
선택정렬
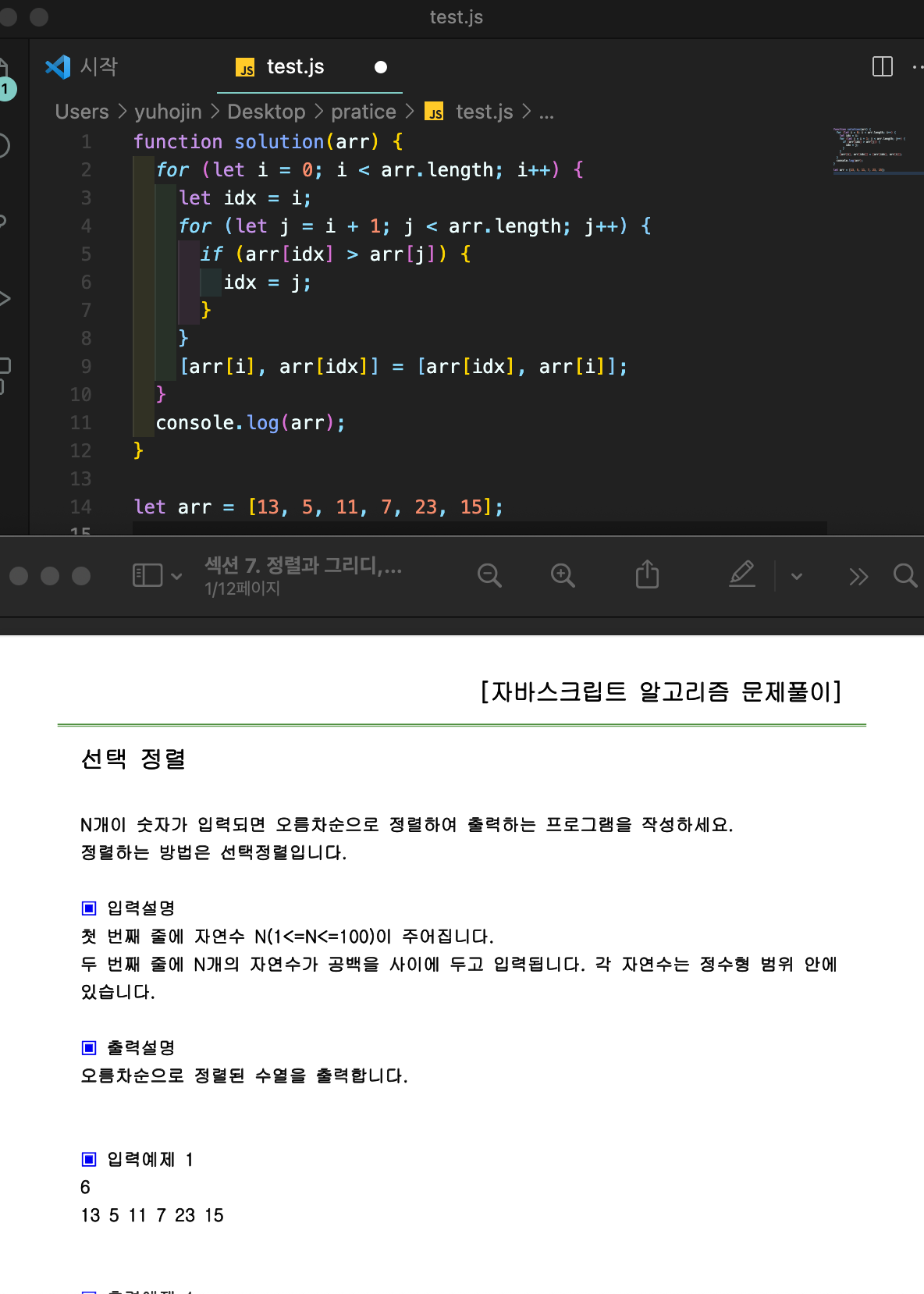
- 사실 sort를 사용하면 간편하게 되지만 직접 정렬을 하는 방법이다..
For 문을 통해서 가장 작은값부터 앞으로 꺼내오는 방법이다.
버블정렬
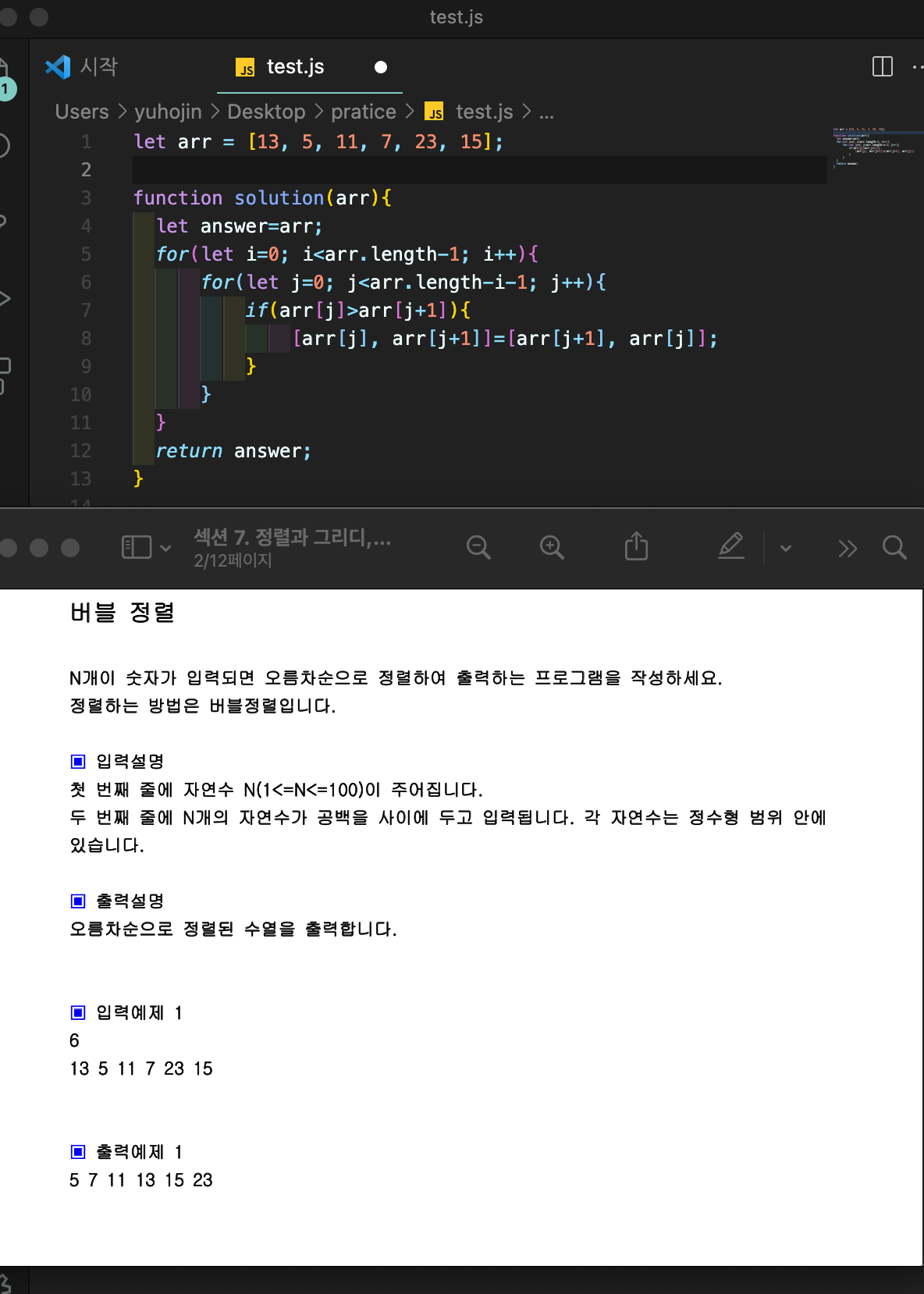
- 선택 정렬에 비해서 비효율적인 정렬법이라고 생각한다.
하나하나를 다음 인덱스와 비교해서 크기가 크면 바꿔주는 방법이다.
선택정렬, 버블정렬 -- 차이점
가장 큰 차이점은 효율성이다
둘다 배열을 돈다는 점에서는 똑같지만 얼만큼 도냐의 차이이다.
