1. 기계 학습
1. 기계 학습의 훈련
- 주어진 문제인 예측을 가장 정확하게 할 수 있는 최적의 매개변수를 찾는 작업
- 개선하여 정량적인 최적 성능에 도달
2. 추론
- 훈련을 마치면, 추론을 수행
- 새로운(unknown) 특징에 대응되는 목표치의 예측에 사용.
3. 기계 학습의 필수 요소
- 학습할 수 있는 정량화된 데이터
2. 지도 학습
- 레이블이 지정된 데이터 세트를 사용하여 특정 작업을 수행하도록 알고리즘을 훈련
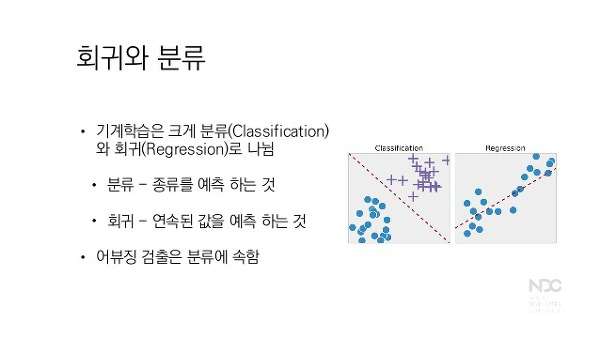
- 분류와 회귀로 나눔.
- 분류는 이산 변수에 대한 입력 데이터를 분류하도록 알고리즘을 훈련하는 곳
- 회귀는 가능한 연속 값 범위에서 출력을 예측하도록 알고리즘을 훈련하는 지도 학습 방법
-
선형회귀
-
어떤 요인의 수치에 따라 특정 요인의 수치가 영향을 받고 있을 때, 특정 요인의 수치에 영향을 주는 변수를 x, 영향을 받는 변수를 y라고 하자. 이때 선형 회귀는 한 개 이상의 x와 y의 선형 관계를 갖는다. (예를 들어 시험 공부하는 시간을 늘리면 성적이 올라가고, 집의 평수가 클수록 매매 가격은 비싸진다.)
-
직선 모델 y = wx + b 사용
-
-
로지스틱 회귀
-
선형 회귀와 유사 but 좀 다름.
-
회귀를 사용하여 데이터가 어떤 범주에 속할 확률을 0에서 1 사이의 값으로 예측하고 그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 지도 학습 알고리즘
-
종속변수가 0 또는 1이기 때문에 y=wx+b 을 이용해서 예측하는 것은 의미가 없다.
