-
머신러닝의 최적화도 매우 복잡하다.
: 훈련 집합으로 학습을 마친 후, 현장에서 발생하는 새로운 샘플을 잘 예측해야 한다 -> 즉 일반화 능력이 좋아야 한다.
: 머신러닝의 최적화가 어려운 이유(긴 훈련 시간 / 매개탐색 공간에서 목적함수의 비볼록 성질) -
평균제곱 오차(MSE)
: 허점이 존재한다. (그림의 가로축이 커지면 경사도가 작아진다)
: 신경망 학습 과정에서 학습은 오류를 줄이는 방향으로 가중치와 편향을 교정하는데, 큰 교정이 필요함에도 작은 경사도로 작게 갱신된다. -
교차 엔트로피와 로그우도 목적함수
: 학습 과정의 성능 판정의 중요성
: 교차 엔트로피
-> 라벨에 해당하는 y가 확률변수
-> 확률 분포: P는 정답, Q는 신경망(예측) 출력
-> 공정한 벌점을 부여하는지 확인 -> 경사도를 계산해 보면, 오류가 더 큰 쪽에 더 큰 벌점(경사도)를 부과
-
소프트맥스 함수
: max를 모방
: 모두 더하면 1이 되어 확률 모방
: 출력층의 변화에 따라 소프트맥스의 결과도 최대 출력에 더 가까워짐. 따라서 부드러운 최대 함수로 불림. -
소프트맥스 활성함수와 로그우도 목적함수
: 음의 로그우도 목적함수 -> 하나의 노드만 적용
: 소프트맥스는 최댓값이 아닌 값을 억제하여 0에 가깝게 만든다는 의도 내포.
: 신경망에 의한 샘플의 정답에 해당하는 노드만 보겠다는 로그우도와 잘 어울림.
=> 둘을 결합하여 사용하는 경우가 많음. -
소프트맥스 활성함수와 교차 엔트로피 목적함수
: 로그우도 손실 함수 ~ 교차 엔트로피 최소화 -
성능 향상을 위한 요령
-
데이터 전처리
: 규모 문제 -> 느린 학습의 요인
: 모든 특징이 양수인 경우의 문제(가중치가 뭉치로 증가 또는 감소하면 최저점을 찾아가는 경로가 갈팡질팡하여 느린 수렴)
=> 정규화는 규모 문제와 양수 문제를 해결해 준다. or 명목 변수(객체간 서로 구분하기 위한 변수)를 원핫 코드로 변환 -
가중치 초기화
: 대칭적 가중치 문제 -> 난수로 가중치 초기화(가우시안 또는 균일 분포에서 난수를 추출) or 가중치 행렬의 행 혹은 열이 수직이 되도록 설정 or 노드의 출력 값 분포가 일정하도록 강제화
or 임의 행로 활용하여 설정 or 가중치 초기화와 가속도를 동시에 최적화 -
탄력(가속도, 관성)
: 경사도의 잡음 현상 -> 탄력은 경사도에 부드러움을 가하여 잡음 효과를 줄임
: 관성을 적용한 가중치 갱신 수식
: 관성의 효과
: 네스테로프 가속 경사도 관성 -
적응적 학습률
: 학습률의 중요성 -> 너무 크면 지나침에 따른 진자 현상, 너무 작으면 수렴이 느림
: 적응적 학습률 -> 매개변수마다 자신의 상황에 따라 학습률을 조절(학습률 담금질)
: AdaGrad(적응적 학습률을 적용한 gradient descent 방법)
: Adam(RMSProp에 관성을 추가로 적용한 알고리즘) -
활성함수
: 선형 연산 결과인 활성값 z에 비선형 활성함수를 적용하는 과정
: sigmoid 함수는 활성값이 커지면 포화 상태가 되고 경사도가 0에 가까운 값을 출력함 -> 매개변수 갱신이 매우 느린 요인
: ReLU 활성함수 -> 경사도 포화 문제 해소
: 그 밖에서 tanh 함수, Leaky ReLU 함수, Maxout 함수, ELU 함수 -
배치 정규화
: 공변량 변화 현상 -> 훈련집합과 테스트집합의 분포가 다름
: 내부의 공변량 변화 -> 데이터의 분포가 수시로 바뀜 -> 층이 깊어짐에 따라 더욱 심해짐 -> 학습을 방해 (공변량 시프트)
: 배치 정규화는 공변량 시프트 현상을 누그러뜨리기 위해 정규화를 층 단위 적용하는 기법이다.