선택 정렬 같은 경우에는 가장 작은 값을 앞쪽으로 설정하기 떄무에 계속해서 돌아야 하는 값이 적어지지만
버블 정렬은 계속해서 0부터 돌기 떄문에 돌아야 하는 값이 고정적이다.
- 효율성을 고려 해서라도 선택정렬을 사용하는 것이 옳다!!
- 이 외에도 다양한 정렬이 있다!!
LRU
살짝 어려웠던 문제이다..
- 이유는 머리가 안돌아갔다
- 문제를 어떻게 해결해야하는지는 이해 했지만 이상하게 머리가 안돌아가지고;;

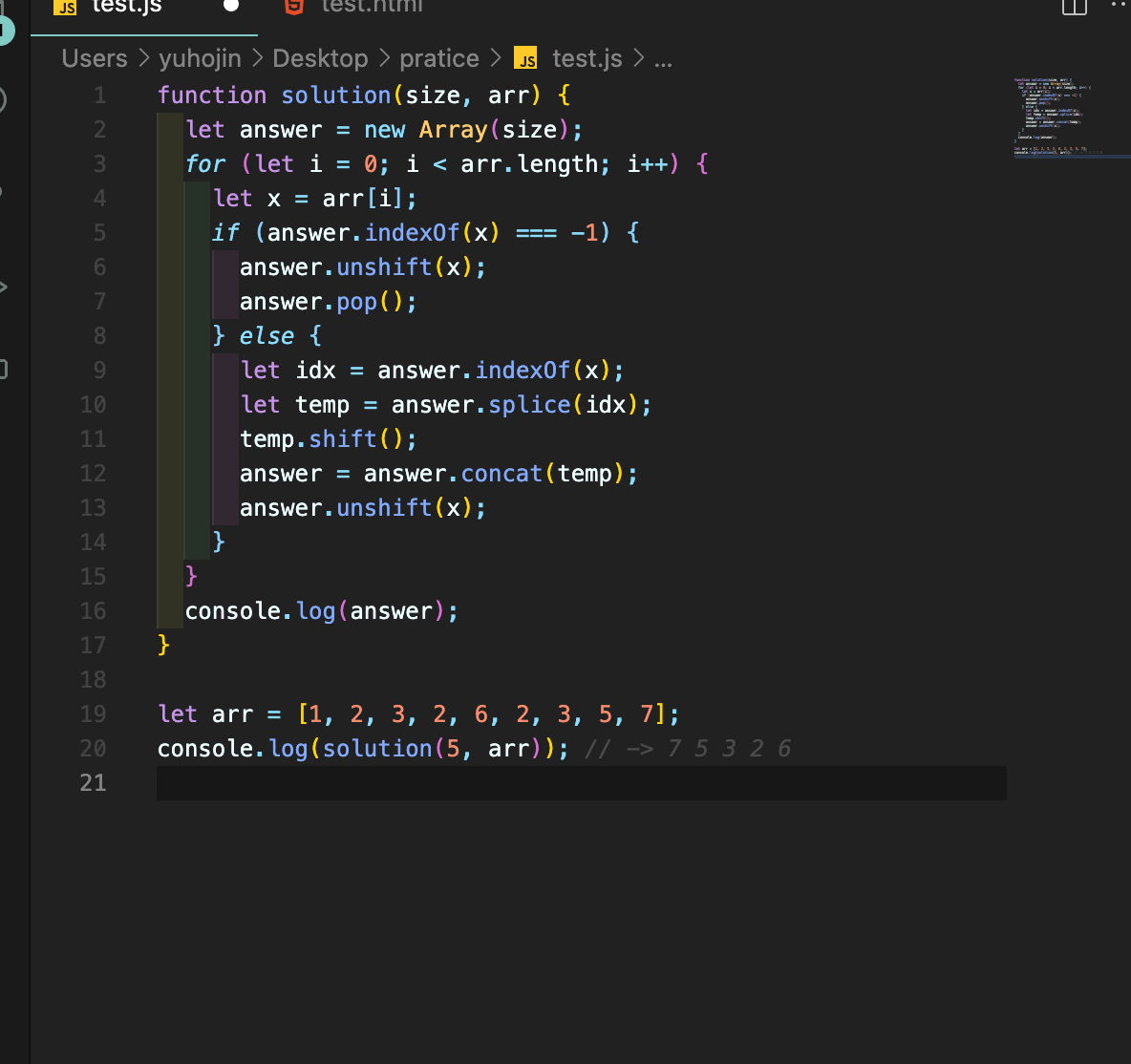
내 코드 같은 경우에는 고차 함수를 사용해서 해결했지만 강사님 코드 같은경우에는 for문을 통해서 해결 하셨다.