-
효율적이면서 쉽게 구현되는 편이다.
-
데이터를 두 개의 그룹으로 분류하는 문제에서 가장 기본적인 방법은 로지스틱 회귀분석
-
제품 테스트(성공 or 실패) 등에 사용된다. 우리는 카페 리뷰 분류(확률에 따라 긍정인지 부정인지 분류)에 사용하였다.
-
 (로지스틱 회귀 함수)
(로지스틱 회귀 함수)
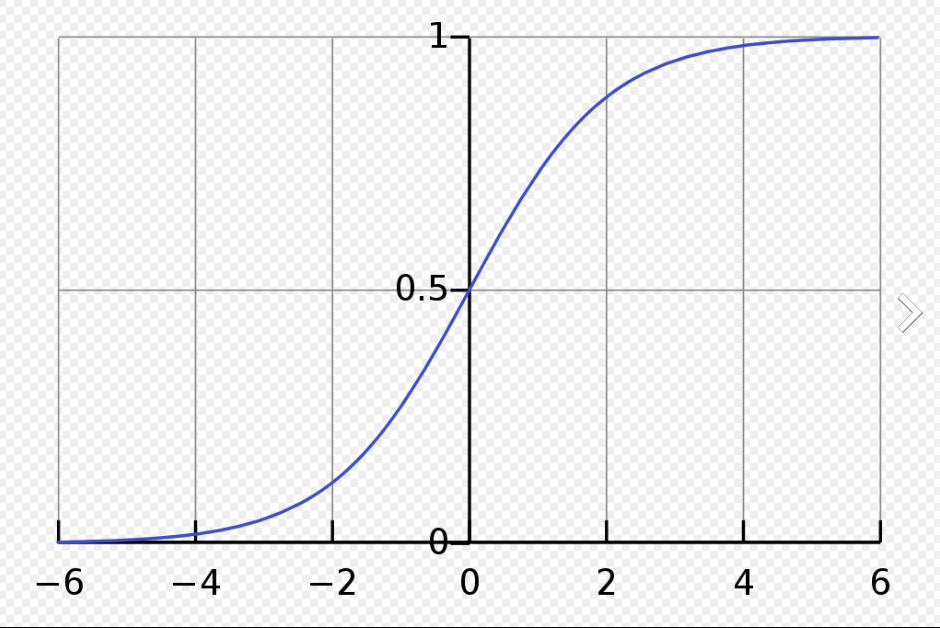
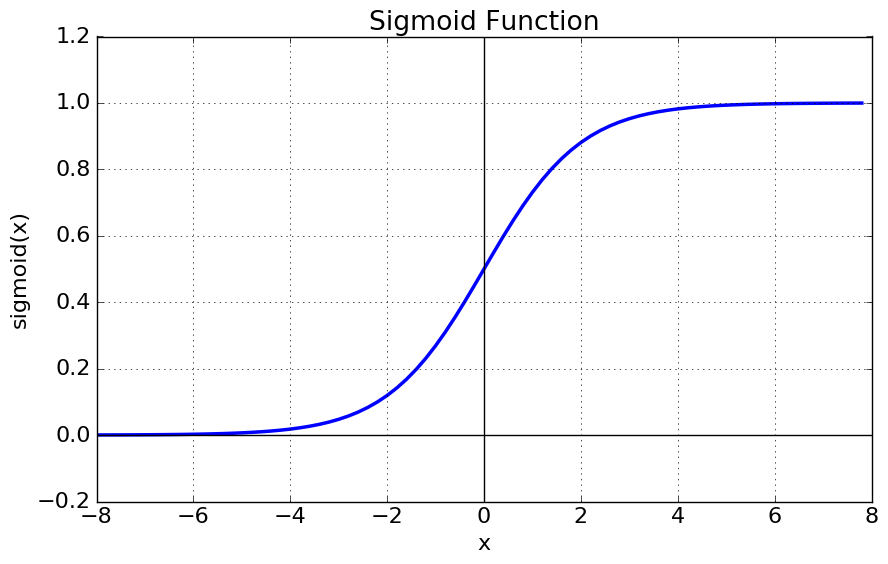
3. 시그모이드 함수
-
비선형 함수
-
실제 세계는 선형이 아니며, 잡음이 섞이기 때문에 우리는 비선형 모델이 필요하다.
-
출력을 0과 1로 이진 값만 반환, 그 사이에 있는 값은 무시.
-
일반적인 회귀분석에서는 우리가 원하는 것이 예측값(실수)이기 때문에 종속변수의 범위가 실수이지만 로지스틱 회귀분석에서는 종속변수 y 값이 0 또는 1
=> 로지스틱 회귀분석 할 때 시그모이드 함수를 사용하면 좋다
=> 카페 리뷰 긍/부정 분류할 때 시그모이드 함수를 사용하였다.
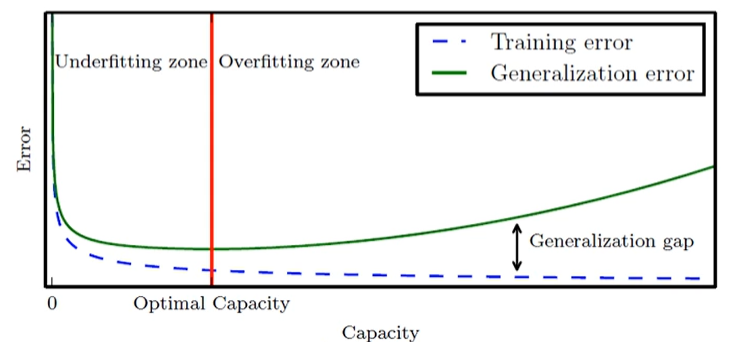
4. 과잉적합(과대적합)
-
훈련집합에 과몰입해서 단순 암기 했기 때문에 생기는 과잉적합 문제이다(학습 과정에서 잡음까지 수용해버린다).
-
훈련집합에 대해서는 거의 완벽하게 근사화하지만, 새로운 데이터를 예측한다면 문제가 발생한다.
-
로지스틱 회귀는 과적합에 취약하다.
-
우리는 과적합을 막기 위해 적절한 용량의 모델을 선택하는 모델 선택 작업이 필요하다.
