- 신경망은 손실이 낮아지도록 입력 데이터에 대한 예측을 수행
- 입력 데이터 X 에 대한 loss 가 낮아야 한다.
- 입력 데이터 X 는 변하지 않기 때문에, 최적의 매개변수를 찾는 것이 관건
Optimization : 잘못된 예측 결과의 확률을 줄이기 위해 W, b 를 줄인다
경사 하강법
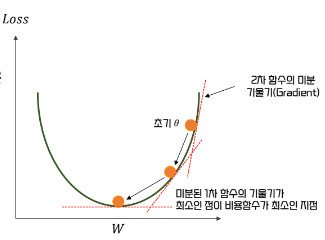
- 손실함수에 대한 매개변수의 기울기를 이용해 최소 지점을 찾아내는 것.
- 기울기의 음의 방향으로 이동하면 최소 지점에 도달할 수 있다.
- 단계마다 얼마나 이동할지는 learning rate 에 의해 결정된다.
- 기울기가 감소하지 않는 지점을 손실 함수가 최소인 지점으로 간주한다
def gradient_descent(f, start_x, lr=0.01, step_num=100):
'''
f : 경사하강법을 수행할 함수(미분 대상 함수)
start_x : x의 최초 지점
lr : learning_rate
step_num : 경사하강법 수행 횟수
'''
x = start_x
for i in range(step_num):
# 1. Gradient Vector 얻기
grads = numerical_gradient(f, x)
print("좌표 : {} / 기울기 : {}".format(x, grads))
# 2. 경사하강법 공식을 이용한 좌표 갱신
x = x - lr * grads
# 최종 좌표를 리턴
return x신경망에서의 기울기

- jacobian 행렬의 각 원소는 parameter 변경 시 loss function 값의 변화를 나타낸다
MLP 구현하기
- MNIST classification task 를 위한 간단한 MLP 를 구현해보자
- 각 데이터는 28*28 이미지
- 한 층의 은닉층은 100개, 출력층은 10개의 뉴런으로 구성
=> 최종 class 가 10개이기 때문이다.
- activation functions
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x):
if x.ndim == 2:
x = x.T # 열(클래스)을 기준으로 계산
x = x - np.max(x, axis=0) # overflow 대책
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x)
return np.exp(x) / np.sum(np.exp(x))- loss function
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 훈련 데이터가 원-핫 벡터라면 정답 레이블의 인덱스로 반환
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size- gradient
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 값 복원
it.iternext()
return grad- MLP
class TwoLayerNet:
def __init__(self, input_size=28*28, hidden_size=100, output_size=10):
self.params = {}
self.params["W1"] = np.random.randn(input_size, hidden_size) # ( 784, 100 )
self.params["b1"] = np.random.randn(hidden_size) # (100, )
self.params["W2"] = np.random.randn(hidden_size, output_size) # (100, 10)
self.params["b2"] = np.random.randn(output_size) # (10, )
# 순전파 구현
def predict(self, x):
W1, b1 = self.params["W1"], self.params["b1"]
W2, b2 = self.params["W2"], self.params["b2"]
# 1층 은닉층 계산
z1 = x @ W1 + b1
a1 = sigmoid(z1)
# 2층 출력층 계산
z2 = a1 @ W2 + b2
y = softmax(z2)
return y
def loss(self, x, t):
y = self.predict(x)
loss_val = cross_entropy_error(y, t)
return loss_val
# 각 매개변수의 기울기 배열 구하기
def numerical_gradient_params(self, x, t):
grads = {}
# 각 매개변수(W1, b1, W2, b2)에 대한 기울기 배열 구하기
print("=======미분 시작=======")
# 함수를 다른 함수의 인자로 전달하기 위해 anonymous function 이용
loss_param_f = lambda p : self.loss(x, t)
# 1층 매개변수에 대한 기울기 배열 구하기. Loss에 대한 W1, b1의 기울기를 grads 저장
grads["W1"] = numerical_gradient(loss_param_f, self.params["W1"])
grads["b1"] = numerical_gradient(loss_param_f, self.params["b1"])
# 2층 매개변수에 대한 기울기 배열 구하기. Loss에 대한 W2, b2의 기울기를 grads 저장
grads["W2"] = numerical_gradient(loss_param_f, self.params["W2"])
grads["b2"] = numerical_gradient(loss_param_f, self.params["b2"])
print("=======미분 끝=======")
return grads- Training by Gradient Descent
# 반복 횟수 설정 (경사 하강법 수행 횟수)
iter_nums = 10000
# 미니 배치 크기 설정
batch_size = 100
train_size = X_train.shape[0]
# 학습률
learning_rate = 0.01
model = TwoLayerNet()
for i in tqdm(range(iter_nums)):
# 미니 배치 생성 (랜덤하게 선택 - shuffle)
batch_indexes = np.random.choice(train_size, batch_size)
X_batch = X_train[batch_indexes]
t_batch = t_train[batch_indexes]
# 각 매개변수의 기울기 배열 구하기 (수치 미분)
# 기울기를 알아야 경사하강법을 이용한 optimization 가능
grads = model.numerical_gradient_params(X_batch, t_batch)
# 경사하강법 수행
keys = ["W1", "W2", "b1", "b2"]
# 각 매개변수를 경사하강법으로 최적화
for key in keys:
model.params[key] = model.params[key] - learning_rate * grads[key]
# 갱신된 loss 확인
loss = model.loss(X_batch, t_batch)
print("Step {} ====> Loss {}".format(i+1, loss))
인하대학교 컴퓨터공학과