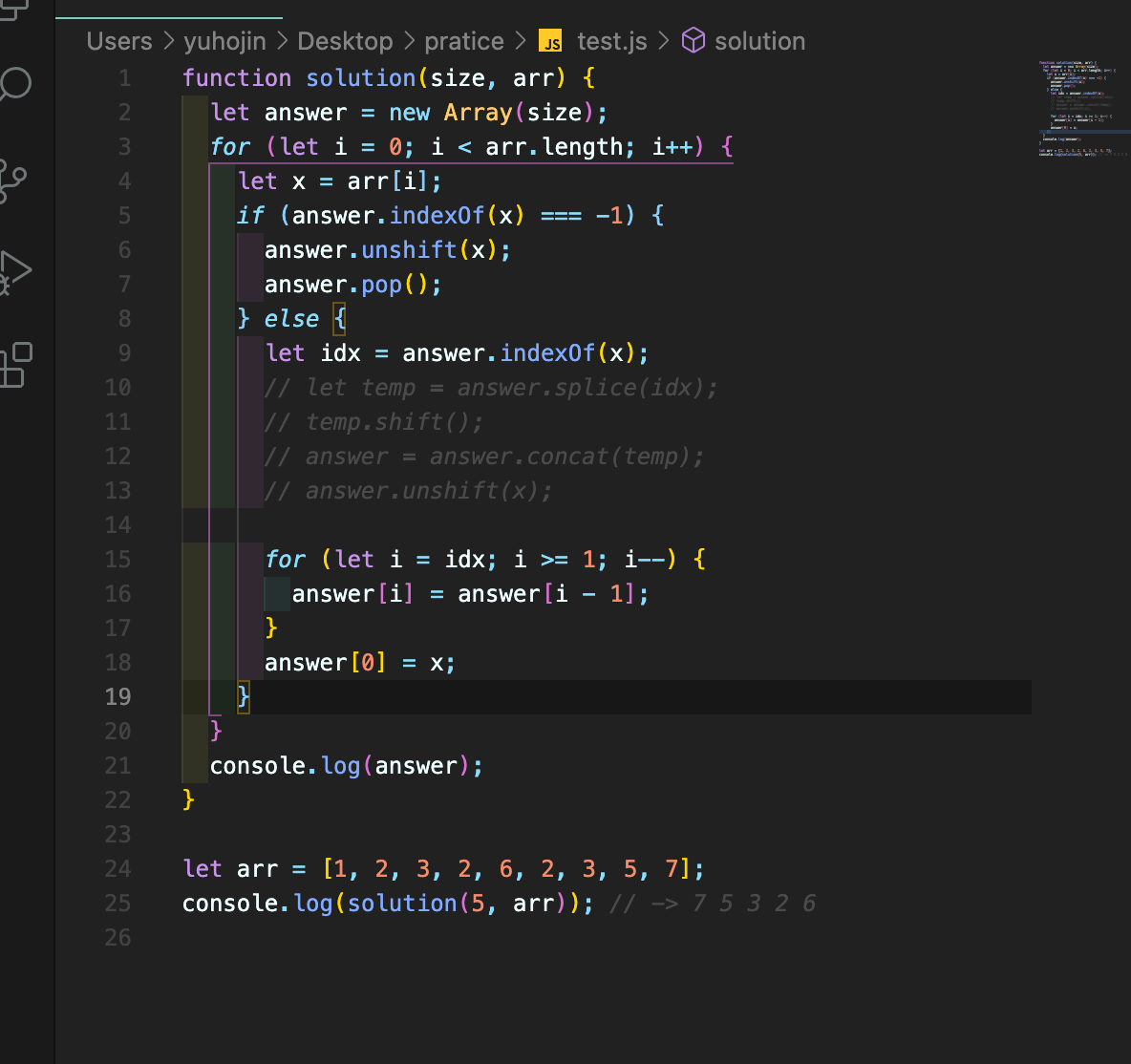
- 실제 강사님 코드는 foreach를 사용했지만 내가 크게 다른점이 있다고 느끼는 부분만 수정을 해보았다
장난꾸러기 현수

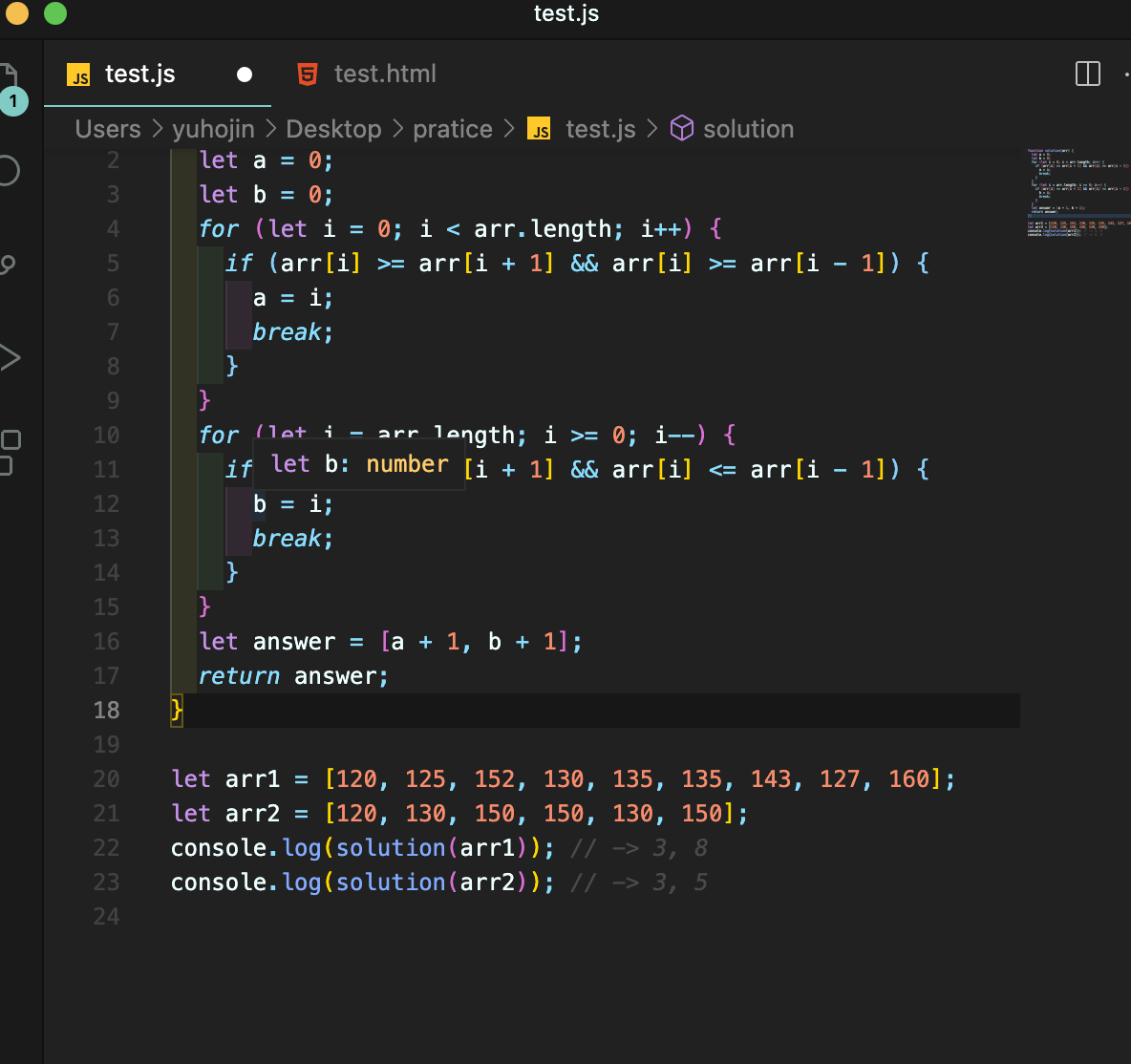
간단하게 해결을 하였다
