1. 문서를 벡터로 바꾸는 방법
- 문서를 벡터 표현으로 바꾸어주면 여러 가지 수치 연산을 할 수 있게 된다.
- 문서를 벡터로 바꾸는 방법은 CountVectorizer, TfidfVectorizer가 대표적으로 있다.
2. TF-IDF
-
TF-IDF 는 '단어빈도(TF)'와 '문서빈도의 역수(IDF)'를 곱한 값이다.
-
CountVectorizer는 각 단어가 문서에서 몇 번 출현했는지를 기반으로 문서를 벡터화하였다. 단어 빈도수를 기반으로 벡터로 표현한 이유는 단어의 빈도가 의미있는 정보라고 생각하기 때문이다.
하지만 같은 문서에 똑같이 횟수만큼 출현한 단어 간에도 중요도에 차이가 있는 경우가 있다.
=> 그렇기 때문에 단어의 빈도를 세주더라도, 중요하지 않은 단어에는 가중치를 조금만 주어 문서 벡터의 방향이 좀 더 중요한 단어들에 의해 좌우될 수 있도록 하는 것이 TF-IDF. -
단어빈도(TF)
: 특정 단어가 한 문서 내에서 출현한 빈도
: 예를 들어, 다음 두 개의 문서
를 아래와 같이 표현해주는 것을 문서 단어 행렬이라 하는데,
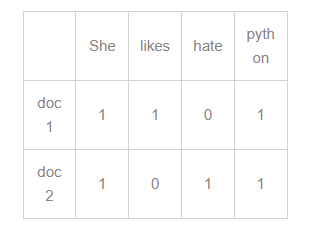 위 표에 나와 있는 숫자들이 바로 단어빈도이다.
위 표에 나와 있는 숫자들이 바로 단어빈도이다. -
문서빈도의 역수(IDF, Inverse Document Frequency)
-
문서빈도: 특정한 단어가 출현한 전체 문서의 개수
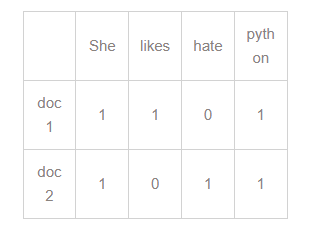 위 표에서 She는 두 개의 문서에 출현했으니까 She의 문서빈도는 2. 반면 likes는 한 개의 문서에 출현했으므로 문서빈도는 1.
위 표에서 She는 두 개의 문서에 출현했으니까 She의 문서빈도는 2. 반면 likes는 한 개의 문서에 출현했으므로 문서빈도는 1. -
IDF는 문서 빈도의 역수. she의 IDF를 구하기 위해서는 2의 역수를 취해주게 되는데, 문서의 개수에 영향을 받지 않도록 정규화를 해준다.
즉, 전체 문서의 개수와 상관없도록 비율로 계산해준다.
그러면 she는 (2의 역수, 0.5)x(전체 문서의 개수, 2) 이므로 0.5 X 2 = 1 이다. 반면, likes는 (1의 역수)x(전체 문서의 개수) = 2이다.
(이처럼 출현 빈도가 작은 단어에 높은 가중치(IDF)를 주는 것이다.)
그리고 마지막으로, 정규화한 값에 log 값을 취하면 IDF가 된다.
-
3. Norm / Normalization / Standardization / Regularization
- Norm: 벡터의 길이 혹은 크기를 측정하는 방법(함수). Norm이 측정한 벡터의 크기는 원점에서 벡터 좌표까지의 거리 혹은 Magnitude라고 한다.
- Normalization: 정규화. x값의 범위를 0~1로 조정하는 작업이다.
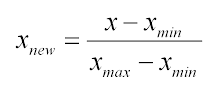
- Standardization: 표준화. 표준정규분포에서 현재의 x값이 평균에서 얼마나 멀리 떨어진 값인지를 표준편차의 배수의 형태로 구하는 방식이 이 Standardization의 일종이다.
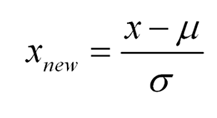
- Regularization: 일반화. 오버피팅을 해결하기 위해 활용되며, Norm이 사용된다.
출처
https://m.blog.naver.com/myincizor/221644893910
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=dbstmdgks93&logNo=221478457085
