- numpy 기초문제 5번
: 컬러이미지를 흑백이미지로 바꾸는 문제
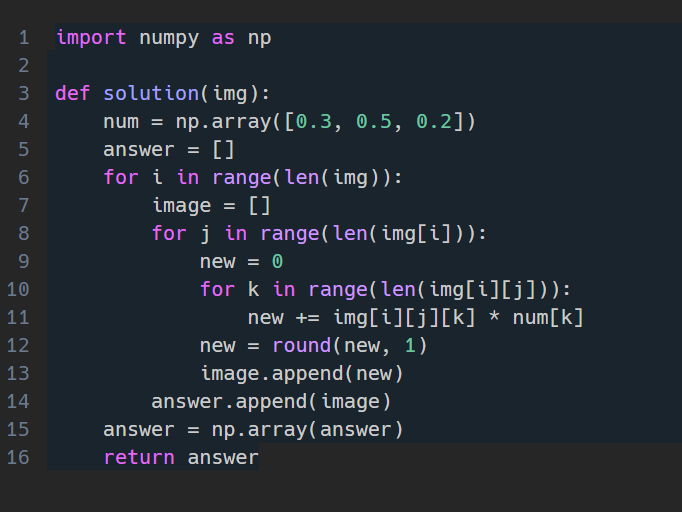
컬러이미지는 3차원 배열. 흑백이미지는 2차원 배열.
흑백 이미지의 명도로 변환 하는 공식은
명도 값 = Red 0.3 + Green 0.5 + Blue * 0.2.
-> R,G,B를 표현하는 각각의 수를 위의 공식에 대입하여 명도 값 하나 도출.
컬러이미지는 3차원 배열이므로, 반복문을 써줄 때는 총 행렬의 개수, 각 행렬의 행의 수, 각 행렬의 열의 수 순으로 써준다.
또한 num = np.array([0.3, 0.5, 0.2]) 배열을 만들어줘 R,G,B를 표현하는 각각의 수에 0.3, 0.5, 0.2를 곱해줘 더해준다. R,G,B 순이므로 순서도 0.3, 0.5, 0.2 순으로.
한 반복문이 끝나면, 다시 새로운 계산 값을 넣어야 하므로 변수 초기화 과정도 넣음.
return 해줄 변수는 초기에 리스트로 설정(append 해주기 위해). 마지막에 넘파이 배열화.
- 넷플릭스 문제 (주간 미션)
1번 :
import pandas as pd
Netflix = pd.read_csv("netflix_titles.csv")
Netflix[Netflix["country"] == "South Korea"]South Korea만 해당되는 데이터가 모두 추출. 행의 개수가 199개라는 정보를 알 수 있는데, 이게 바로 한국 작품 갯수
2번:
import pandas as pd
from collections import Counter
Netflix = pd.read_csv("netflix_titles.csv")
Counter(Netflix["country"])Counter 함수를 쓰면 각 국가별 작품 갯수를 알 수 있음. 여기서도 한국 작품의 갯수가 199개라고 나옴. 가장 많은 작품을 만든 나라는 "United States" 이고, 2818개의 작품을 만들었음. (단, 이 방법은 단일 국가의 경우를 기준으로 하지 않았음. 단일 국가의 경우를 기준으로 하는 방법을 모르겠음.)
-비트코인 문제
: date를 어떻게 걸러내야 할 지 모르겠음. datetime 모듈을 써야할 것 같은데, 어떻게 표현해야 할 지 모르겠음. 문법 오류가 지속적으로 나타남.

정지호