=> 모델 선택 작업을 위해 early stopping(조기 종료)을 사용한다. -
early stopping: 모델이 과적합되기 전 훈련을 멈추는 정규화 기법. 훈련 중 주기적으로 성능 검증을 하다가 성능이 더 좋아지지 않으면 과적합이라 판단하고 훈련을 멈춘다. 일시적 변동이 아닌 지속적인 정체 또는 하락에 의한 판단에 종료한다.
- 1~4 정리
=> 우리는 기계 학습을 통해 카페 리뷰가 긍정인지, 부정인지를 기계가 추론할 수 있도록 하였다.
=> 이때 데이터를 두 개의 그룹으로 분류하는 문제에서 가장 기본적인 방법인 로지스틱 회귀분석을 사용하였다.
=> 로지스틱 회귀분석에 맞게 시그모이드 함수를 사용하였다.
=> 로지스틱 회귀가 과적합에 취약하다는 점에서 early stopping을 사용한다.
5. 워드 임베딩
-
언어 벡터화 과정. 언어(자연어)는 수치화되어 있지 않으므로 벡터로 만들어 주어 기계가 활용할 수 있도록 하는 것.
-
가장 기본적인 벡터화의 방법은 One-hot encoding 방법이다. 예를 들어, 남자와 여자를 표현하는 벡터를 만든다고 할 때 각각을 [1,0][0,1]로 만드는 방법이다. 그런데 이 방법은 단어가 많아지면 벡터 공간이 매우 커지므로 매우 비효율적이다. 또 이런 표현방식은 단어가 뭔지만을 알려줄 뿐 어떤 특징을 표출해주지는 못한다. 이런 방식을 Sparse(희소)한 표현법이라고 한다.
-
따라서, 이를 해결하기 위해 Dense 한 표현법이 제시되었다. Dense 한 표현방식은 단어의 수에 상관없이 특정 차원의 벡터로 변환시켜 단어의 특성이나 유사성을 나타내 준다.
6. LSTM
-
Long Short Term Memory
-
RNN(Recurrent Neural Network, 순환신경망)의 한 종류
-
RNN
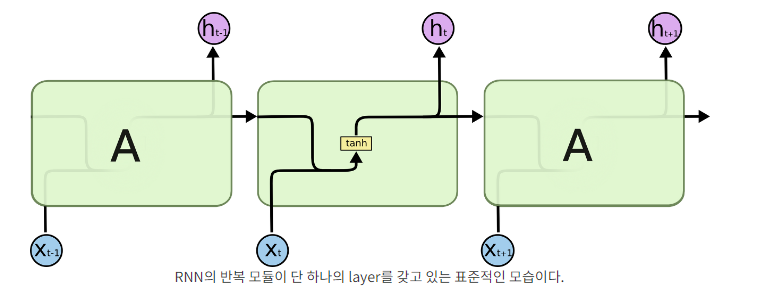
RNN은 스스로를 반복하면서 나중에 일어나는 사건을 생각하기 위해 이전 단계에서 얻은 정보가 지속되도록 한다. 하지만 RNN은 긴 시간 의존성 문제가 있다. 예측을 위해 더 많은 문맥을 필요로 하는 경우, 필요한 정보를 얻기 위한 시간 격차가 굉장히 커지는 것이다.
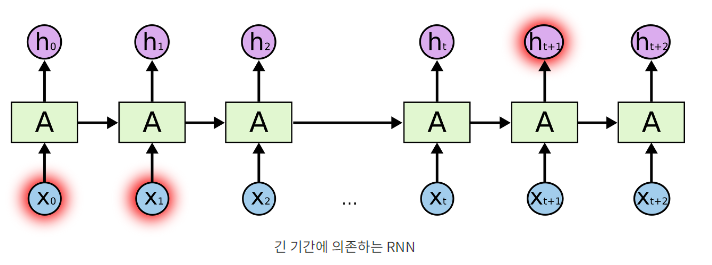
-
하지만 LSTM은 긴 의존 기간을 필요로 하는 학습을 수행할 능력을 갖고 있다. 즉, LSTM은 긴 시간 동안의 정보를 기억하는 것을 모델의 기본으로 하는 것이다.
=> LSTM은 셀의 정보를 어떤걸 기억하고 어떤것을 잊을지 결정하는 알고리즘 -
단순한 neural network layer 한 층 대신에, 4개의 layer가 특별한 방식으로 서로 정보를 주고 받도록 되어있다.
