복습
데이터베이스(DB)
데이터의 모음집
DBMS - 데이터베이스를 관리해주는 프로그램
oracle, mysql, mssql 등..
데이터의 수집을 테이블형식(엑셀형식)으로 관리하는것
RDMS
데이터를 조회, 삭제, 추가, 갱신할 수 있도록 하는 언어
SQL
데이터를 조회, 삭제, 추가, 갱신을 하기 위해서는
테이블(표)에 데이터가 있어야 하므로, 테이블을 만들어 줘야한다
이러한 여러개의 테이블을 하나의 데이터베이스에서 관리하므로,
데이터베이스를 먼저 생성한 후 테이블 생성
1. create database 데이터베이스 명
2. use 데이터베이스 명
3. create table 테이블명
create table 테이블명{
열이름 자료형 [기본값][null | not null],
열이름 자료형 [기본값][null | not null],
...
}
제약
제약조건
-------------------
null 중복값
-------------------
X O not null (필수)
O X Unique
X X Primary Key(PK)
O O 제약조건을 안주면 됨.(생략)
※ PK 설정하는 두가지 방법
[방법1]
create table sample631{
a int not null,
b int primary key,
c varchar(30)
}
[방법2]
create table sample631{
a int not null,
b int,
c varchar(30)
constraint 제약조건명 primary key(b)
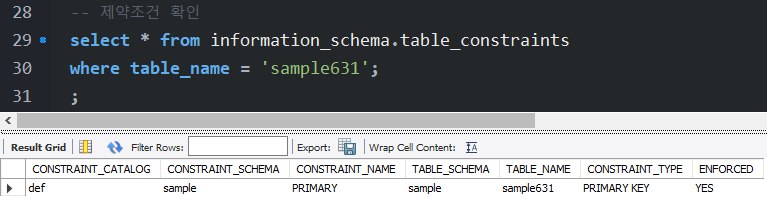
}- 제약조건 확인하기
select * from information_schema.table_constraints
where table_name = 'sample631';
;
제약 추가
열 제약 추가
-- c열에 null 제약 추가
ALTER TABLE sample631 MODIFY c VARCHAR(30) NOT NULL;
-- a열에 primary key(기본키)를 제약 추가
-- 제약 조건 이름을 pkey_sample631로 설정
alter table sample631 add constraint pkey_sample631 primary key(a);제약 삭제하기
-- c열에 null 제약 삭제
alter table sample631 modify c varchar(30);
-- a열에 primary key(기본키)를 제약 삭제(제약조건 이름이 있을 경우 : pkey_sample631)
alter table sample631 drop constraint pkey_sample631;
-- a열에 primary key(기본키)를 제약 삭제(제약조건이름이 없을 경우)
alter table sample631 drop primary key;
기본키
기본키 제약이 설정된 테이블에서는 기본키를 검색했을 때 복수의 행이 일치하는 데이터를 작성할 수 없습니다.
기본키로 설정된 열이 중복하는 데이터 값을 가지면 제약에 위반됩니다.
[예제 6-14 sample634 테이블 작성하기]
-- sample634 테이블 생성
create table sample634(
-- 정수형 p라는 이름의 열을 null값을 허용하지 않음
p integer not null,
-- a라는 이름의 최대 문자열을 30으로 설정
a varchar(30),
-- p열의 기본키(제약조건)를 설정하고 그 제약조건의 이름을 pkey_sample634로 설정해라
constraint pkey_sample634 primary key(p)
);[예제 6-15 sample634에 행 추가하기]
insert into sample634 values(1, '첫째줄');
insert into sample634 values(2, "둘째줄");
insert into sample634 values(3, '셋째줄');
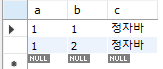
[예제 6-16 sample634에 행 추가하기]
insert into sample634 values(2, "넷째줄");
기본키에 중복값에 들어가서 위와같은 오류를 발생시키면서 추가할 수 없다.
select * from sample634;로 확인해보면
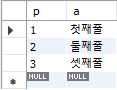
이와 같은 값이 들어가있다.