연속으로 걸릴수 있기 떄문에 한쪽은 앞에서 한쪽은 뒤에서 시작해서 한번 걸리면 break처리를 해주었다.
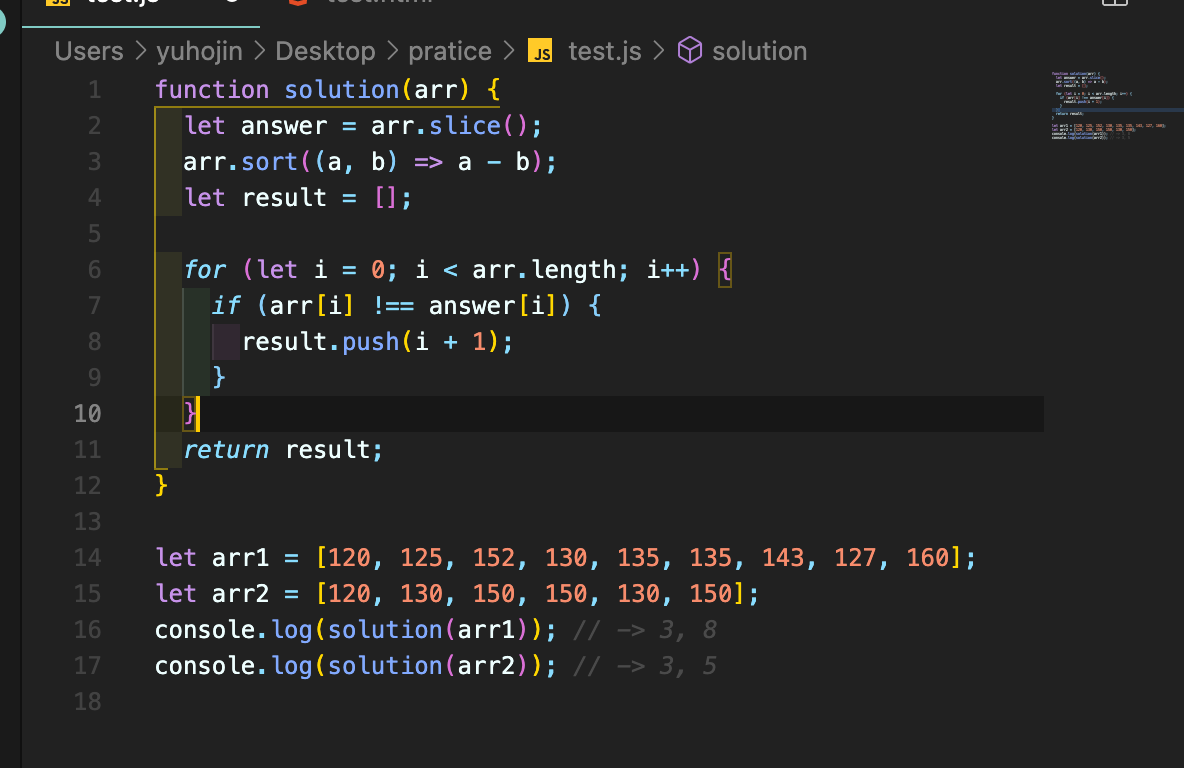
강사님 코드이다...
기존 배열을 복사한뒤 기존 정렬은 정렬후 서로 다른 값이 있을떄의 index값을 넣는 방법이다.. 매우 간결하교 효과적인 방법인것 같다.
