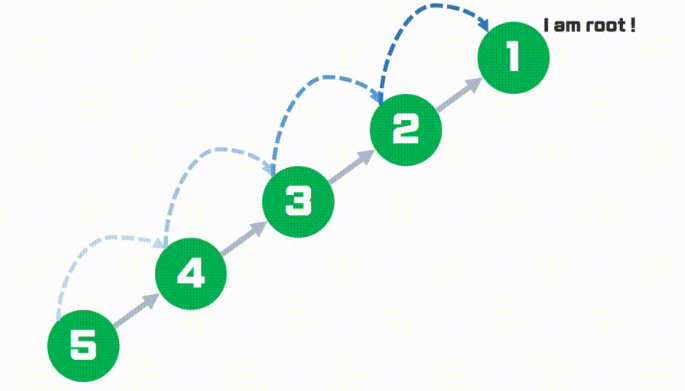
일반적으로 Find 연산은 부모 노드를 재귀를 통해 찾아나간다. 또한 Union 연산은 특별한 기준없이 어느 한쪽에 합쳐지게 된다.
하지만 매번 find 를 수행한다면 root 노드를 계속해서 찾아나가는 불필요한 연산을 계속 하게되는 것이다. 또한 Union 연산시, 아무렇게나 그래프를 합친다면 트리의 높이가 비효율적으로 늘어나서 최악의 경우 O(N)의 시간복잡도를 보이게 된다.
이를 개선하기 위한 방법에는 2가지가 있다.
1. 경로압축(Path-Compression)
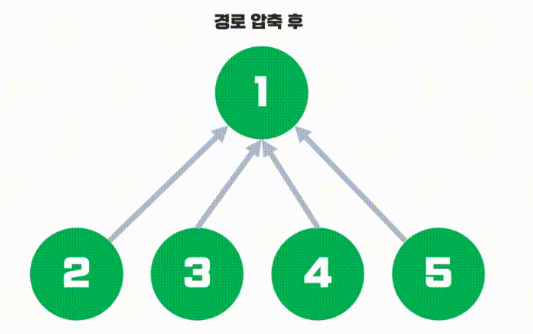 위 그림과 같이 find 을 한번 수행할때, 방문하는 해당 노드의 부모를 root 노드로 갱신시켜주는 것이다.
위 그림과 같이 find 을 한번 수행할때, 방문하는 해당 노드의 부모를 root 노드로 갱신시켜주는 것이다.
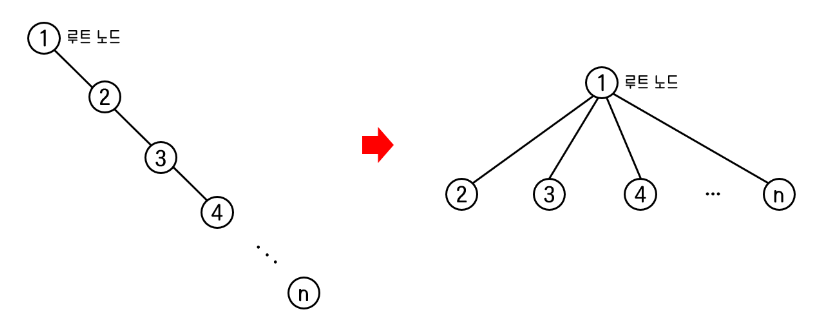
그 결과 경로를 압축한 노드들에 대해서는 부모 노드가 이미 root로 갱신된 상태이므로 또 다시 재귀를 통해 root 노드를 찾아나서는 비용을 아낄 수 있다.
탐색에 드는 시간 복잡도는 O(N)에서 O(longN)으로 단축되는 것이다.
아래와 같이 구현할 수 있다.
public static void find(int[] set, int i) {
if(set[i] == i) {
return i;
}
set[i] = find(set, set[i]); // 재귀를 통해 알아된 root 노드로 갱신시켜준다.
}2. Union : Union By Rank
트리 탐색에 있어서 트리의 높이는 시간복잡도 측면에서 중요한 요소이다.
따라서 그래프를 합칠때, 어느쪽 그래프에 합쳐질지는 중요하다.
결론적으로 "트리의 높이(Rank)가 높은 곳에 합쳐져야한다."
예시로 알아보자.
집합A의 높이는 3이고, 집합B의 높이는 2이다.
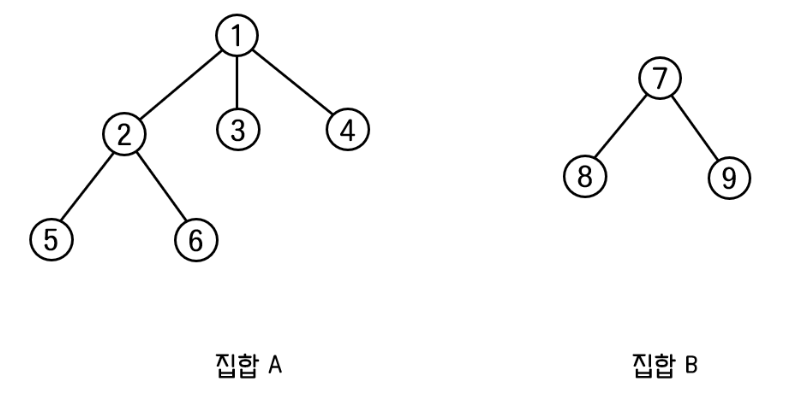
먼저 집합A를 집합B에 합쳐보자.