[예제 6-17 sample634을 중복된 값으로 갱신하기]
update sample634 SET p=2 where p=3; -- where이 없으면 테이블에 있는 데이터를 2로 변경
-- where이 있기때문에 3을 2로 바꿔라.
3인 행인 행을 2로 갱신하는데 성공하면 p = 2 인 열이 두개나 존재해서 제약을 위반한다고 오류가 발생하는것 이다.
이처럼 열을 기본키로 지정해 유일한 값을 가지도록 하는 구조가 바로 '기본키 제약'이다
복수의 열로 기본키 구성하기
[예제 6-18 a 열과 b열로 이루어진 기본키]
create table sample635(
a int not null,
b int not null,
constraint skey_sample635 primary key(a,b)
);
desc sample635;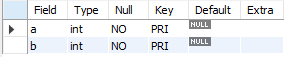
insert into sample635 value(1,1);
insert into sample635 value(1,2);
insert into sample635 value(1,3);
insert into sample635 value(2,1);
insert into sample635 value(2,2);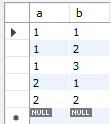
키(Key)
후보키 : 기본키가 될수 있는 열
(주민등록번호, 학번)
대체키 : 기본키를 대체 할 수 있는 키
(학번)
기본키 : 하나의 열로 구성된 유일성을 갖춘 키
(주민등록번호)
슈퍼키 : 두개 이상의 열을 합쳐서 구성된 유일성을 갖춘 키
(두개 이상의 열을 합쳐서 구성된 유일성을 갖춘 키)
인덱스
인덱스는 왜 쓰는가?
데이터베이스 테이블에서 특정 컬럼이나 컬럼의 조합에 대해 빠른 검색을 위해 생성하는 데이터 구조입니다. 인덱스를 사용하면 데이터베이스 엔진이 검색 조건에 해당하는 데이터를 빠르게 찾아내기 때문에 데이터 검색 성능이 향상됩니다.
인덱스는 데이터베이스 테이블의 특정 컬럼에 대한 값을 정렬한 데이터 구조입니다. 이 구조는 데이터베이스 엔진이 검색할 때 더 빠르게 검색할 수 있도록 해줍니다. 인덱스를 생성하면 검색 조건에 해당하는 데이터를 찾기 위해 전체 데이터를 검색하지 않아도 됩니다. 대신 인덱스에서 검색하면 빠르게 검색할 수 있습니다.
검색에 사용되는 알고리즘
- 풀 테이블 스캔(full table scan)
풀 테이블 스캔은 데이터베이스에서 전체 데이터를 대상으로 검색하는 방법입니다. 이 방법은 검색 대상이 많은 경우에는 속도가 느리기 때문에, 데이터베이스 성능 최적화 시에는 최대한 피해야 하는 방법입니다. 풀 테이블 스캔은 인덱스가 없는 테이블에서 사용되기도 하며, 인덱스를 사용해도 성능 최적화가 불가능한 경우에 사용됩니다.
- 이진 탐색(binary search)
이진 탐색은 정렬된 데이터 집합에서 특정 값을 찾는 알고리즘입니다. 이 알고리즘은 탐색 범위를 반으로 줄이면서 값을 찾아가는 방식으로 동작합니다. 이진 탐색 알고리즘은 주로 배열에서 사용되며, 검색 속도가 매우 빠릅니다. 이진 탐색은 배열의 중간에 위치한 값을 찾아서 검색하는 방식으로 동작하므로, 탐색 범위가 크면 큰 값의 절반을 버릴 수 있어서 검색 속도가 매우 빠릅니다. 이진 탐색 알고리즘의 시간 복잡도는 O(logN)으로, 데이터의 크기가 늘어나도 검색 속도가 느려지는 정도가 매우 느립니다. 따라서 이진 탐색은 대용량 데이터 검색에서 매우 효율적인 알고리즘 중 하나입니다.
