- 컴퓨터는 텍스트를 이해할 수 없다
- 그러므로 숫자 형식으로 텍스트를 변환해주어야 한다
- 보통 단어, 문자, subword 를 숫자로 표현해준다
Integer Encoding
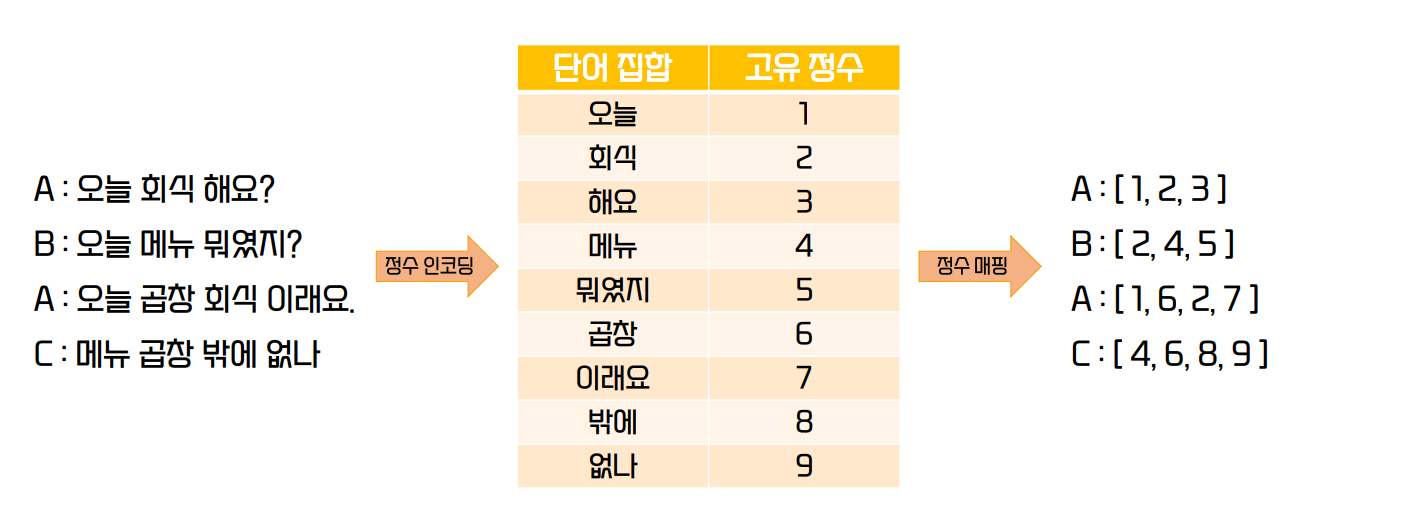
정수 인코딩과 단어 집합
- 컴퓨터가 이해할 수 있는 단어 집합 (사전)을 생성
- 집합이기 때문에 중복을 허용하지 않고 순서가 없다
- 정수 인코딩은 단어 집합의 단어들에 정수값을 부여한다
- 단어 집합 생성의 예시를 살펴보자

- 이제 단어 집합에 정수 인코딩을 적용해보자
Bag of Words (BOW)
- 단어들을 가방에 넣고 흔들면 순서가 없어지고 단어 자체에 집중
- 빈도수와 단어가 문장에서 얼만큼 영향을 미치는가에 집중하게 된다
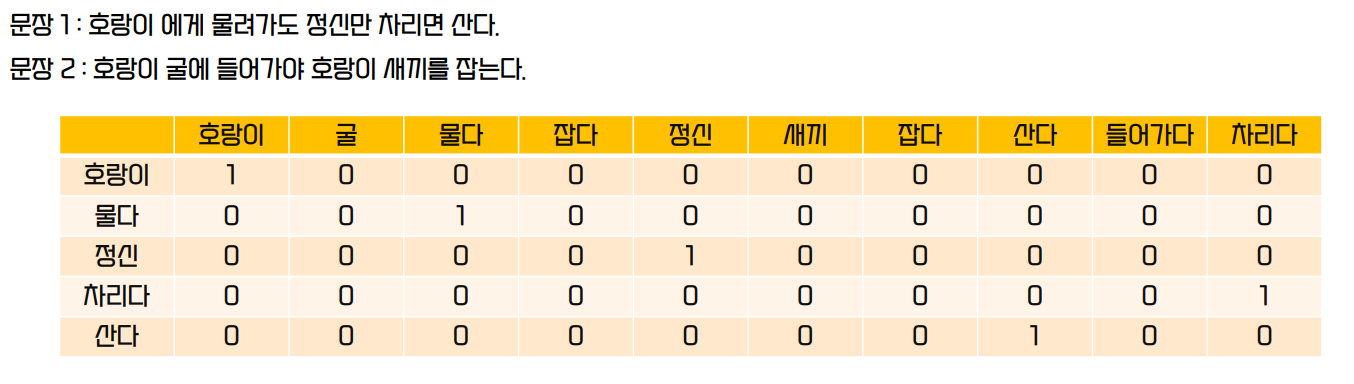
One Hot Encoding
- 문장으로부터 단어 집합을 만들고, 문장 내 단어 유무를 0과 1로 표시
- 가로는 단어 집합이 된다
Document Term Matrix (DTM)
- 각 문장마다 등장한 단어의 빈도수를 표시
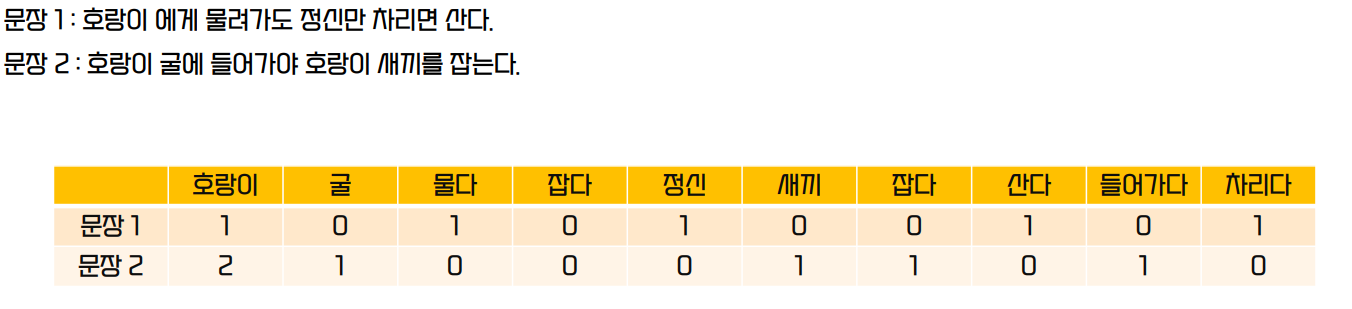
- DTM 생성에는 CountVectorizer 가 사용된다
- CountVectorizer 에 문장 뭉치 (corpus) 를 입력해보자
from sklearn.feature_extraction.text import CountVectorizer
cnt_vector = CountVectorizer()
cnt_vector.fit(corpus)
feature_vector = cnt_vector.transform(corpus)
# 단어 확인
vocabs = sorted(cnt_vector.vocabulary_.items()) # 단어 순서대로 정렬
