
나혼자만의 Bot 만들기 !

블로그를 쓰게 된건 처음이다. 그래서 처음 글은 이걸로 시작하면 좋을 것 같아 Bot을 만든지는 벌써 3개월이 다되어서야 이제 글 을 끄적인다. ㅋㅋ 시간날때 틈틈히 만든건 거의 한달동안 진행한 것 같다.ㅋㅋ
"시작하게 된 계기는 아는 형 스타트 업 회사에 잠깐 알바 차원으로 일을 하게 되었다. 거기서 간단한 프로그래밍 부탁을 받아 어 떻게 보면 완전 아무코토 모택동인 상태에서 시작을 하는 프로그래밍이라 걱정이 앞서는 편이었다. 또한, 언어도 Python은 낯선 언어이었기 때문에 시작하는 것에 의미를 두고 시작을 한다. "
텔레그램 BotFather 만나기
텔레그램 봇을 만들기 전에 앞서 먼저 텔레그램 API를 이용하기 때문에 KEY를 받아와야한다.
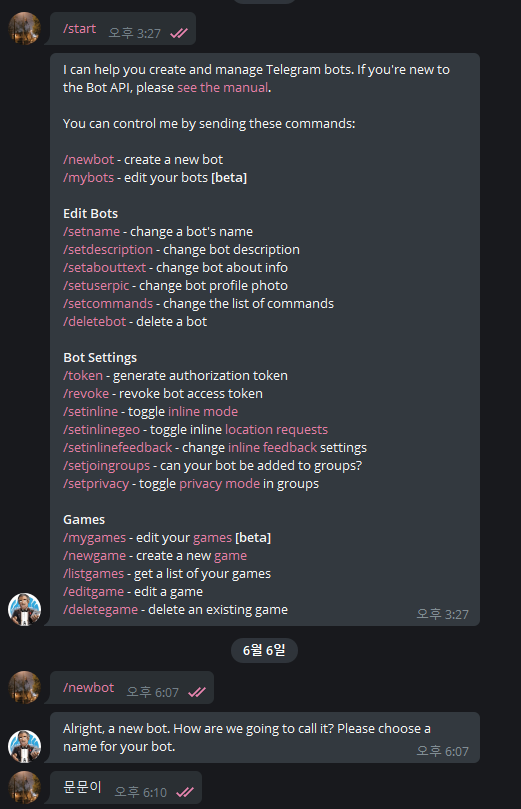
/new bot : 새로운 봇을 만든다
그리고 추후에 닉네임 같은 것을 정할 수 있다. 또 봇 id를 만들려면 무조건적으로 @%bot으로 끝내야한다.
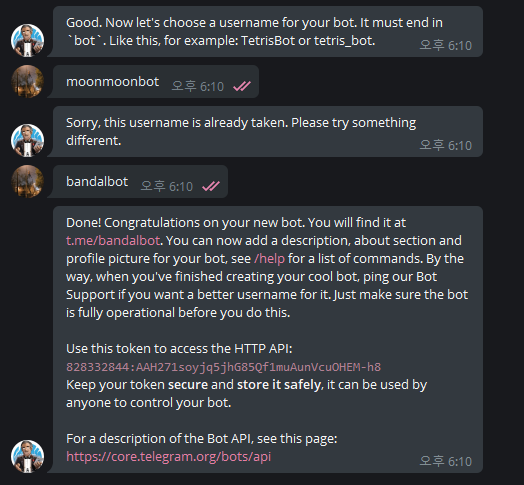
그럼 방금 말한 KEY를 발급 받는다. 그럼 그 키는 고유한 인증토큰인 것이고 다들 비슷한 형태로 뜨게 된다.
이제 준비는 끝나있는 상태다. 이제 본격적으로 토큰을 가지고 시작을 하면 된다!
시작이 반이다?
아는 형이 필요한 기능을 토대로 만들고자 하는 것을 보았을 때.
- 24시간 계속 켜있는 상태를 원한다.
- 실시간으로의 정보를 받아와야한다.
- 만약에 프로그램이 다운되더라도 쉽게 재구동을 할 수 있어야한다.