: 미니배치에 적용하는 것이 유리
: 과정 -> 1. 미니배치 단위로 평균과 분산을 계산하고, 2. 구한 평균과 분산을 통해 정규화, 3. 비례와 이동을 세부 조정한다.
: 장점(경사도 흐름 개선, 높은 학습률 허용, 초기화에 대한 의존성 감소, 규제와 유사한 행동을 하여 드랍아웃의 필요성을 감소시킴)
: 최적화를 마친 후 추가적인 후처리 작업이 필요하다 (각 노드는 전체 훈련집합을 가지고 독립적으로 코드를 수행)
: CNN에서는 노드 단위가 아니라 특징 맵 단위로 코드1과 코드 2를 적용 -
학습 모델의 용량에 따른 일반화 능력
: 대부분 가지고 있는 데이터에 비해 훨씬 큰 용량의 모델을 사용한다.
: 현대 기계 학습의 전략 -> 충분히 큰 용량의 모델을 설계한 다음, 학습 과정에서 여러 규제 기법을 적용 -
규제(모델 용량에 비해 데이터가 부족한 경우의 부족조건문제를 푸는 접근법)
: 명시적 규제 -> 가중치 감쇠나 드롭아웃 처럼 목적함수나 신경망 구조를 직접 수정하는 방식
: 암시적 규제 -> 조기 멈춤, 데이터 증대, 잡음 추가, 앙상블처럼 간접적으로 영향을 미치는 방식: 가중치 벌칙
- 규제항은 훈련집합과 무관하며, 데이터 생성 과정에 내재한 사전 지식에 해당한다. 또한 매개변수를 작은 값으로 유지하므로 모델의 용량을 제한하는 역할(수치적 용량을 제한함)
- 큰 가중치에 벌칙을 가해 작은 가중치를 유지하려고 주로 L2 놈이나 L1 놈을 규제항으로 사용한다.
- L2 놈: 규제 항 R로 L2 놈을 사용하는 규제 기법을 가중치 감쇠라고 부름.
- 최종해를 원점 가까이 당기는 효과(즉 가중치를 작게 유지함) == 가중치 감쇠 효과
- 선형 회귀에 적용
- MLP와 DMLP에 적용
- L1 놈의 희소성 효과 (0이 되는 매개변수가 많음) -> 선형회귀에 적용하면 특징 선택 효과
- 규제
- 매끄럽게 하여 최적화 개선 , 학습 모델을 단순화시켜 일반화 성능 향상시킴
- 대표적인 예로 L2 규제, L1 규제, 엘라스틱 넷.
: 조기 멈춤
- 학습시간에 따른 일반화 능력
(일정 시간이 지나면 과잉적합 현상이 나타나 일반화 능력이 저하된다. => 오류가 최저인 점에서 조기 멈춤을 하여 학습을 멈춘다. 신경망 과제에서 사용한 방법)
: 데이터 확대
- 과잉적합 방지하는 가장 확실한 방법은 큰 훈련집합을 사용하는 것
- 하지만 데이터 수집은 비용이 많이 듦
=> 데이터 확대라는 규제기법으로, 데이터를 인위적으로 변형하여 확대한다.
예) 모핑, 자연영상 확대, 잡음을 섞어 확대하는 기법
: 드롭 아웃
- 완전 연결층의 노드 중 일정 비율을 임의 선택하여 제거 -> 남은 부분 신경망 학습
- 많은 부분 신경망을 만들고, 앙상블 결합하는 기법으로 볼 수 있음
- 참거짓 배열 파이로 노드 제거 여부 표시
- 파이는 (미니 배치) 샘플마다 독립적으로 정하는데, 난수로 설정함.
- 일반적으로 입력층 제거 비율은 0.2 / 은닉층 제거 비율은 0.5
- 예측 단계 (앙상블 효과 모방 : 학습 과정에서 가중치가 1-드롭아웃비율 만큼만 참여해서 p만큼 보정)
- 메모리와 계산 효율(추가 메모리는 참거짓 배열 파이, 추가 계산은 작음 / 실제 부담은 신경망의 크기에서 옴)
: 앙상블 기법
- 서로 다른 여러 개의 모델을 결합하여 일반화 오류를 줄이는 기법
- 현대 기계학습은 앙상블도 규제로 여김
- 서로 다른 예측기를 학습하는 일 / 2. 학습된 예측기를 결합하는 일
- 하이퍼 매개변수 최적화
- 내부 매개변수 혹은 가중치
- 하이퍼 매개변수 : 모델의 외부에서 모델의 동작을 조정(사람에 의해서 결정됨). CNN의 필터 크기와 보폭이 예)
- 격자 탐색 / 임의 탐색
- 로그 공간 간격으로 탐색
- 차원의 저주 문제 발생(단점)
- 임의 탐색이 우월함
- 크게 했다가 점차 세밀해지는 탐색
- 추가적인 최적화 방법
-
뉴턴 방법: 2차 미분 정보를 활용하여 경로를 알아낸다.