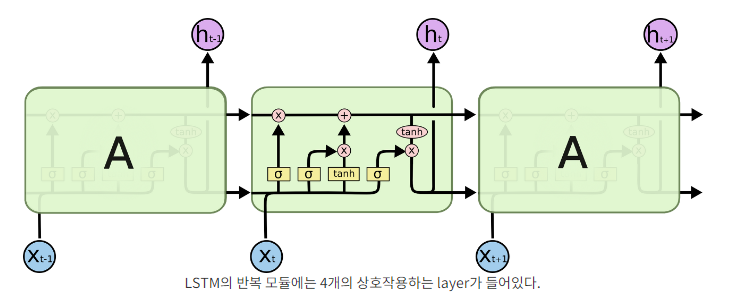
-
cell state: 전체 체인을 계속 구동시킴.
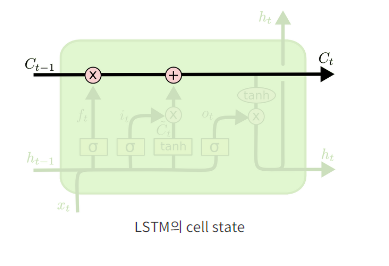
-
개폐구(Gate, 아래 사진.): 정보가 전달될 수 있는 추가적인 방법. LSTM은 표준 RNN과는 다르게 3개의 gate를 가지고 있고, 이들은 cell state를 보호하고 제어한다. 기본적으로 LSTM은 입력 개폐구와 출력 개폐구를 이용하여 입출력을 제어한다. 또한 LSTM은 개폐구를 이용하여 영향력의 범위를 확장한다.
-
LSTM 핵심요소
1) 메모리 블록(셀): 은닉 상태 장기 기억
2) 망각 개폐구: 기억 유지 혹은 제거
3) 입력 개폐구: 입력 연산
4) 출력 개폐구: 출력 연산
=> 단순 RNN 대신 LSTM을 카페 리뷰 분석에 활용하고자 하였다.
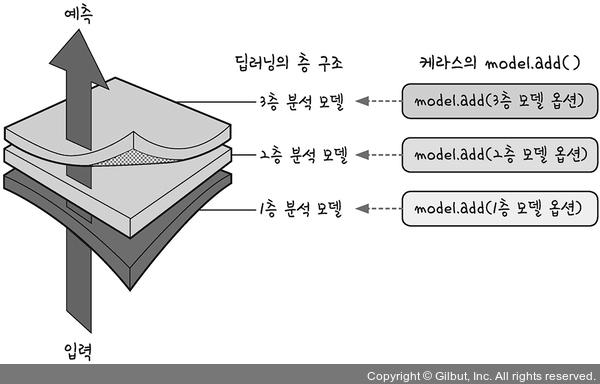
7. Sequential
- 신경망 모델을 만드는 방식 중 하나
- 순차적으로 레이어를 더해주기 때문에 순차모델이라 불린다.
- 만들기 쉽다.
8. embedding_dim & hidden unit
-
embedding_dim: 결과로서 나오는 임베딩 벡터의 크기
-
hidden unit: hidden layer를 구성할 때의 Unit 갯수. 많아지면 많아질 수록 좋은 결과. 하지만 연산이 복잡해짐. 그러므로 적절하게 설계해야 함. 정해진 답이 있는 것은 아님.
9. binary cross entropy loss
-
이진 분류란, 데이터가 주어졌을 때, 해당 데이터를 두 가지 정답 중 하나로 분류하는 것을 의미한다.
-
이러한 이진 분류에는, Binary Cross Entropy Loss(이진 교차 엔트로피 손실) 함수를 활용할 수 있다.
- 5~9 정리
=> 우리는 워드 임베딩에서 Dense한 표현법을 사용해 주었다.
=> 또한 우리는 RNN의 한 종류인 LSTM을 사용하였다.
=> 모델 제작을 위해 순차적으로 레이어를 더해주는 Sequential 을 사용하였다.
=> 우리는 embedding_dim = 100 / hidden unit = 128로 설정하였다.
=> 카페 리뷰의 긍정, 부정 분류는 이진 분류이므로, 우리는 Binary Cross Entropy Loss 함수를 사용해 보았다.
++추가
1) 케라스 모델에서 load_model을 가져왔다. 모델을 불러오기 위해서다.
2) keras.callbacks에서 ModelCheckpoint를 가져왔다. 학습 중인 모델을 자동으로 저장해주기 위해서다.
3) 한국어 형태소 분석을 위해 한국어 처리 패키지인 KoNLPy에서 okt(open korean text)를 가져왔다.
https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