- 트위터,인터넷뉴스를 가져와야한다.이러한 요구사항들을 가지고 시작 하려니 복잡하다. 그래도 시작해보자 ㅠㅠ
보통 두 가지의 라이브러리를 쓰는 것 같았다.
결론부터 말하자면 telegram, telepot 이 둘 중 무엇을 사용 했냐면 telepot을 사용을 하게 되었다. telegram에 대해서는 자세히 찾아보았지는 않지만 telepot의 경우 Python 3.5의 경우 비동기 기반 버전도 갖추고 있다고 한다.
사실 telepot을 고른 것에는 큰 이유는 없는 것 같다 ㅋㅋㅋ
간단한 시작인사를 하는 Bot은 나 같은 프로그래머는 그 정도는 간단하기 때문에 바로 생략!
"사실 이미 간단한 과정은 너무 많이 했고 프로그램 만든지도 시작이 꽤 되기 때문에 ... 절대 귀찮아서가....맞음"
기초적인 부분을 끝내고 가장 먼저 시작한 건 홈페이지에 있는 뉴스 글을 크롤링하는 것 부터 시작을 했다.
[^크롤링]: 우리가 보고 있는 정보를 브라우저뿐만아니라 보기 편한 방식으로 로컬에 가져오는 방식이다.
뉴스를 가져오자!
그러기 위해 필요한 라이브러리는
requests : Python에서 HTTP 요청을 보내는 모듈이다.
`BeautifulSoup,bs4 : html 코드가 존재를 한다면, requests는 정보를 가져오더라도 Python이 이해하지 못하는 객체구조로 존재 되어있는데 그러한 변환을 Parsing을 해준다. 그래서 우리가 쓸 수 있는 정보로 변경 할 수 있다.
req = requests.get('http://www.coindeskkorea.com/news/articleList.html?view_type=sm')
html = req.text
soup = BeautifulSoup(html, 'html.parser')