2차원 배열 정렬

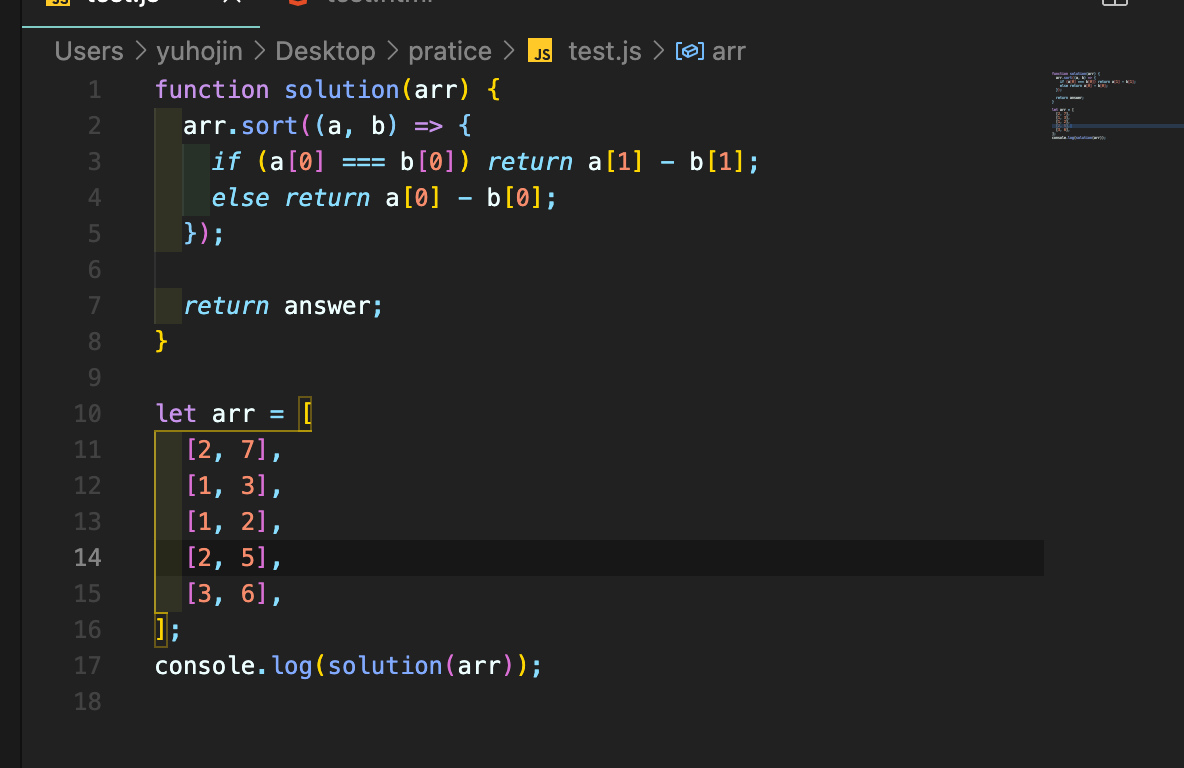
개인적으로 sort를 사용하지 않고 구현을 해보려다가 굳이 그럴 필요가 있나 해서 sort를 사용했다.
강사님의 코드를 가져왔으며 참고해볼 사항이라고 생각한다.
난 sort가 어떤식으로 작동하는 지는 모른다... 단순히 a,b를 저런식으로 사용하면 오름차순으로 정렬이 된다 정도만 알고 있다.
회의실 배정

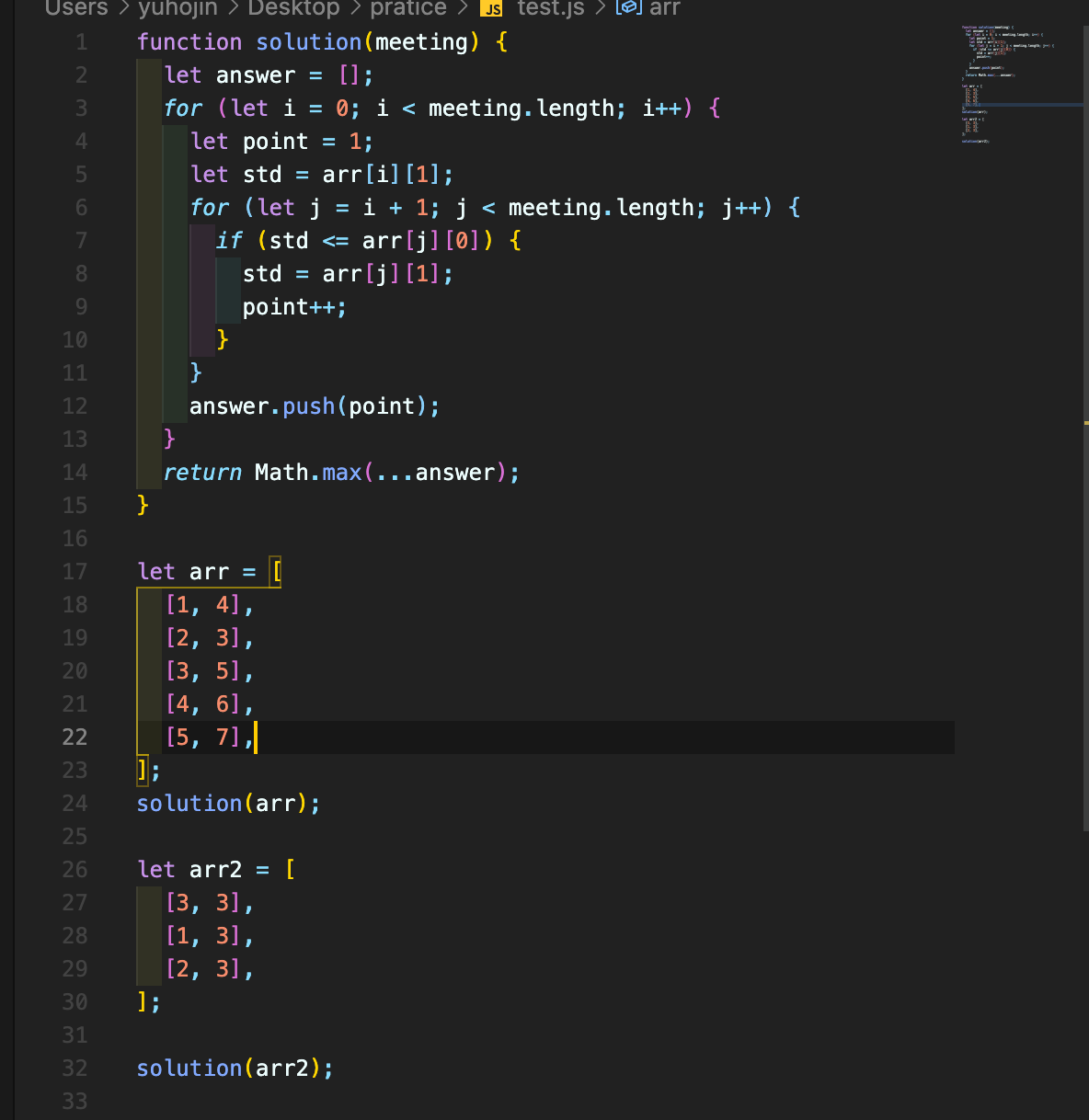
강사님과 코드는 다르지만 비슷한 해결법으로 해결을 하였다!!