- 1차 미분 최적화: 경사도 사용하여 선형 근사 사용
- 근사치 최소화
- 머신러닝이 사용하는 목적함수는 2차 함수보다 복잡한 한수이므로, 한 번에 최적해에 도달이 불가능하다.
-> 반복하는 뉴턴 방법을 사용해야 한다.
-
2차 미분의 최적화
- 2차 미분의 최적화 : 경사도와 헤시안을 둘 다 사용하여 2차 근사 사용 근 / 근사치의 최솟값
- 테일러 급수 적용
-
켤레 경사도 방법
- 직선 탐색: 이동 크기를 결정하기 위해 직선으로 탐색하고 미분
- 켤레 경사도 방법: 직진 정보를 사용하여 해에 빨리 접근
-
유사 뉴턴 방법
- 경사하강법은 수렴 효율성이 낮고, 뉴턴 방법은 헤시안 행렬 연산이 부담된다.
=> 헤시안의 역행렬을 근사하는 행렬 M을 사용한다(이게 유사 뉴턴 방법. 역행렬을 직접구하지 않고 근사해서 구함)
=> 대표적으로 점진적으로 헤시안을 근사화하는 LFGS가 많이 사용된다.
=> 또한, 머신러닝에서는 M을 저장하는, 메모리를 적게 쓰는 L-BFGS를 주로 사용한다.
- 경사하강법은 수렴 효율성이 낮고, 뉴턴 방법은 헤시안 행렬 연산이 부담된다.
- 순차 데이터
-
시간성 데이터
: 특징이 순서를 가지므로 순차 데이터라 부름
: 순차 데이터는 동적이며 보통 가변 길이임 -
많은 응용
: 심전도 신호를 분석하여 심장 이상 유무 판정
: 주식 시세 분석하여 사고 파는 시점 결정
: 음성 인식을 통한 지능적인 인터페이스 구축
: 기계 번역기 또는 자동 응답 장치 제작
: 유전자 열 분석을 통한 치료 계획 수립 -
순차 데이터의 표현
: 대표적인 순차 데이터인 문자열의 표현
: 사전을 사용하여 표현(사전구축 방법 : 사람이 사용하는 단어를 모아 구축)
: 사전을 사용한 텍스트 순차 데이터의 표현방법에는 단어가방, 원핫 코드, 단어 임베딩이 있음.- 단어 가방 : 단어 각각의 빈도수를 세어 m차원의 벡터로 표현 / 머신러닝에는 부적절
- 원핫 코드 : 해당 단어의 위치만 1로 표시 / 한 단어를 표현하는데 m차원 벡터를 사용하는 비효율
- 단어 임베딩 : 단어 사이의 상호작용을 분석하여 새로운 공간으로 변환. 변환 과정은 학습이 말뭉치를 훈련집합으로 사용하여 알아냄.
-
순차 데이터의 특성
: 특징이 나타나는 순서가 중요
: 샘플마다 길이가 다름
: 문맥 의존성(순차 데이터에서는 공분산은 의미가 없음)
11. RNN(순환신경망)
-
순환 신경망이 갖추어야 할 세 가지 필수 기능
=> 시간성(특징을 순서대로 한 번에 하나씩 입력해야 함) / 가변 길이(길이가 T인 샘플을 처리하려면 은닉층이 T번 나타나야 한다. T는 가변적이다) / 문맥 의존성(이전 특징 내용을 기억하고 있다가 적절한 순간에 활용해야 한다.) -
구조
: 기존 깊은 신경망과 유사(입력층, 은닉층, 출력층을 가짐)
: 기존 깊은 신경망과 다른 점은 은닉층이 순환 연결을 가진다는 점이다. -> 시간성, 가변 길이, 문맥 의존성을 모두 처리할 수 있다. (순환 연결은 t-1 순간에 발생한 정보를 t 순간으로 전달하는 역할)
: RNN 학습이란 훈련집합을 최적의 성능으로 예측하는 매개변수 값을 찾는 일이다.
