
🚀 Amazon S3 액세스 로그
S3에 액세스하여 파일을 GET할떄마다 로그를 남기는 것을 말합니다.
많이 부분에서 사용하는 기능으 안하지만 예를들어 감사 목적으로 또는 데이터 분석을 할떄에 사용이 됩니다.
- 나중에 확인할 것이지만 로그 자체를 보는것을 어렵기 떄문에 여기에서
Amazon Athena를 부수적으로 활용하기도 합니다.
몇가지 주의해야 할점, 이론적인 점은 다음과 같습니다.
1. 버킷의 로그를 찍는거는 액세스 로그를 허용한 시점 이후에 로그가 찍힙니다.
- 말 그대로 이전에 있던 파일에 대한 로그는 찍히지 않습니다.
2. 모니터링 중인 버킷을 로킹 버킷으로 설정하면 안됩니다.
- 이는 매우 중요한 사항으로 로깅 루프라는 것이 생기게 되고 이로 인해서 버킷의 크기가 기하급수적으로 증가하게 됩니다.
- 이로인해 어마어마한 비용이 지출되니 매우 조심해야할 사항입니다.🚀 Amazon S3 액세스 로그 실습
일단 아무런 버킷이 없는 상태에서 2개의 버킷을 생성해 줍니다.
- 하나는 파일 저장 버킷, 하나는 로그 버킷 입니다.
버킷 설정은 아무런 변경없이 그대로 만들어 줬습니다.
이후 파일 저장 버킷으로 이동해 속성탭에서 서버 액세스 로깅을 활성화 시켜줘야합니다.
이떄 활성화를 시도하면 파일 저장을 할 대상의 버킷을 입력해 주어야 하고 여기에 로그 저장 버킷의 주소를 입력해 주면 됩니다.
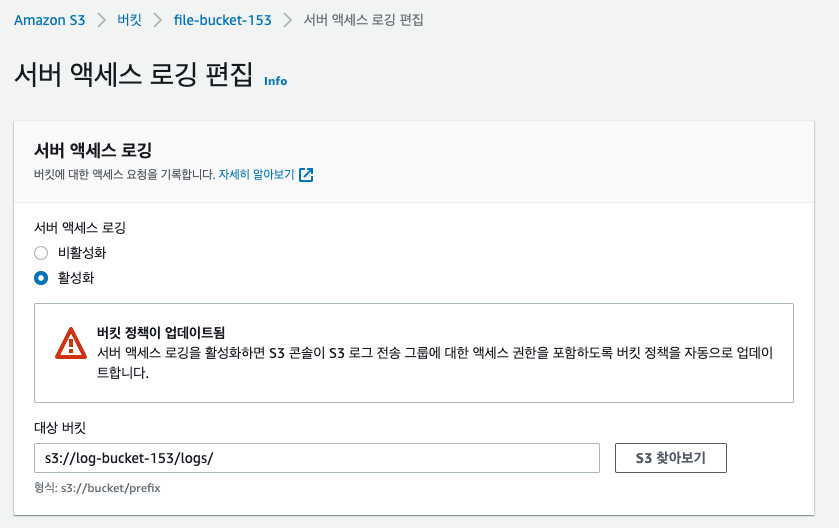
- 경로 같은 경우에는 마음대로 해도 됩니다.
- 하지만 반드시 마지막에는
/를 추가해 주어야 합니다. - 앞서 말했듯이 저는 File Bucket에서 Log Bucket에 로그를 남기는 것 입니다. 자기 자기의 버킷을 선택하지 않도록 주의해야 합니다.
이후 파일 버킷에 파일을 업로드 하고 해당 파일을 열어봅니다.
- 파일을 열어볼떄 트래픽이 발생하기 떄문에 이후 로그가 log bucket에 찍히게 될 것입니다.
- 로그 같은 경우에는 바로바로 찍히지 않습니다.. 1~2시간 정도가 소요가 됩니다.
여기에서 의문점이 생길 수 있습니다.
어떻게 파일 버킷에서 로그 버킷에 기록을 남길 수 있을까요??
AWS의 최소권한 정책으로 인해서 따로 설정해 주지 않으면 다른 서비스에 영향을 끼칠수가 없습니다.
하지만 가능한 이유는 다음과 같습니다.
위에 경고창을 확인해보면 액세스 권한을 포함하여 정책을 자동으로 업데이트 한다고 합니다.