- 이진 트리(binary tree)
각 노드가 최대 두 개의 자식 노드를 가지는 트리 구조입니다. 이진 트리는 트리 구조 중에서 가장 간단한 형태이며, 자료 구조에서 널리 사용됩니다. 이진 트리는 매우 빠른 검색, 삽입, 삭제 연산을 지원하며, 정렬된 데이터를 저장하거나 탐색하는 데에도 사용됩니다.이진 트리에서 각 노드는 부모 노드와 두 개의 자식 노드를 가질 수 있습니다. 왼쪽 자식 노드는 부모 노드보다 작은 값을 가지며, 오른쪽 자식 노드는 부모 노드보다 큰 값을 가집니다. 이진 탐색 트리(Binary Search Tree)는 이진 트리에서 특정한 조건을 만족하는 트리입니다. 이 조건은 왼쪽 서브트리에는 부모 노드보다 작은 값의 노드들만 존재하고, 오른쪽 서브트리에는 부모 노드보다 큰 값의 노드들만 존재해야 합니다. 이러한 조건으로 인해 이진 탐색 트리는 매우 빠른 검색을 지원합니다.
이진 트리는 효율적인 검색과 데이터 구조를 구현하는 데에 매우 유용한 자료 구조입니다. 이진 탐색 트리는 정렬된 데이터를 저장하고 검색하는 데에 매우 효율적입니다. 또한, 이진 트리는 AVL 트리, 레드-블랙 트리, B-트리 등의 다른 자료 구조와 함께 사용될 수 있습니다.
인덱스의 작성과 삭제
인덱스 작성
Syntax
CREATE INDEX
DROP INDEX인덱스를 생성하기 위해서는 CREATE INDEX 문을 사용합니다. 기본적인 문법은 다음과 같습니다.
CREATE INDEX 인덱스이름 ON 테이블이름 (컬럼이름);위의 문법에서 인덱스 이름은 생성할 인덱스의 이름을, 테이블 이름은 인덱스를 생성할 테이블의 이름을, 컬럼 이름은 인덱스를 생성할 컬럼의 이름을 입력합니다.
예를 들어, 'members' 테이블의 'name' 컬럼에 대한 인덱스를 생성하려면 다음과 같은 SQL 문을 사용합니다.
CREATE INDEX idx_name ON members (name);
[예제 6-19 인덱스 작성하기]
create index sample62 on sample62(no);
확인해보면 키가 생성됨

인덱스 삭제
drop index sample62 on sample62;
삭제된것을 확인할 수 있음.
EXPLAIN
SQL 쿼리 실행 계획을 분석하여 쿼리가 어떻게 실행되는지에 대한 정보를 반환하는 명령어입니다.
"EXPLAIN" 명령어를 사용하면 쿼리가 실행될 때 데이터베이스 시스템이 어떤 순서로 테이블을 스캔하고, 어떤 인덱스를 사용하는지, 어떤 조인 방식을 사용하는지, 어떤 필터링 조건을 적용하는지 등 다양한 정보를 확인할 수 있습니다.
이를 통해 쿼리가 실행되는 과정에서 어떤 문제가 발생하고 있는지 파악하고, 실행 계획을 최적화하여 성능을 개선할 수 있습니다. "EXPLAIN" 결과를 분석하여 인덱스를 추가하거나 쿼리 문법을 개선하거나, 조인 방식을 변경하는 등의 작업을 수행하여 쿼리 성능을 개선할 수 있습니다.