article_list = soup.find("section", {"class" : "article-list-content type-sm text-left"})
article_link = article_list.find("a").attrs['href']현재 2 줄에서 HTML 소스를 가져오고
3줄에서 BeautifulSoup으로 html소스를 python객체로 변환을 하고 있다.
그리고 4줄에서 내가 필요로하는 정보를 가져온다.
그렇다면?! 어떻게 정보를 가져오나?
나는 구글 Chrome을 애용을 한다.
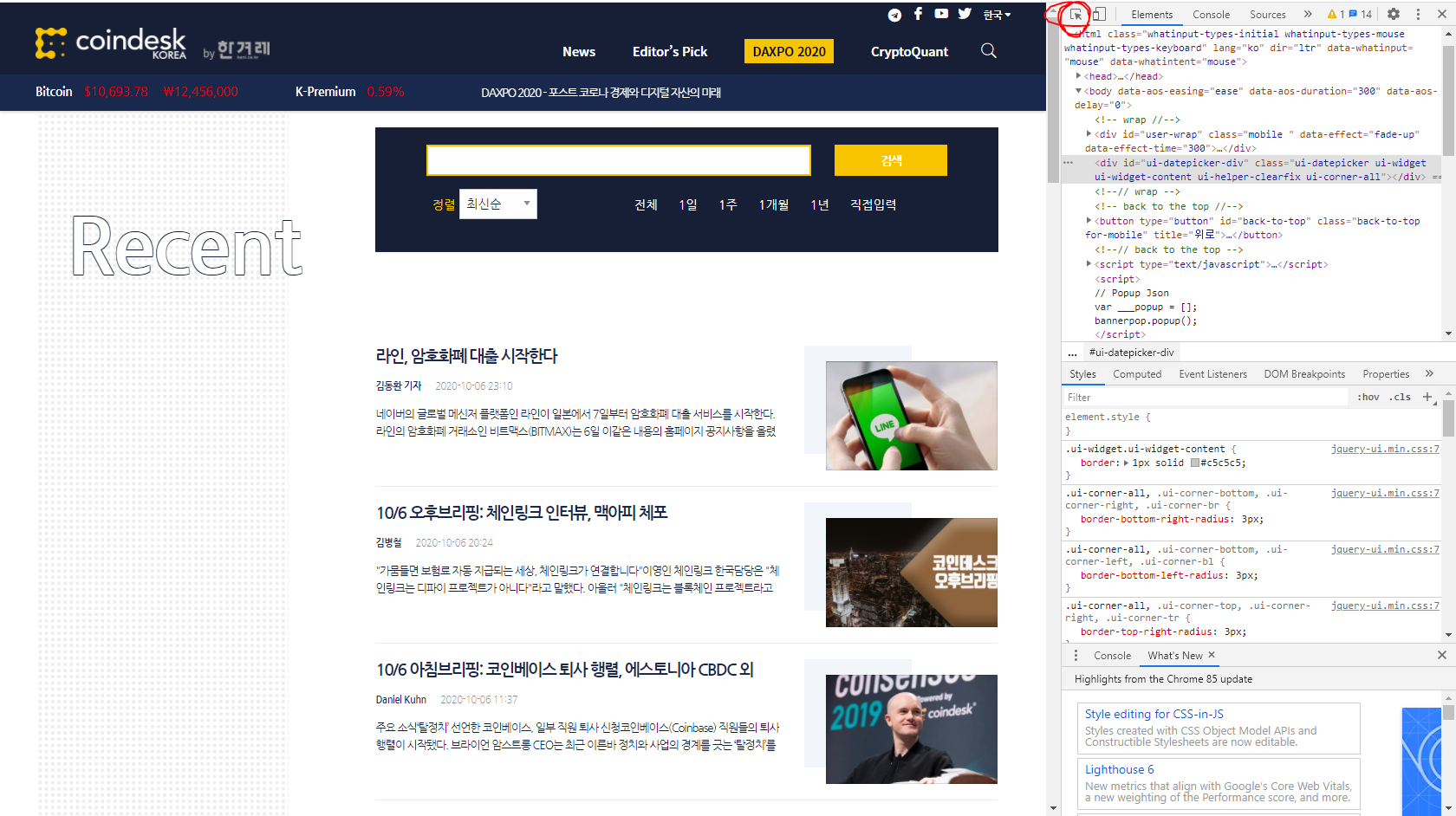
F12를 클릭한 후 저 빨간 동그라미를 클릭을 한다. 그리고 필요로한 영역에 가져다가 커서를 두면 그정보가 나온다.
어떻게????????????????????????????
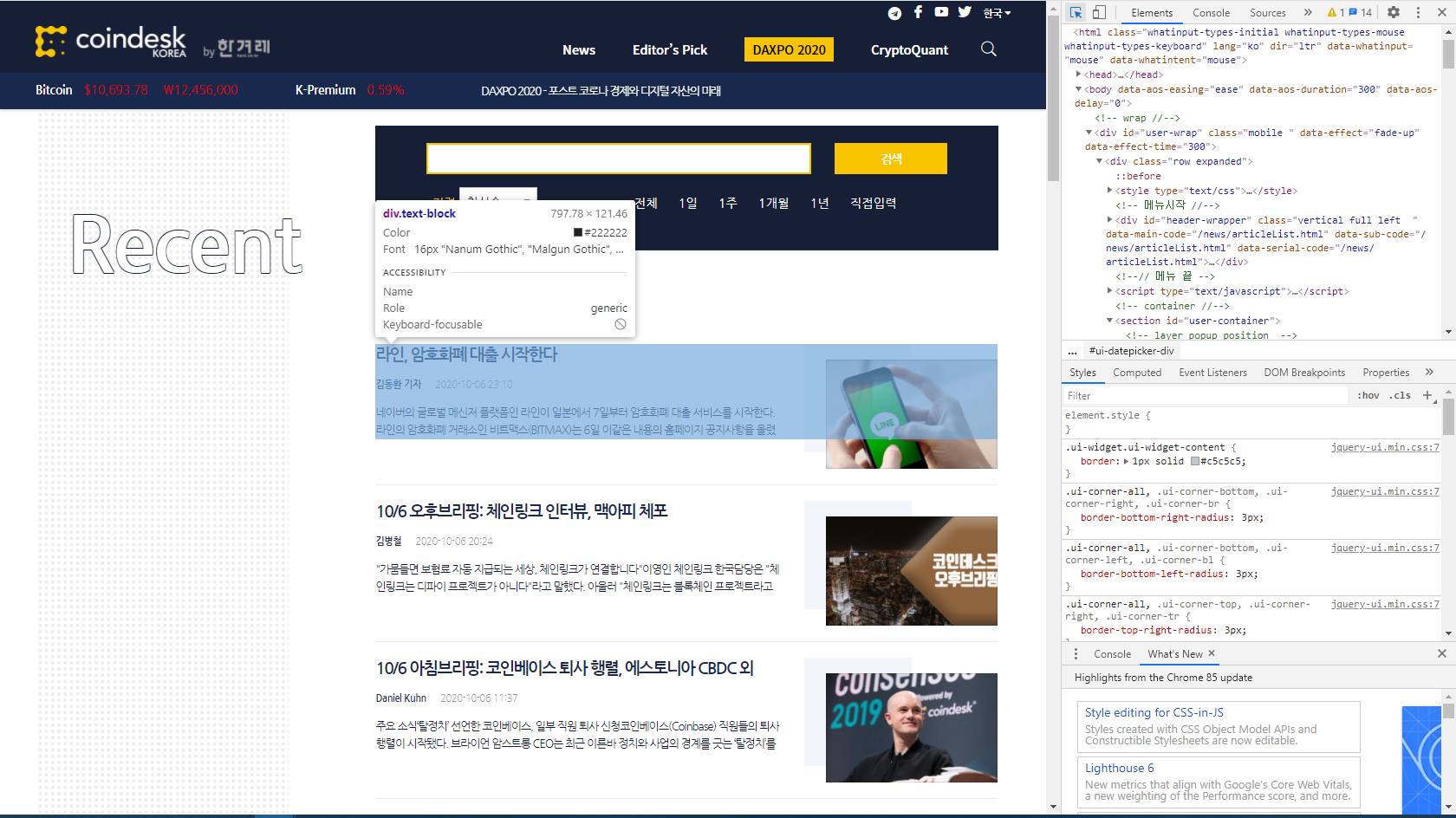
요런식으로 뜬다. 그리고 조금 더 자세한 정보를 가져오고 싶다면?!
우클릭을 한후 페이지 소스를 보기를 누른다. 우리는 새로운 뉴스를 가져오고 싶다.
이렇게 하면 아주 간단하게 가져올 수 있을 거다!
실시간으로 뉴스정보를 가져다 주려고 한다면?
많은 생각을 해보았다. 근데 복잡하게 생각할 것이 없는 것 같더라...
그냥 내 생각에는 이게 가장 무식한건가? 무식하게 몇초마다 갱신 갱신 갱신 갱신 갱신 갱신 갱신 갱신 갱신 갱신 하는 것말고는 나의 머리로는 알고리즘을 짤수가 없었다ㅋㅋㅋㅋ 더 좋은 방법이 있으면 다들 말씀해주시기를 ㅠ.ㅠ
몇초 혹은 몇분동안 갱신을 하려면 처음에 가지고 있는 정보를 저장을 해놓고 비교를 한다. 그럼 비교를 했을 때 같을 경우는 그냥 넘 어가고 만약에 다르다? 다르면 이제 바뀐정보로 저장을 해버리고 새로운 정보를 텔레그램 봇을 통해 그 정보를 나오게한다!
while True:
req = requests.get('http://www.coindeskkorea.com/news/articleList.html?view_type=sm')
html = req.text
soup = BeautifulSoup(html, 'html.parser')
article_list = soup.find("section", {"class" : "article-list-content type-sm text-left"})
article_link = article_list.find("a").attrs['href']
# latest_num이랑 articel_link가 중복시 아무 반응 없고, 다르면 새로운 뉴스 나옴
if latest_num != article_link :
latest_num = article_link
link = 'http://www.coindeskkorea.com'+ article_link
req = requests.get(link)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
title = soup.find("div", {"class" : "article-head-title"}).text
new_article = '<코인데스크 코리아>'+'\n'+title + '\n'+link
bot.sendMessage(chat_id, new_article)
# 프롬프트 로그
print(link)
print(title)
time.sleep(30) # 30초마다 크롤링 여기서 17절에는 자신의 해당되는 chat_id가 존재한다. 그걸 각자 찾은 후 넣으면 된다. 섹션은 알아서 잘 확인해 자기가 직접 필요 로하는 정보를 가져오면 된다.
