과목 2. SQL 기본 및 활용
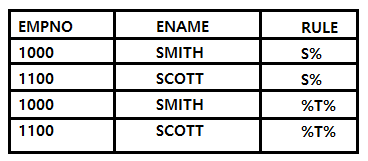
문제51. 어느 기업의 직원 테이블(EMP)이 직급(GRADE) 별로 사원 500명, 대리 100명, 과장 30명, 차장 10명, 부장 5명, 직급이 정해지지 않은 (NULL) 사람25명으로 구성되어 있을 때, 다음 중 SQL문을 SQL1부터 SQL3까지 순차적으로 실행한 결과 건수를 순서대로 나열한 것으로 가장 적절한 것은?
SQL1) SELECT COUNT(GRADE) FROM EMP; SQL2) SELECT GRADE FROM EMP WHERE GRADE IN ('차장','부장','널') SQL3) SELECT GRADE, COUNT(*) FROM EMP GROUP BY GRADE① 670, 15, 5
②645, 40, 5
③ 645, 15, 6
④ 670, 40, 6
[해설] ③
SQL1) SELECT COUNT(GRADE) FROM EMP;
645건 : 사원 500명 + 대리 100명 + 과장 30명 + 차장 10명 + 부장 5명
이때 NULL 25건은 제외된다.
SQL2) SELECT GRADE FROM EMP WHERE GRADE IN('차장','부장','널');
15건 : 차장 10명 + 부장 5명
'널'이 텍스트로 입력된 데이터는 없다고 봐야함
SQL3) SELECT GRADE, COUNT(*) FROM EMP GRADE BY GRADE;
6건 : 5개 직급 + NULL 기준별 데이터 수가 6건 출력됨
문제53. 다음중 오류가 발생하는 SQL 문장인 것은?
①
SELECT 회원ID, SUM(주문금액) AS 합계
FROM 주문
GROUP BY 회원 ID
HAVING COUNT() > 1;
②
SELECT SUM(주문금액) AS 합계
FROM 주문
HAVING AVG(주문금액) > 100;
③
SELECT 메뉴ID, 사용유형코드, COUNT() AS CNT
FROM 시스템사용이력
WHERE 사용일시 BETWEEN SYSDATE - 1 AND SYSDATE
GROUP BY 메뉴ID, 사용유형코드
HAVING 메뉴ID = 3 AND 사용유형코드 = 100;
④
SELECT 메뉴ID, 사용유형코드, AVG(COUNT(*)) AS AVGCNT
FROM 시스템사용이력
GROUP BY 메뉴ID, 사용유형코드;
[해설] ④
③ 의 경우 GROUP BY로 그룹핑된 컬럼에 대해서 HAVING 조건절을 사용할 경우 집계된 컬럼의 FILTER조건으로 사용할 수가 있다. 이런 경우 HAVING절에 집계함수가 없어도 사용할 수 있다.
④ 중첩된 그룹함수의 경우 최종 결과값은 1건이 될 수 밖에 없기에 GROUP BY 절에 기술된 메뉴ID와 사용유형코드는 SELECT절에 기술될 수 없다.
문제55. 다음 중 아래 SQL의 실행결과로 가장 적절한 것은?

①
ID
100
999
②
ID
999
100
③
ID
100
200
999
④
999
200
100
[해설] ②
Group By Having 한 결과에 대해 정렬 연산을 하는 것이다.
ID 건수가 2개이며, ORDER BY절 CASE문에 의해 999는 0으로 치환되고 그 외는 ID 값으로 정렬된다.
문제56. 다음 SQL 중 오류가 발생하는 것은?
①
SELECT 지역, SUM(매출금액) AS 매출금액
FROM 지역별매출
GROUP BY 지역
ORDER BY 매출금액 DESC;
②
SELECT 지역, 매출금액
FROM 지역별매출
ORDER BY 년 ASC;
③
SELECT 지역, SUM(매출금액) AS 매출금액
FROM 지역별 매출
GROUP BY 지역
ORDER BY 년 DESC;
④
SELECT 지역, SUM(매출금액) AS 매출금액
FROM 지역별매출
GROUP BY 지역
HAVING SUM(매출금액) > 1000
ORDER BY COUNT(*) ASC;
[해설] ③
② 은 SQL 실행 순서에 의하면 SELECT절 이후에 ORDER BY 절이 수행되기 때문에 SELECT 절에 기술되지 않는 '년' 칼럼으로 정렬하는 것은 논리적으로 맞지 않다. 하지만 오라클은 행 기반 DATABASE 이기에 데이터를 액세스할 때 행 전체 칼럼을 메모리에 로드한다. 이와 같은 특성으로 인해 SELECT절에 기술되지 않은 칼럼으로도 정렬을 할 수 있다.