: 매 순간 다른 값을 사용하지 않고 같은 값을 공유한다. (공유의 장점: 추정할 매개변수 수가 획기적으로 줄어듦, 매개변수의 수가 특징 벡터의 길이 T에 무관, 특징이 나타나는 순간이 뒤바뀌어도 같거나 유사한 출력을 만들 수 있음)
: 입력의 개수T와 출력의 개수 L이 같은 경우가 있고 / T != L 인 경우가 있다. -
동작
: RNN의 가중치
: 은닉층의 계산. 은닉층의 계산이 끝난 후 출력층의 계산. -
BPTT 학습
RNN과 DMLP의 유사성: 둘 다 입력층, 은닉층, 출력층을 가짐
RNN과 DMLP의 차별성: RNN은 샘플마다 은닉층의 수가 다름 / DMLP는 왼쪽에 입력, 오른쪽에 출력이 있지만, RNN은 매 순간 입력과 출력이 있음 / RNN은 가중치를 공유함.
BPTT 알고리즘(Back propagation through time)
BPTT 학습: 전방 계산과 오류 역전파 수행 -
양방향 RNN
양방향 문맥 의존성
양방향 RNN: t 순간의 단어는 앞쪽단어와 뒤쪽단어 정보를 모두 보고 처리됨 / 머신러닝에서도 양방향 RNN을 활용함.
- 장기 문맥 의존성
- 관련된 요소가 멀리 떨어진 상황
- 문제점: 경사 소멸 문제 또는 경사 폭발 문제 / RNN은 DMLP나 CNN 보다 심각함(긴 입력 샘플이 자주 발생하고, 가중치 공유 때문에 같은 값을 계속 곱하므로) -> LSTM(long short term memory)은 가장 널리 사용되는 해결책
- LSTM(long short term memory) (길고 짧은 의존성들을 저장을 하면서 관리하겠다)
- 개폐구(gate)를 이용한 영향력 범위 확장
: 입력 개폐구와 출력 개폐구를 이용하여 입출력 제어
: LSTM 핵심요쇼 -> 1. 메모리 블록(셀) : 은닉 상태 장기 기억 / 2. 망각(forget) 개폐구 : 기억 유지 혹은 제거 / 3. 입력(input) 개폐구 : 입력 연산 / 4. 출력(output) 개폐구 : 출력연산