결혼식 인원 배정

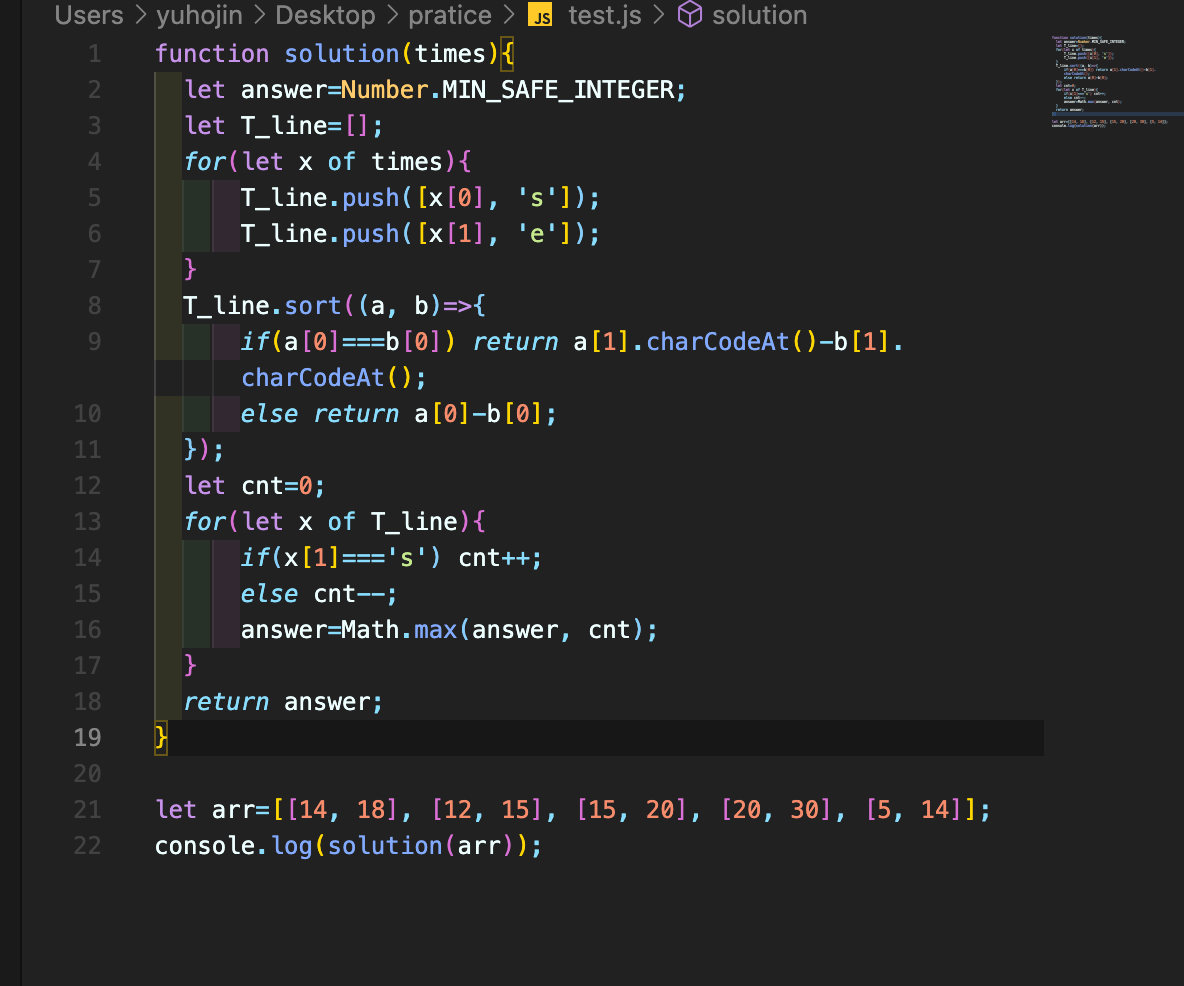
- 생각지도 못한 풀이 법이였다...
일단 숫자에 따른 정렬을 한뒤에 알파벳 숫자에 대한 정렬까지 해준 방법이다 .
charCodeAt()는 아스키코드로 변환하는 것을 의미한다.
이후 값을 더해주고 뺴고를 반복하면서 결과값을 계속해서 갱신해주었다.
- 두고두고 보면 좋을방법이다!!
