- 문서들에 잠재된 공통의 주제들을 추출
- 문서들이 가지는 주요 주제들의 분포와 의미를 제공
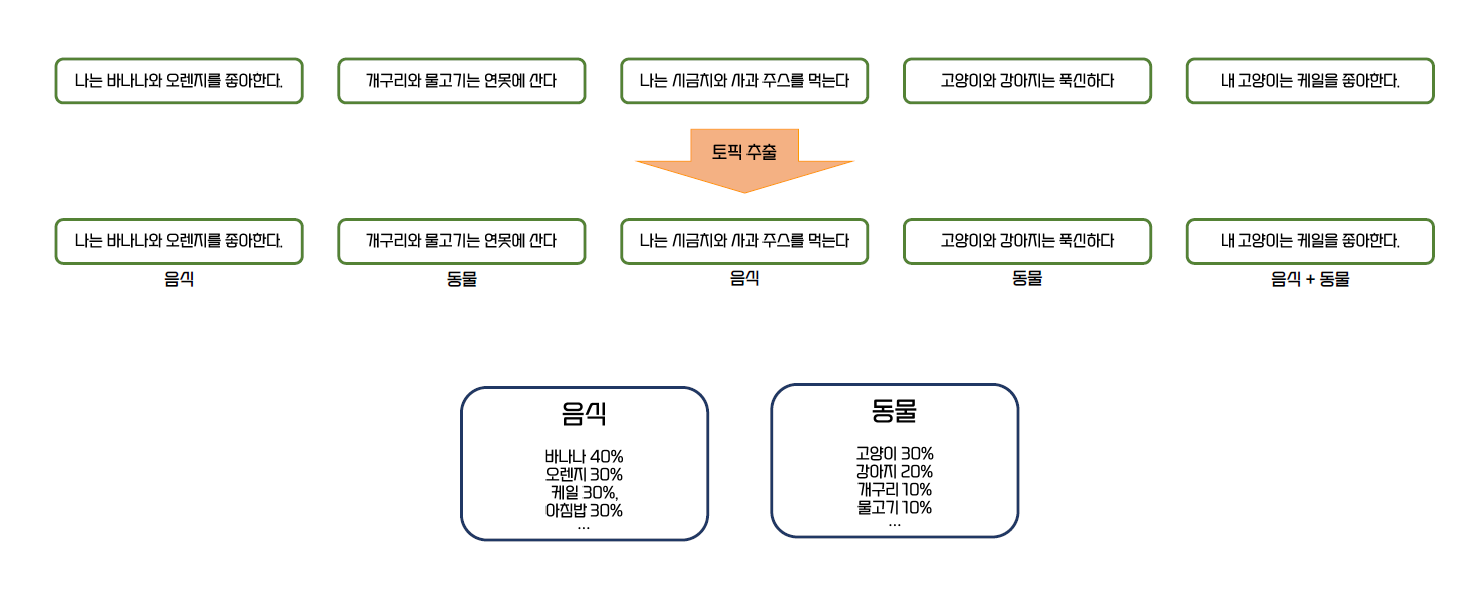
- 각 문장들의 주제가 될 수 있는 단어들을 집합으로 만들 수 있다.
LDA (Latent Dirichlet Allocation)
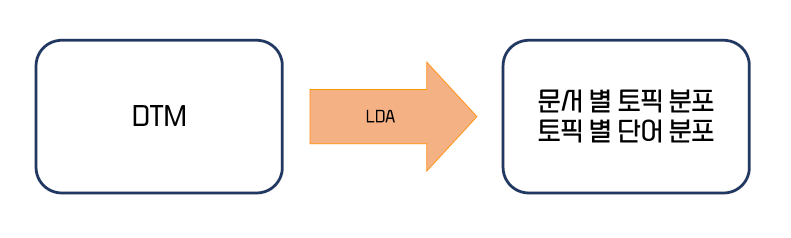
- Document Term Matrix 에서 문서 별 토픽 분포와 토픽 별 단어 분포를 찾는다
- 문서 별 토픽 분포 : 어떤 토픽에 대한 한 문서에서의 구성비
- 토픽 별 단어 분포 : 토픽 내 어떤 단어의 구성비
- 베이즈 추론을 통해 잠재된 문서 내 토픽 분포와 토픽 별 단어 분포를
추론 - LDA의 베이즈 추론의 사전 확률 분포로 사용되는 것이 디리클레 분포
=> 사전 확률을 이용해 사후 확률을 업데이트
LDA 구성 요소와 작동 방식
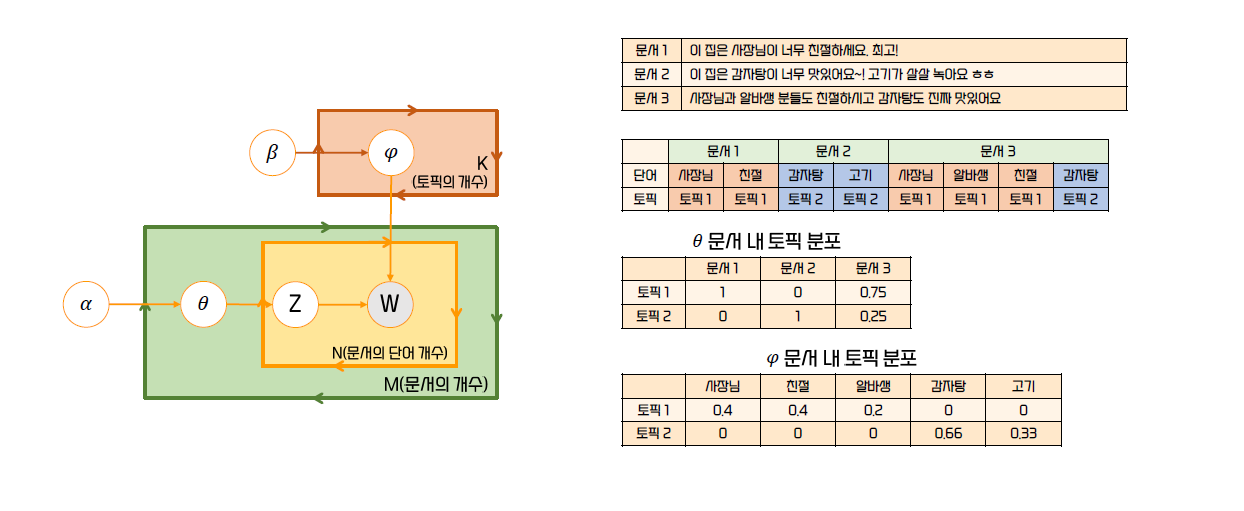
- 각 문서에서 같이 자주 등장하는 단어들을 분석한다
=> 이들은 같은 주제를 이룰 확률이 높다 - 위에서 진행한 그룹화를 바탕으로 토픽 분포 분석

인하대학교 컴퓨터공학과