그러면 자동으로 정책이 추가 되었기떄문에 따로 권한을 주지 않아도 쓰기가 동작을 하는 것을 알수 있습니다.
- 이것을 확인하고자 한다면 Log Bucket으로 들어가 버킷 정책을 확인해 보면 됩니다.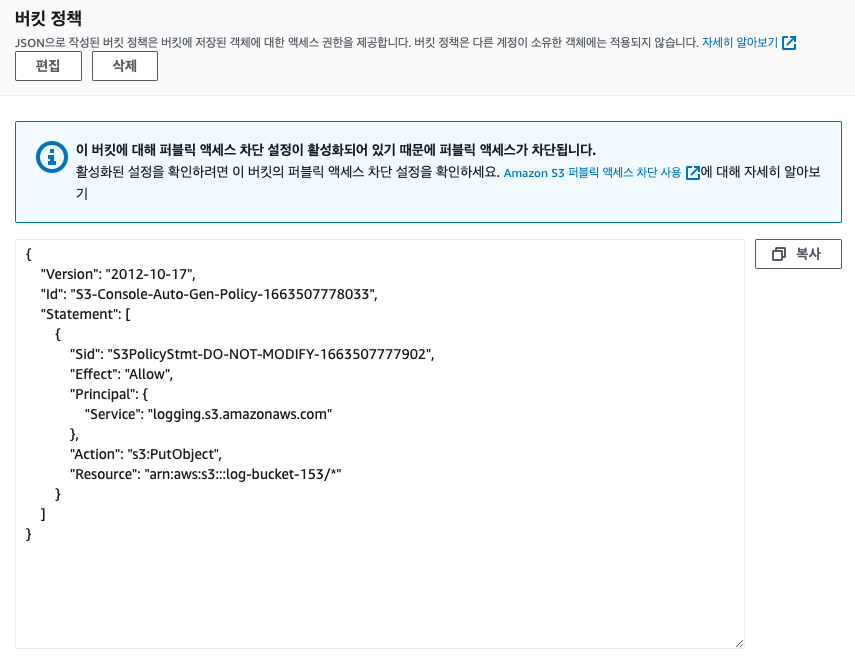
- 이처럼 버킷 정책이 알아서 추가가 됩니다.
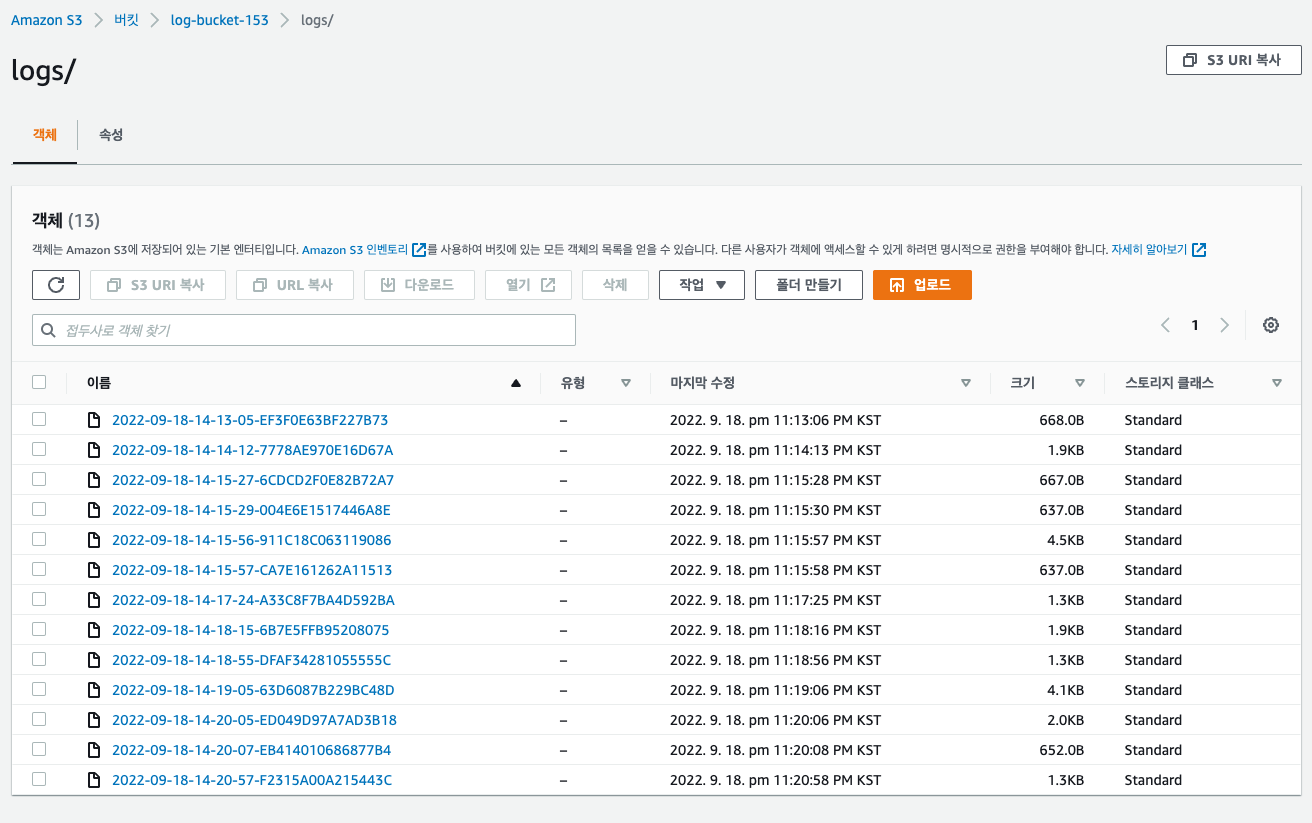
- 이후 로그가 추가된 모습입니다.
Youtube : https://www.youtube.com/watch?v=dpUhtlLjk_I
🚀 S3 CRR & SRR
S3에서 파일을 공유하고 복사하는 기능을 말합니다.
두가지로 나눠질 수가 있는데
CRR: 다른 리전 간 복제SRR: 동일 리전 간 복제
이렇게 구성이 됩니다.
이러한 기능을 활용하기 위해서는 두 버킷 모두 버저닝이라는 기능을 활성화 시켜줘야하며
복제 자체는 비동기적으로 일어나기 떄문에 아주 빠르게 동작합니다.
또한 IAM역할을 지정해 주어야 하는데 이는 실습에서 알아보도록 하겠습니다.
