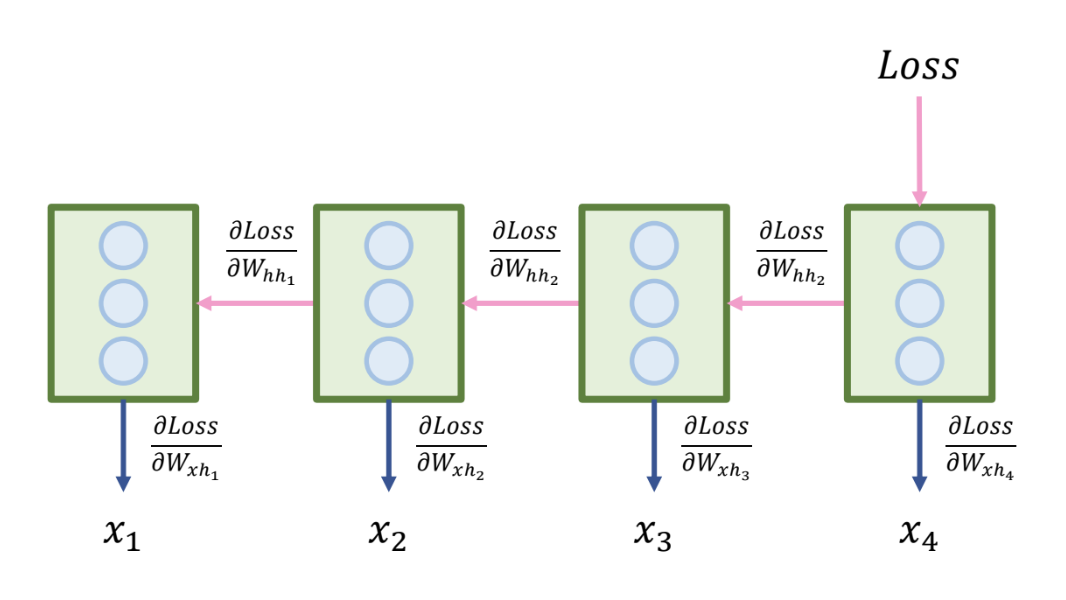
- 업데이트 할 가중치는 하나이기 때문에 각 timestep의 기울기를 평균 또는 합계를 낸다.
Truncated BPTT
- 시퀀스가 너무 길어지면 연산량이 매우 많아진다
- 이를 극복하기 위해 timestep을 쪼개서 하나의 단위를 만들고, 단위마다 가중치를 평균낸다.
- 하지만, RNN 은 를 사용하기 때문에 시퀀스가 길어지면 vanishing gradient 가 불가피하다
LSTM
- 앞의 sequence 에 중요한 정보의 소실을 해결하기 위한 방식
- gate 를 이용해 현 시점과 이전 시점의 상태를 관리
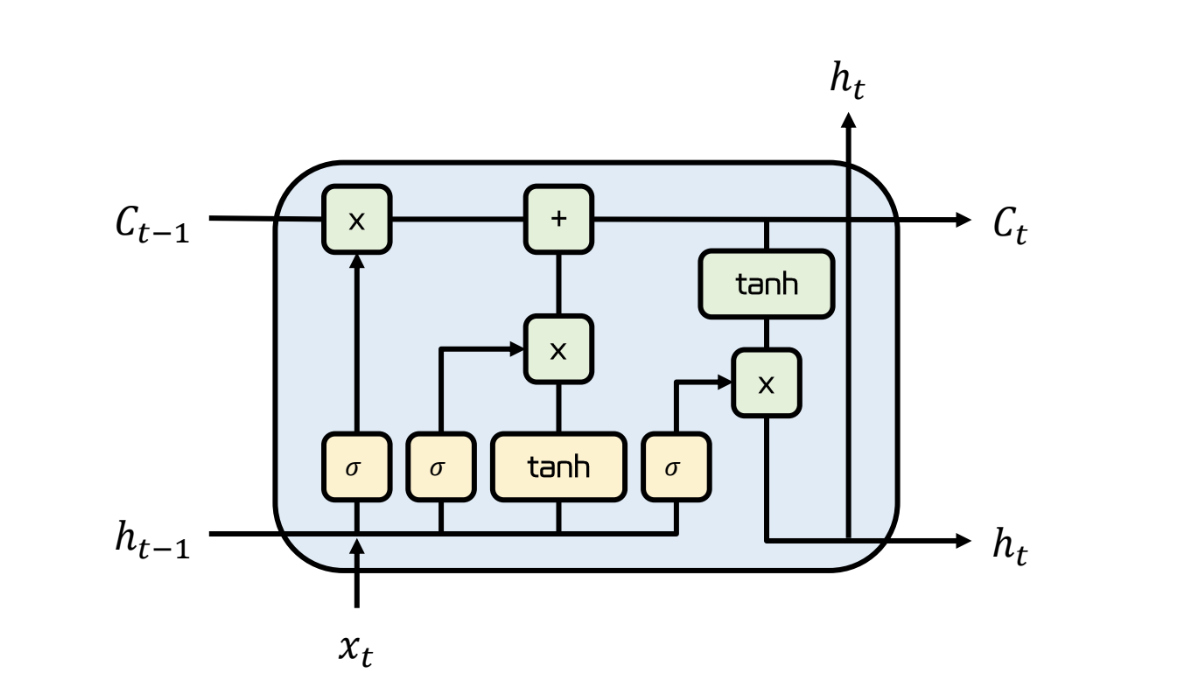
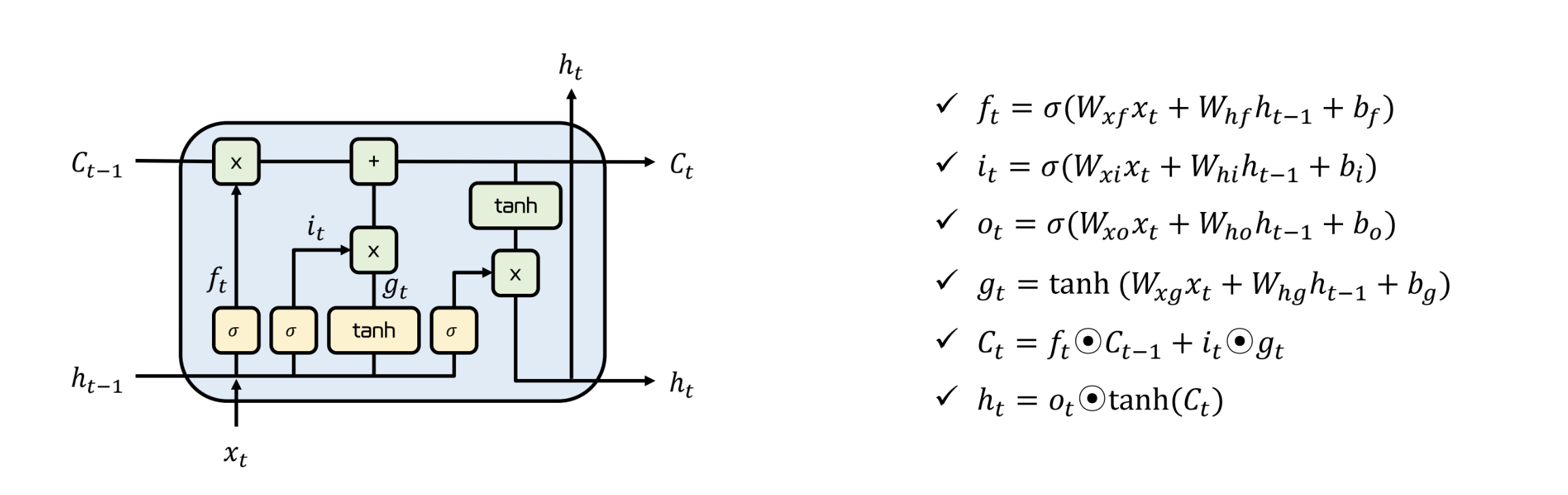
Forget Gate
- 이전 시점의 정보를 얼마나 잊을지 결정
이 고기는 맛있지만, 이븐하게 익지 않았다
- 쉼표 이전의 의미는 긍정이지만, 문장 전체는 부정의 의미를 갖는다
- 그러므로, 반전 이전의 정보는 어느정도 잊어야 한다.
- 이를 위해 sigmoid 가 이용된다
- 값이 0에 가까울수록 이전 정보 을 많이 없애고, 1에 가까울수록 많이 기억한다
- 이는 와 값을 곱함으로서 구현된다
Input Gate
- 현 시점에 대한 입력 에 대한 정보를 얼마나 반영할지 결정
- forget gate 와 마찬가지로 sigmoid 함수를 지난다
Cell State
- 기억을 총괄하는 메모리의 역할 : 잊을 건 잊고, 보관할 건 보관
- RNN 의 hidden state 와 유사한 역할
- Hadamard 연산에 의해 특징 별로 기억하고, 잊고, 새로운 정보를 받을 수 있다.
- Hadamard 연산 : 벡터의 각 원소끼리 곱하는 연산, 결과도 벡터
Output Gate
- cell state 에서 어느 특징을 출력할지 결정하는 역할
- 위와 마찬가지로 sigmoid 를 거친다

인하대학교 컴퓨터공학과