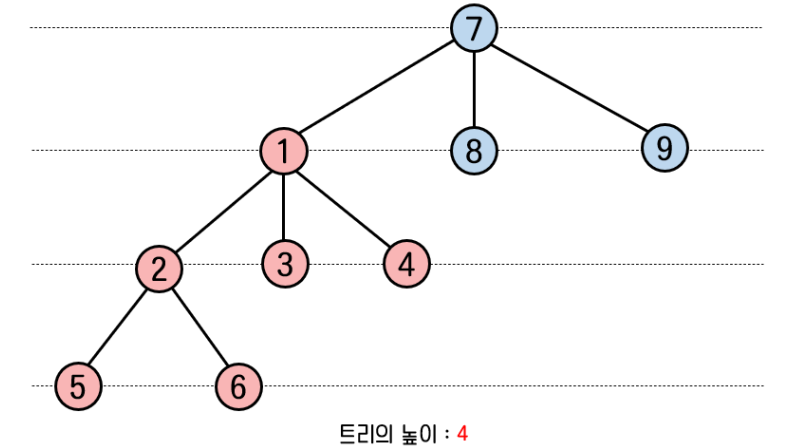 트리의 높이는 4가 되었다.
트리의 높이는 4가 되었다.
다음으로는 집합B를 집합A에 합쳐보자.
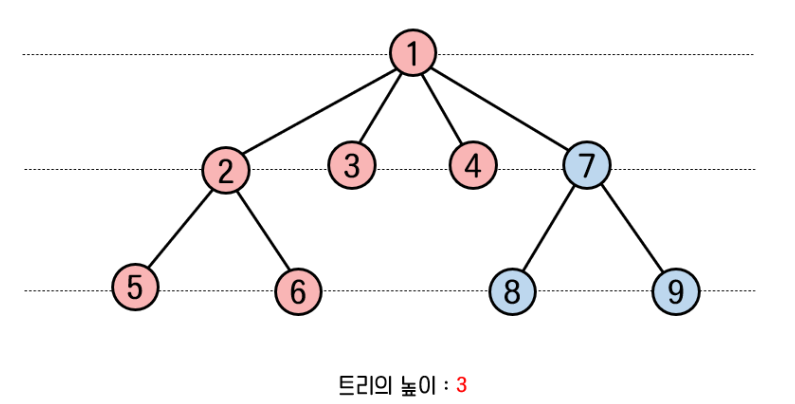 트리의 높이는 3이 되었다.
트리의 높이는 3이 되었다.
위의 결과를 보면, 트리의 높이가 더 큰 집합으로 합쳐질때가 높이가 더 작다는 것을 알 수 있다.
예시에서는 높이 차가 1이지만, Union연산에 의해 높이 차가 증가되면서 이것은 나중에 큰 차이를 보일 것이다.
public static void union(int v1, int v2) {
int a_parent = find(v1);
int b_parent = find(v2);
if(a_parent == b_parent) {
return;
}
if(rank[a_parent] < rank[b_parent]) {
parent[a_parent] = b_parent;
} else if(rank[a_parent] > rank[b_parent]) {
parent[b_parent] = a_parent;
} else if(rank[a_parent] == rank[b_parent]) {
parent[a_parent] = b_parent;
rank[a_parent]++;
}
}다음과 같이 구현할 수 있다.
전체 코드로 Disjoint Set의 Union-Find 연산 코드를 작성해보자.
public static class DisjointSet {
int[] parent; // 부모 노드 정보
int[] rank; // 트리의 높이 정보
public DisjointSet(n) { // 생성자
parent = new int[n];
rank = new int[n];
}
public void makeSet() { // 초기화
for(int i=0; i<n; i++) {
parent[i] = i;
rank[i] = 0;
}
}
public void find(int v) { // root 노드를 찾는다.(경로 압축 시행)
if(parent[v] == v) {
return v;
}
return parent[v] = find(parent[v]);
}
public void union(int v1, int v2) { // 집합을 합친다.(Union by Rank 시행)
int a_parent = find(v1);
int b_parent = find(v2);
if(a_parent == b_parent) {
return;
}
if(rank[a_parent] < rank[b_parent]) {
parent[a_parent] = b_parent;
} else if(rank[a_parent] > rank[b_parent]) {
parent[b_parent] = a_parent;
} else if(rank[a_parent] == rank[b_parent]) {
parent[a_parent] = b_parent;
rank[a_parent]++;
}
}
}
다음편
이를 활용한 "크루스칼 알고리즘"이 있다고 한다. 다음편에 파헤쳐보자.