vocabs = [ item[0] for item in vocabs ] # 단어만 뽑아내기TF-IDF
- Term Frequency - Inverse Document Frequency
- 문장 내 단어의 중요도를 계산
- TF : 단어의 등장 횟수 즉 DTM
- IDF : DF 의 역수, DF 는 단어가 등장한 문서의 갯수
- TF-IDF = TF * IDF
- 각 문장에 대해 주제가 될 수 있는 단어들을 생각해 보자
문장 1: 피카츄는 전기 포켓몬이며, 피카츄가 진화하면 라이츄가 됩니다.
문장 2 : 꼬부기는 물 포켓몬이며, 꼬부기가 진화하면 어니부기가 됩니다.
문장 3 : 파이리는 불 포켓몬이며, 파이리가 진화하면 리자드가 됩니다
- 문장 1의 주제는 무엇일까?
- 피카츄의 TF-IDF = 2 * 1/1 = 2
- 포켓몬의 TF-IDF = 1 * 1/3 = 1/3
- 라이츄의 TF-IDF = 1 * 1/1 = 1
=> 주제 단어는 피카츄라고 할 수 있다.
- 모든 문장에서 '포켓몬'이 등장하기 때문에 주제 단어로 생각하지 않는다
- TF-IDF 분석에는 TdifdVectorizer 가 사용된다
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vector = TfidfVectorizer()
tfidf_vector.fit(corpus)
feature_vector = tfidf_vector.transform(corpus)
feature_vector
vocabs = sorted(cnt_vector.vocabulary_.items()) # 단어 순서대로 정렬
vocabs = [ item[0] for item in vocabs ] # 단어만 뽑아내기
인하대학교 컴퓨터공학과