복제에서 중요한 점은 이와 같습니다.
- 이전에 있는 파일은 무시한다.
- 서로 연결을 해놓지 않은 상태에서 업로도된 파일은 복제하지 못합니다.
- Delete요청 같은 경우에는 활성화 할지를 옵션으로 설정 가능하다.
- default값은 Delete요청 즉 삭제마커 데이터 같은 경우에는 복제하지 않으며 이를 활성화 가능합니다.
- 연쇄 복제는 불가능합니다.
- 1번이 2번에 복제를 생성하고 2번이 3번에 복제를 생성하게 된다고 했을떄
- 1번에 파일을 업로드하면 2번에는 복제가 되지만 이게 3번에는 복제가 되지 않습니다.
🚀 S3 CRR & SRR 실습
테스트할 두개의 버킷을 생성해 줍니다.
- 이떄 생성하는 두개의 버킷을 버저닝을 활성화 해주어야 합니다.
- 또한 복사를 할 버킷은 다른 리전으로 생성해 주었습니다.
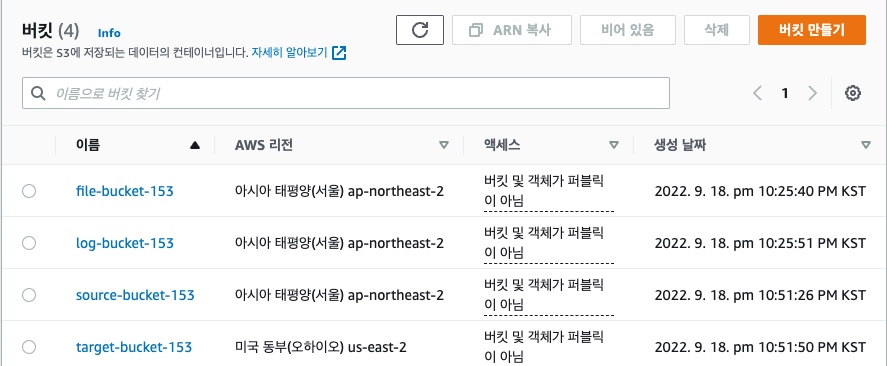
- 전에 테스트 하였던 로그 버킷까지 포함된 버킷입니다.
source-bucket,target-bucket만을 활용할 것 입니다.