: RNN과 LSTM의 비교
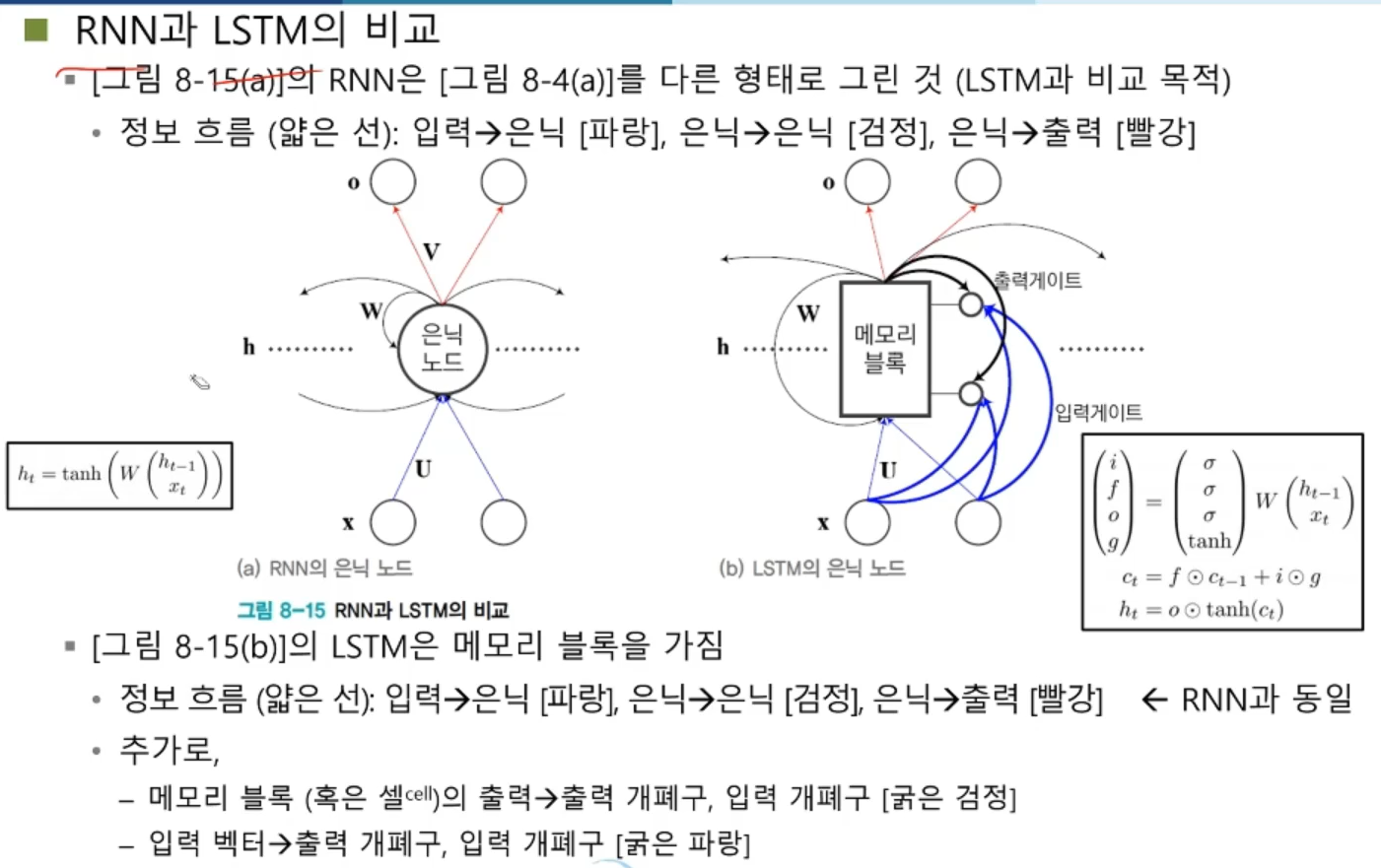
- LSTM의 동작
: 세 곳(입력단, 입력 개폐구, 출력 개폐구) 에서의 계산


: LSTM 구조에 따른 경사 흐름 개선
- 망각 개폐구와 작은 구멍(pinhole)
: 작은 구멍(pinhole) 기능으로 LSTM 확장 -> 순차 데이터를 처리하다가 어떤 조건에 따라 특별한 조치를 취해야 하는 응용에 효과적
: 작은 구멍은 블록의 내부 상태를 3개의 개폐구에 알려주는 역할을 한다.
- RNN 응용 사례
-
언어 모델
: 문장, 즉 단어 열의 확률분포를 모형화 / 음성 인식기 또는 언어 번역기가 후보로 출력한 문장이 여럿 있을 때, 언어 모델로 확률을 계산한 다음 확률이 가장 높은 것을 선택하여 성능을 높임
: 확률 분포를 추정하는 방법 -> n그램, 다층 퍼셉트론, 순환 신경망
: 순환 신경망을 이용한 언어 모델 -> 현재까지 본 단어 열을 기반으로 다음 단어를 예측하는 방식으로 학습 / 비지도 학습에 해당하여 말뭉치로부터 쉽게 훈련집합 구축 가능 -> 학습을 마치고나서 음성 인식기 성능을 향상하는데 활용 된다. -
기계 번역
: 언어 모델보다 어려움. 기계 번역은 길이가 서로 다른 열 대 열 문제
: 고전적인 통계적 기계 번역 방법의 한계 -> 현재 딥러닝 기반 기계 번역 방법이 주류
: LSTM을 사용하여 번역 과정 전체를 통째로 학습
: 가변 길이의 문장을 고정 길이의 특징 벡터로 변환한 후, 고정 길이에서 가변 길이 문장을 생성
: 모든 순간의 상태 변수를 사용하는 방식 -
영상 주석 생성
: 영상 주석 생성 응용 -> 영상 속 물체를 검출하고 인식, 물체의 속성과 행위, 물체 간의 상호 작용을 알아내는 일
: 딥러닝 접근방법 -> CNN은 영상을 분석하고 인식 + LSTM은 문장을 생성
: CNN -> 입력 영상 x를 단어 임베딩 공간의 특징 벡터로 변환.
: 영상 x를 CNN에 입력해야 함.