프롬프트 로그를 출력을 해서 지금 정보가 제대로 나오고 있는지 확인을 한다.
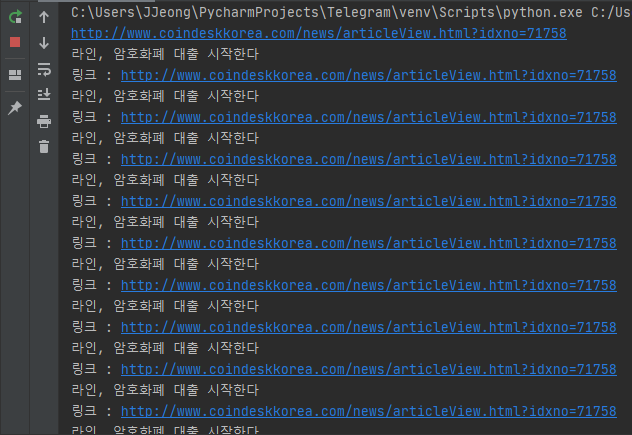
시간이 5분 정도 흐른 것 같다. 30초마다 크롤링을 계속 해주고 있기 때문에..
보시면 잘 돌아가고 있다. 그렇다면 과연 텔레그램 봇에는 잘 나오고 있을까?
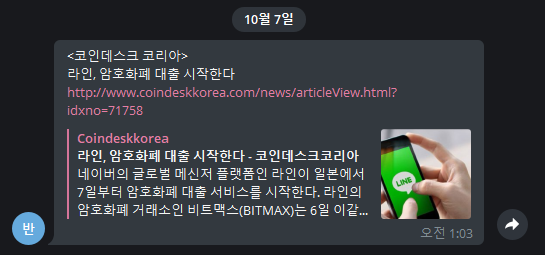
아주 만족스럽게 나오고 있다. 제일 처음으로 만든 뉴스 크롤링하는 봇이었다. 처음 설계 했기 때문에 아주 문제점이 많았던 걸로 기 억한다. 아직까지 말한 조건 중 이제 작은 하나를 수행했기 때문에.....ㅠㅠㅠㅠㅠ 처음 설계하고 막막했기 때문에
완성된 소스코드를 올릴께유
import requests
import time
from bs4 import BeautifulSoup
import telepot
bot = telepot.Bot(token='자기토큰 넣으셈')
chat_id='자기 챗id 넣으셈'
channel_id ='채널 쓸꺼면 @채널명 넣으셈'
if __name__ == '__main__':
# 제일 최신 게시글의 번호 저장
latest_num = 0
while True:
req = requests.get('http://www.coindeskkorea.com/news/articleList.html?view_type=sm')
html = req.text
soup = BeautifulSoup(html, 'html.parser')
article_list = soup.find("section", {"class" : "article-list-content type-sm text-left"})
article_link = article_list.find("a").attrs['href']
# 최신글만 30초마다 크롤링
# latest_num이랑 articel_link가 중복시 아무 반응 없고, 다르면 새로운 뉴스 나옴
if latest_num != article_link :
latest_num = article_link
link = 'http://www.coindeskkorea.com'+ article_link
req = requests.get(link)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
title = soup.find("div", {"class" : "article-head-title"}).text
new_article = '<코인데스크 코리아>'+'\n'+title + '\n'+link
bot.sendMessage(chat_id, new_article)
# 프롬프트 로그
print(link)
print(title)
time.sleep(30) # 30초 간격으로 크롤링
print('링크 : http://www.coindeskkorea.com' + latest_num)
print(title)이건 제일 처음 만들었기 때문에 문제점이 참 많았다.
- 1대1로 밖에 정보를 얻을 수 없음
- chat_id 정보를 내가 소스코드에 입력해야지만 봇이 가동
또 기타 등등 더 있었으나 더이상 기억이 나지 않기 때문에 pass 어찌되었든 다음 글에서는 이러한 문제점을 다 수정한 걸로
다시 찾아오겠다 ㅃㅇㅉㅇㅉㅇㅅㅇㄴㄹ
※여기서 참고하시면 된다※
완성된 소스코드가 궁금하신 분들은? https://github.com/jjeongho/Telegram