이분 검색(탐색)

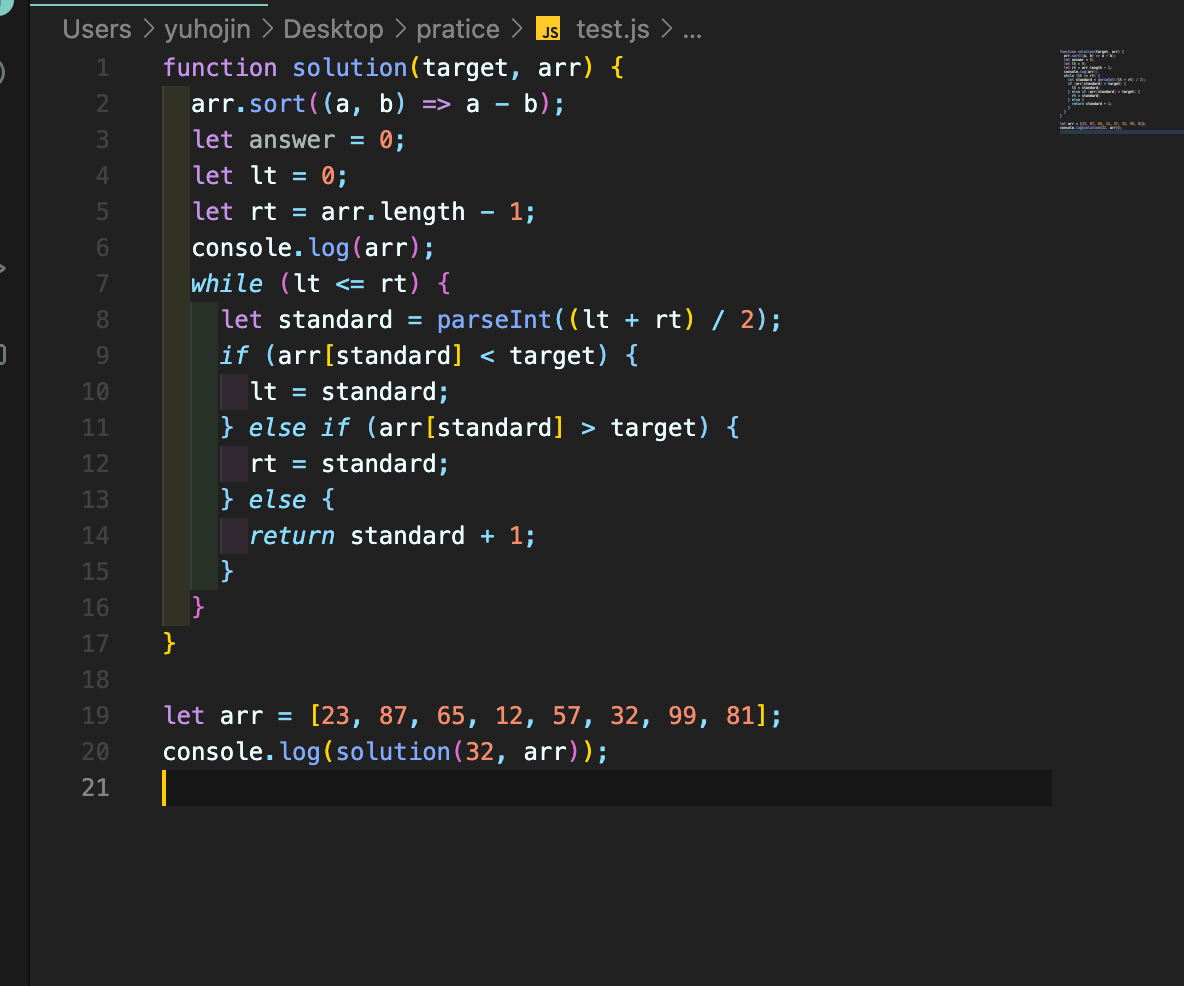
이분 탐색이란 기준 점을 잡고 그 값보다 크냐 작냐 또는 같냐를 판별한뒤 계속해서 중간값을 확인하는 방법이다.
이처럼 중간값을 계속해서 parseInt를 통해서 설정해주고 해당 값이 같은지 다르면 다른 설정을 해주는 코드이다.
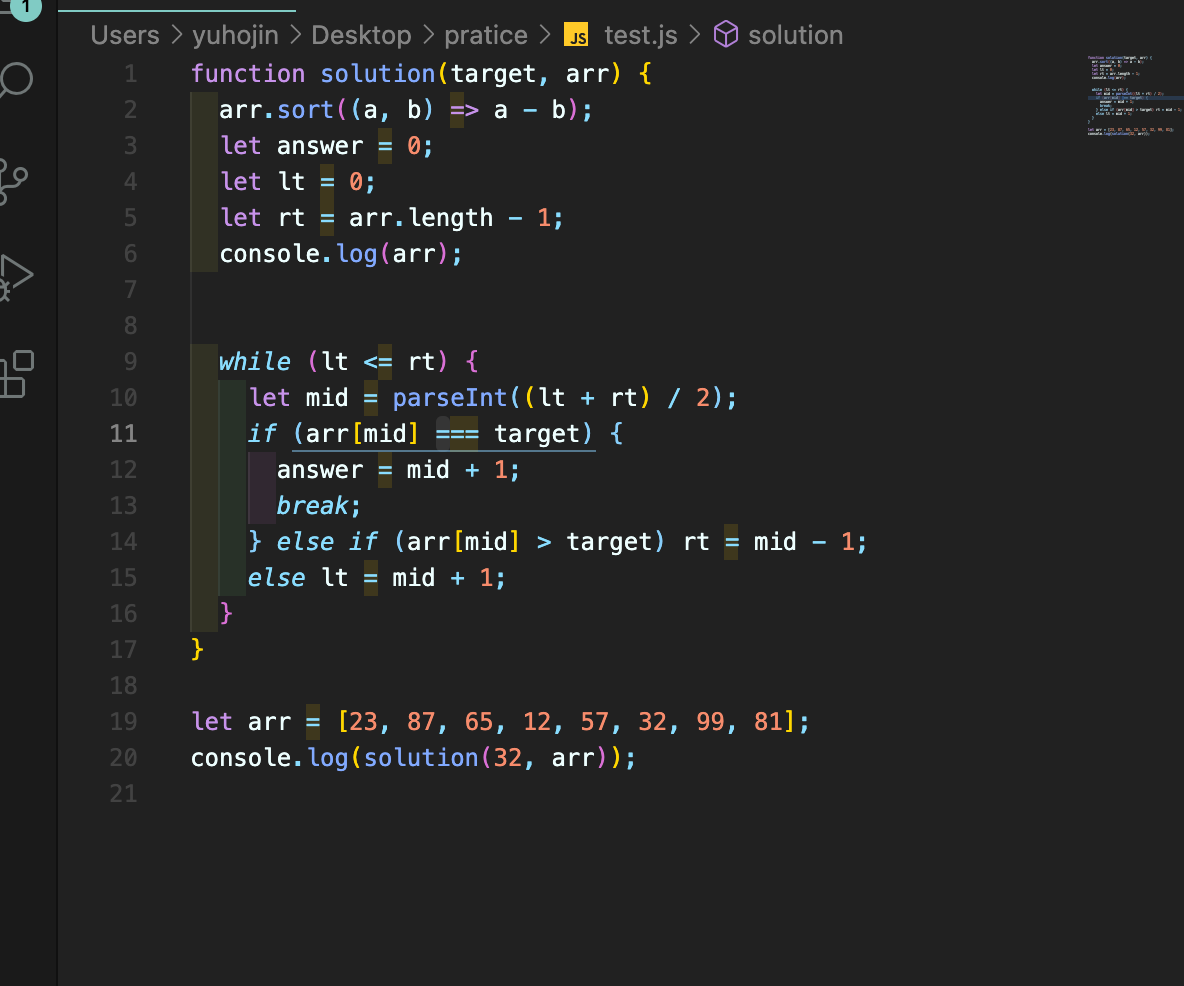
강사님 코드와 다른점은 단순히 if문의 설정방법이다.