단, 아래와 같은 SQL일 경우에는 정렬을 할 수 없다.
SELECT 지역, 매출금액
FROM (
SELECT 지역, 매출금액
FROM 지역별 매출
)
ORDER BY 년 ASC;이는 IN-LINE VIEW가 먼저 수행됨에 따라 더 이상 SELECT절 외 칼럼을 사용할 수 없기 때문이다.
③ GROUP BY를 사용할 경우 GROUP BY 표현식이 아닌 값은 기술될 수 없다.
④ GROUP BY 표현식이기에 가능하다.
문제57. 다음 중 ORDER BY 절에 대한 설명으로 가장 부적절한 것은?
① SQL 문장으로 조회된 데이터들을 다양한 목적에 맞게 특정 컬럼을 기준으로 정렬하는데 사용한다.
②DBMS마다 NULL 값에 대한 정렬 순서가 다를 수 있으므로 주의하여야 한다.
③ ORDER BY 절에서 컬럼명 대신 Alias 명이나 컬럼 순서를 나타내는 정수도 사용이 가능하나, 이들을 혼용하여 사용할 수 없다.
④ GROUP BY 절을 사용하는 경우 ORDER BY 절에 집계 함수를 사용할 수도 있다.
[해설] ③
ORDER BY 절에 컬럼명 대신 Alias 명이나 컬럼 순서를 나타내는 정수를 혼용하여 사용할 수 있다.
문제58. 다음 SQL의 실행 결과로 가장 적절한 것은?

① 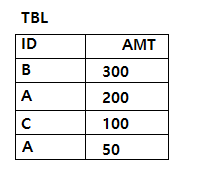
② 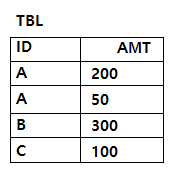
③ 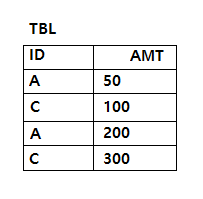
④ 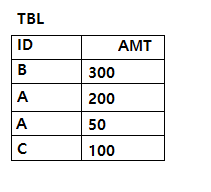
[해설] ②
CASE절을 이용해서 원래의 정렬 순서를 변경하였다. 그래서 ID가 'A'인 것이 가장 먼저 표시되도록 하였다.
문제62. 아래의 영화 데이터베이스 테이블의 일부에서 밑줄 친 속성들은 테이블의 기본키이며 출연료가 8888 이상인 영화명, 배우명, 출연료를 구하는 SQL로 가장 적절한 것은?
<아래>
배우(배우번호, 배우명, 성별)
영화(영화번호, 영화명, 제작년도)
출연(배우번호, 영화번호, 출연료)
①
SELECT 출연, 영화명, 영화.배우명, 출연.출연료
FROM 배우, 영화, 출연
WHERE 출연료 >= 8888
AND 출연.영화번호 = 영화.영화번호
AND 출연.배우번호 = 배우.배우번호;
②
SELECT 영화.영화명, 배우.배우명, 출연료
FROM 영화, 배우, 출연
WHERE 출연.출연료 > 8888
AND 출연.영화번호 = 영화.영화번호
AND 영화.영화번호 = 배우.배우번호;
③
SELECT 영화명, 배우명, 출연료
FROM 배우, 영화, 출연
WHERE 출연료 >= 8888
AND 영화번호 = 영화.영화번호
AND 배우번호 = 배우.배우번호;
④
SELECT 영화.영화명, 배우.배우명, 출연료
FROM 배우, 영화, 출연
WHERE 출연료 >= 8888
AND 출연.영화번호 = 영화.영화번호
AND 출연.배우번호 = 배우.배우번호;
[해설] ②
영화명과 배우명은 출연테이블이 아니라 영화와 배우 테이블에서 가지고 와야 하는 속성이므로 출연테이블의 영화번호와 영화테이블의 영화번호 및 출연테이블의 배우번호와 배우테이블의 배우번호를 조인하는 SQL문을 작성해야 함.
문제64. 다음 SQL의 실행 결과로 맞는 것은?
<아래>
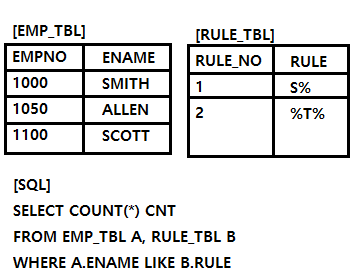
① 0 ② 2
③ 4 ④ 6
[해설] ③
LIKE 연산자를 이용한 조인의 이해가 필요하다.
SQL의 실행결과는 다음과 같다.