일단 두가지를 테스트 하기 위해 sorucebucket에 파일을 한개 업로드 합니다.
업로드를 하게되면 일단은 복제 버킷을 설정하지 않았기 떄문에 targetbucket에는 파일이 없고 sourcebucket에는 파일이 존재하게 될 겁니다.
그럼 이제 복제규칙을 생성해 주겠습니다.
sourcebucket으로 이동하여 관리 페이지에서 복제 규칙 생성을 들어가줍니다.
이후 소스 버킷 및 대상을 설정해 줍니다.
소스 버킷 같은경우에는 필터를 걸 수도 있지만 굳이 그럴 필요성이 없이 복제되는것을 확인만 할 것이기 떄문에 버킷의 모든 객체에 적용을 선택해주며
대상 같은경우에는 다른 계정의 버킷이 아니기 떄문에 이계정의 버킷 선택을 클릭하여 targetbucket을 선택합니다.
IAM역할 같은경우에는 새 역할 생성이라는 IAM을 제공해 주기 떄문에 그것을 선택하며
만약 Delete하는 행위에 대해서도 동시에 진행시키고 싶다면 삭제 마커 복제 또한 체크해 줍니다.
이후 sourcebucket에 파일을 올리고 targetbucket에도 생성이 되는지 확인해 보면 됩니다.
- 중요한 점은 삭제 마커까지는 복제가 가능하지만 실제로 삭제하는 행위는 복제가 불가능 하다는 점입니다.
Youtube : https://www.youtube.com/watch?v=dpUhtlLjk_I
🚀 S3 스토리지 클래스 + Glacier
EC2 인스턴스에서도 다양한 클래스들이 있듯이.
S3를 활용하는데에도 다양한 스토리지 클래스가 있습니다.
S3는 EC2인스턴스와 다르게 버킷에 설정된 클래스로 모든 객체가 저장이 되는 것이 아니라, 객체마다 다른 클래스가 선택됩니다.
아래 나오는 클래스들은 S3에서 제공하고 있는 클래스들의 특징 및 이름입니다.
🐾 Standard
기본 default값으로 설정되는 스토리지 입니다.
내구성이 뛰어난 스토리지로 99.99999999의 내구성을 제공합니다.
- 그냥 매우 뛰어나다로 이해하면 됩니다.
AZ의 재해에 괸장히 강한데 이는 스토리지를 하나의 AZ에 보관을 하지 않기 떄문엡니다.
- 3개 이상에 저장을 하는 것으로 알고 있습니다.
대표적으로 모바일과 게임 콘텐츠 배포나, 빅 데이터 분석에 사용이 됩니다.
🐾 IA - Infrequent Access
이름 그대로 자주 액세스 하지 않는 객체를 보관할떄 사용 됩니다.
다중 AZ를 제공하기 떄문에 내구성이 뛰어납니다.
standard에 비해서 저렴한데 이는 객체에 액세스 하는 일이 적으면 많이 비용이 들지 않기 떄문엡니다.
- 자주 액세스 하지 않기 떄문에 데이터를 회수할떄마다 비용을 지불해야 합니다.
대표적으로는 재해 복구나 백업 또는 자주 액세스 하지 않는 파일을 저장하는데에 사용합니다.
🐾 IA - Infrequent Access (One Zone)
IA와 동일하지만 하나의 AZ에 보관을 하는 것을 말합니다.
그러기 떄문에 다중 AZ보다는 내구성이 떨어지지만 비용이 대략 20%가량 저렴합니다.
지연시간이 짧고 높은 처리량을 지원하며 모든 암호화에 SSl을 지원합니다.
주로 2차데이터를 백업하거나 재생성 가능한 데이터를 저장하는데에 사용이 됩니다.
재생성 데이터란 이미지 썸네일 같은 것을 말합니다.🐾 Intelligent Tiering
standard와 마찬가지로 지연시간이 짧고 처리량이 높지만
월간 모니터링 비용과 자동 티어 비용이 발생을 하는 클래스 입니다.
액세스 패턴에 기반하여 객체들을 자동으로 이동시켜 줍니다.
- 이는 standard와 IA사이에서 객체를 이동시키는 것 입니다.
비용이 조금 더 비싼데 이는 모니터링을 해주는 대가로 청구가 되기 떄문입니다.