[예제 6-21 EXPLAIN으로 인덱스 사용 확인하기 1 (MySQL)]
explain select * from sample62; -- possible_keys열과 key열이 null이면 index를 사용하고 있지 않다는것임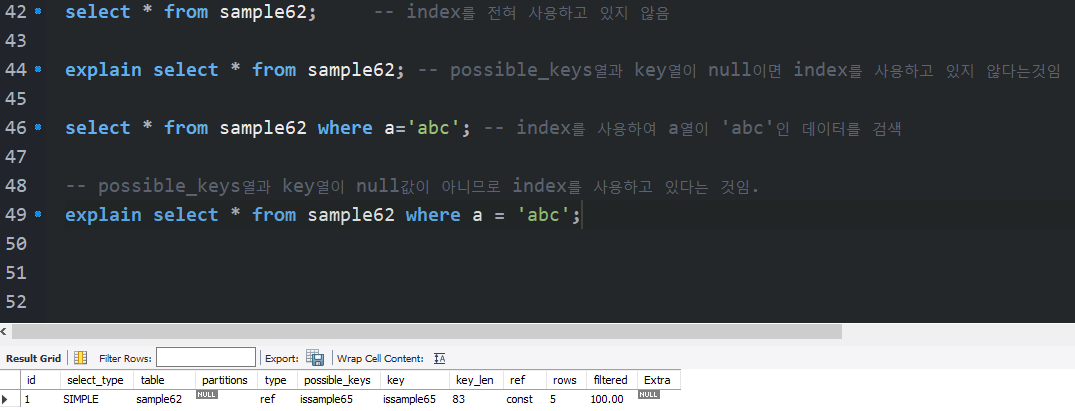
뷰 작성과 삭제
뷰의 작성 및 삭제 Syntax
뷰(View)란 하나 이상의 테이블로부터 유도된, 가상의 테이블이다. 즉, 기존의 테이블로부터 SELECT문을 이용하여 뷰를 생성하고, 이 뷰를 테이블처럼 활용할 수 있다. 뷰를 사용하면 복잡한 쿼리나 여러 개의 테이블을 간단하게 볼 수 있으며, 보안상의 이유로 특정 컬럼이나 로우에 대한 접근 권한을 제한하는 등의 용도로도 사용된다.
뷰를 생성하는 방법은 다음과 같다.
CREATE VIEW 뷰이름 AS
SELECT 컬럼1, 컬럼2, ...
FROM 테이블이름
WHERE 조건;예를 들어, CUSTOMER 테이블에서 CUSTOMER_ID가 1인 고객의 이름과 나이를 조회하는 뷰를 생성한다면 다음과 같이 작성할 수 있다.
CREATE VIEW CUSTOMER_VIEW AS
SELECT CUSTOMER_NAME, CUSTOMER_AGE
FROM CUSTOMER
WHERE CUSTOMER_ID = 1;뷰를 삭제하는 방법은 다음과 같다.
DROP VIEW 뷰이름;위에서 생성한 CUSTOMER_VIEW 뷰를 삭제하려면 다음과 같이 작성하면 된다.
DROP VIEW CUSTOMER_VIEW;CREATE DATABASE 데이터베이스명
CREATE TABLE 테이블명
CREATE INDEX 인덱스명
CREATE VIEW 뷰명 AS SELECT절
쿼리안에 쿼리를 넣는걸 서브쿼리(중첩쿼리)라고함..
SELECT * FROM 테이블명
SELECT (SELECT * FROM 테이블명) FROM 테이블명 - 서브쿼리(스칼라 서브쿼리)
SELECT FROM (SELECT * FROM 테이블명) - 서브쿼리(인라인 뷰)
SELECT * FROM 테이블명 WHERE A = (SELECT / FROM테이블명)
SELECT *
FROM ( SELECT *
FROM TB1
WHERE col1 = (SELECT * FROM TB2 WHERE col2= 'b')
AND col3 = 'c'
ORDER BY c1
GROUP BY C1
HAVING c4 >= 100
)
CREATE VIEW V1 AS
SELECT *
FROM TB1
WHERE col1 = (SELECT * FROM TB2 WHERE col2 = 'b')
AND col3 = 'c'
ORDER BY c1
GROUP BY c1
HAVING c4 >= 100
)
SELECT * FROM V1