결과는 같다.
뮤직 비디오
- 인강 확인

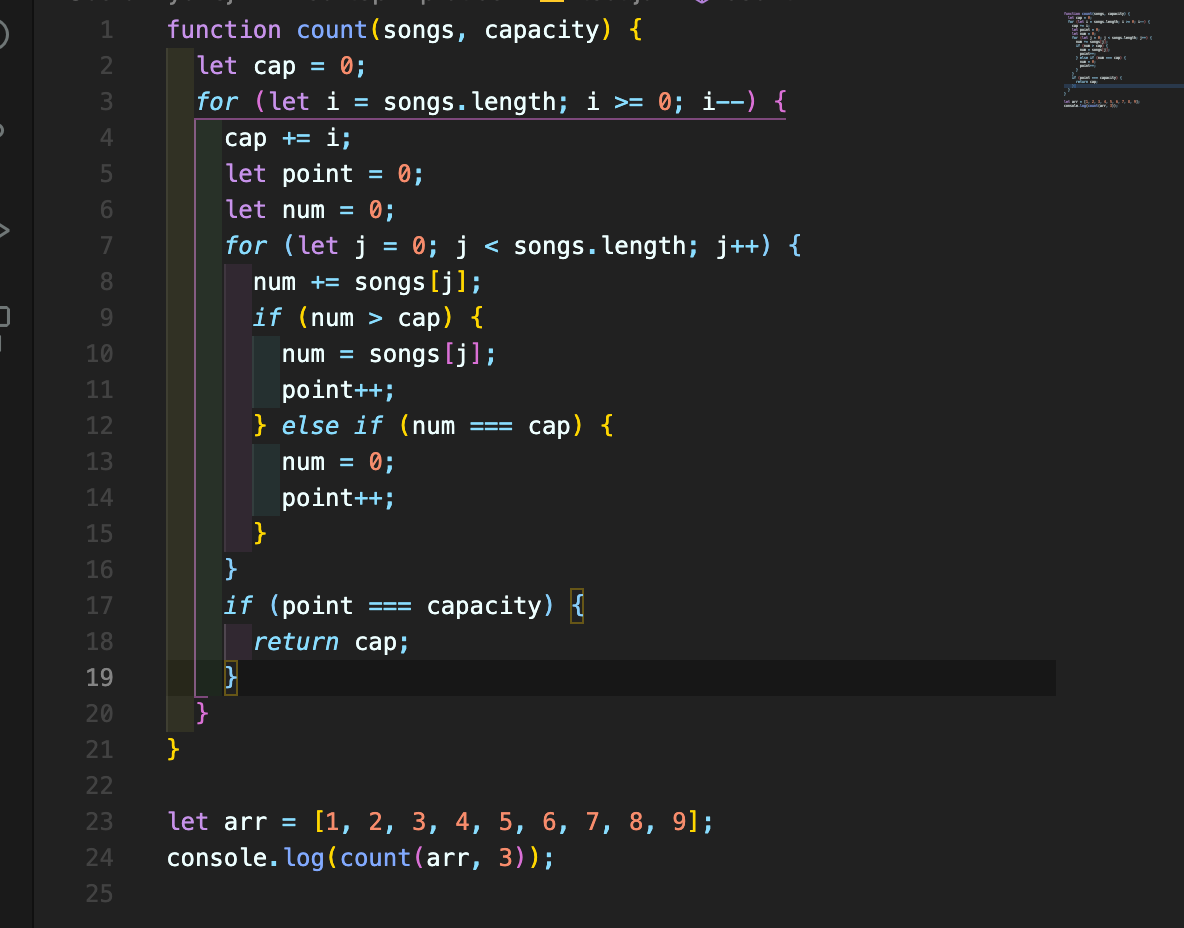
문제 해결은 하였다.
- 맞는 지는 모르지만..
일단 정렬이 되어있다는 것을 가정하면 맨 뒷숫자부터 큰 값이 있을 것이기 떄문에
그 큰 값을 하나하나 더해가면서 용량을 설정하였고 원하는 capacity가 되었을떄에 그 용량 값을 return하는 로직이다.
중요한 점은 num의 처리이다.
용량보다 클떄랑 같을떄랄 다르게 처리해야 하는데 그 이유는
용량보다 클떄에는 따로 point를 증가하고 새로운 값에 바로 넣어줄 것이기 떄문이다.
이 문제는 원래 이진 탐색 = 이분 탐색 으로 해결을 하셨지만 나는 별로 선호하는 방법이 아니라서 이렇게 해결을 하였다.