🐾 Glacier
저렴한 비용의 스토리지로 백업을 위해서 존재합니다.
데이터를 장기간 보관하기 위해서 사용이 되며 데이터를 회수하고자 한다면 수동으로 직접 찾아 복원해야 합니다.
매우 저렴하며 GB당 회수 비용이 추가 됩니다.
회수 옵션
데이터 복원 및 회수 옵션에는 3가지가 있습니다.
1. Expedited
- 1 ~ 5분 소요 됩니다.
2. Standard
- 3 ~ 5시간 소요 됩니다.
3. Bulk
- 동시에 여러 파일을 회수하는 방식으로 5 ~ 12시간 소요 됩니다.
1번 부터 비용이 가장 비쌉니다.
최소 저장 기간은 90일 입니다.🐾 Deep Archive
Glacier보다 더 장기간 보관할떄 사용하는 스토리지 입니다.
회수 옵션
1. standard
- 12시간 소요 됩니다.
2. Bulk
- 다수의 파일을 회수하며 48시간 입니다.
최소 저장 기간은 180일 입니다.🚀 S3 수명 주기 규칙
말 그대로 규칙이지 단순히 어떻게 객체를 관리할지에 대한 내용입니다.
앞서 말했듯이 저장하는 클래스는 다양하며 클래스마다 다양한 장점이 있습니다.
어떤 클랙스는 오래보관하는데에 중점을 두고 어떤 클래스는 계속해서 객체를 사용할떄 유리합니다.
이러한 행위를 AWS에서 자체적으로 규칙을 만들어 관리 가능합니다.
- 예를들에 업로드 된지 60일된 객체는 Glacier로 보내라
- 또는 1년 지난 파일은 삭제해라
이러한 규칙을 의미하기 떄문에 바로 실습을 진행해 보았습니다.
🚀 S3 수명 주기 규칙 실습
버킷을 생성하고 Management탭에서 수명 주기 규칙으로 이동해 설정이 가능합니다.
버킷의 특정 범위를 설정가능하기도 하고 전체에 적용이 가능합니다.
- 원하는 방식을 선택합니다.
이후 규칙을 설정합니다.
이곳에서 이전 버전, 현재 버전이라는 단어가 있습니다.
이전 버전이란 버저닝 즉 복제가 되기 전의 버전을 말하고, 현재 버전은 버저닝이 작동을 하는 객체를 말합니다.원하는 옵션을 체크하고, 옵션에 맞는 규칙들을 설정하면 실습이 간단하게 마무리 됩니다.
- 이 실습에는 정답이 없습니다.. 원하는 대로 규칙을 정하는 행위이기 떄문입니다.
🚀 S3 기준 성능
S3는 기본적으로 굉장히 빠릅니다.
모든 API요청을 무리 없이 해결 가능합니다.
또한 접두어에 갯수 제한이 없습니다.
file이라는 이름의 객체를 예로 들어보겠습니다.
만약 버킷 내부에 folder1/sub1/file이라는 경로로 존재하게 된다면
접두어는 folder1/sub1이 됩니다.
만약 버킷 내부에 folder1/sub1/test1/file이라는 경로가 있다면
접두어는 folder1/sub1/test1이 됩니다.
즉 접두어에 대한 길이 제한은 없고, 접두어는 s3, 객체 이름 사이의 모든 값이 되며,
접두어가 길다고 요청에 더 많은 시간이 소요되는 것은 아니며 동일하게 동작합니다.🐾 KMS 성능 제한
KMS는 객체를 암호화하는 방식으로 AWS에서 자동으로 제공하는 서비스 입니다.
KMS암호화를 설정하였다면 객체를 업로드, 및 다운로드 할떄 다음과 같은 Flow가 적용됩니다.
파일을 업로드 하면 S3에서 사용자 대신 KMS API를 호출할 것이고, 다움로드 하는 경우에도 API를 요청할 것입니다.
즉 업로드/다운로드 하려하면 S3버킷이 API를 호출해 키를 생성하고 이를 KMS 키로 해독해 그 결과를 가져옵니다.모든 상황에 대해서 API요청이 발생을 하기 떄문에 업로드 요청에 비해 2배 정도 더 많이 발생을 하며 이로 인해 S3의 성능이 방해가 되기도 합니다.
- 이러한 상황에서는 어떻게 해야 하나 궁금하기는한데... 아직은 범위 밖이라서 다루지 못했습니다.. ㅠ
