복수의 테이블 다루기
집합연산
- 관계형 모델 : RDBMS의 창시자인 에드거 커드(Edgar F.Codd)가 고안한 모델이다.
데이터를 표 형태의 테이블로 표현하고, 각 테이블은 열(column)과 행(row)으로 이루어져 있습니다. 각 열은 데이터의 속성(attribute)을 나타내고, 각 행은 데이터의 인스턴스(instance)를 나타냅니다.
Union으로 합집합 구하기
UNION 연산자는 두 개 이상의 SELECT 문의 결과를 결합하여 하나의 결과 집합으로 만들어줍니다. 각 SELECT 문은 같은 열 수와 데이터 형식을 가져야합니다.
UNION 연산자는 중복된 행을 제거하며, UNION ALL 연산자를 사용하면 중복된 행을 제거하지 않습니다.
또한, UNION 연산자는 각 SELECT 문에서 검색하는 열의 수와 데이터 형식이 동일해야하므로 동일한 수의 열을 반환하지 않는 SELECT 문을 결합할 수 없습니다. 이 경우 UNION ALL을 사용하여 결과 집합에 중복된 행을 포함시킬 수 있습니다.
sample71_a
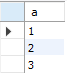
sample71_b
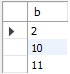
select * from sample71_a
union
select * from sample71_b;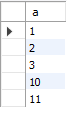
열의 수가 맞지 않을때
위의 예제에 sample31을 넣으려고한다.

SELECT * FROM sample71_a
UNION
SELECT * FROM sample71_b
union
SELECT * FROM sample31;열의 수가 맞지않아서 오류가 발생한다.

아래와 같이 수정후 실행해보면
SELECT * FROM sample71_a
UNION
SELECT * FROM sample71_b
union
SELECT name FROM sample31;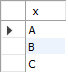
name의 값만 받아와서 실행하기 때문에 문제없이 실행되는 모습을 볼 수있다.
UNION ALL
UNION ALL 연산자를 사용하면 중복된 행을 제거하지 않습니다.
SELECT * FROM sample71_a
UNION ALL
SELECT * FROM sample71_b;
교집합과 차집합
교집합
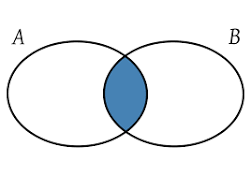
SQL에서의 교집합
두 개 이상의 SELECT 문의 결과에서 공통된 행만 반환하는 연산자입니다. 각 SELECT 문은 같은 열 수와 데이터 형식을 가져야합니다.
INTERSECT 연산자를 사용하여 두 개의 테이블에서 공통된 데이터를 찾는 예제를 살펴보겠습니다.
SELECT column1, column2, column3
FROM table1
INTERSECT
SELECT column1, column2, column3
FROM table2;차집합
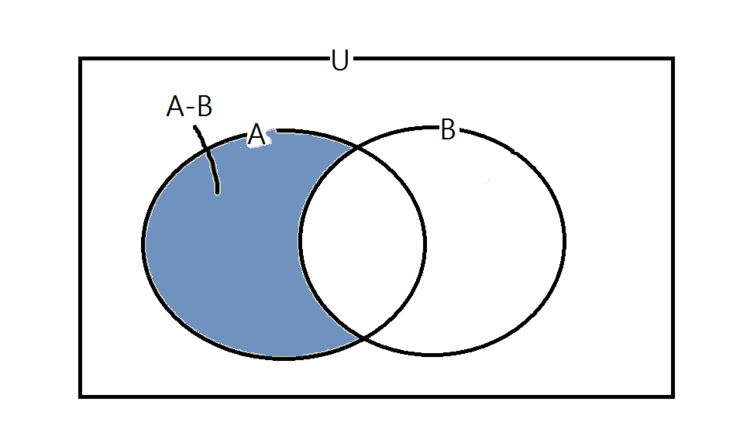
SQL에서의 차집합
EXCEPT 또는 MINUS(Oracle의 경우) 연산자는 두 개 이상의 SELECT 문의 결과에서 첫 번째 SELECT 문의 결과에만 포함되는 행을 반환하는 연산자입니다. 각 SELECT 문은 같은 열 수와 데이터 형식을 가져야합니다.
EXCEPT 또는 MINUS 연산자를 사용하여 두 개의 테이블에서 첫 번째 SELECT 문의 결과에만 포함되는 데이터를 찾는 예제를 살펴보겠습니다.
SELECT column1, column2, column3
FROM table1
EXCEPT
SELECT column1, column2, column3
FROM table2;이 쿼리는 table1의 column1, column2, column3에 해당하는 결과 중 table2의 column1, column2, column3에 해당하는 결과를 제외한 결과를 반환합니다.
EXCEPT 연산자는 첫 번째 SELECT 문의 결과에서 두 번째 SELECT 문의 결과에 있는 행을 제거합니다. 따라서 결과 집합은 첫 번째 SELECT 문에서 반환되는 행 중 두 번째 SELECT 문에서 반환되는 행이 없는 행만 포함합니다.
테이블 결합
테이블 결합(Table Join)은 SQL에서 두 개 이상의 테이블에서 데이터를 가져와 결합하여 새로운 결과 집합을 만드는 작업입니다. 테이블 결합은 데이터베이스에서 데이터를 검색하고 분석하는 데 필수적인 기술 중 하나입니다.
일반적으로 테이블 결합은 JOIN 키워드를 사용하여 수행됩니다. JOIN 키워드는 INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN 등 다양한 유형의 결합을 수행할 수 있습니다.
곱집합과 교차결합
곱집합(Cartesian Product)은 두 개 이상의 집합에서 가능한 모든 조합을 구하는 것입니다. SQL에서는 교차결합(CROSS JOIN)을 사용하여 두 개 이상의 테이블의 모든 조합을 만들 수 있습니다.
SELECT *
FROM products
CROSS JOIN colors;위의 쿼리는 products 테이블과 colors 테이블의 모든 행 조합을 반환합니다. 결과 집합은 products 테이블의 행 수와 colors 테이블의 행 수를 곱한 크기를 가지며, 각 조합은 products와 colors의 모든 열을 포함합니다.
교차결합(CROSS JOIN)은 두 개 이상의 테이블에서도 사용할 수 있으며, 가능한 모든 행 조합을 반환합니다. 하지만 CROSS JOIN은 성능상의 이유로 가능한 사용을 피해야 합니다. 따라서 가능한 경우, 조인 키워드(예: INNER JOIN, LEFT JOIN)를 사용하여 테이블을 결합하는 것이 좋습니다.
Syntax 교차결합(Cross Join)
SELECT * FROM 테이블명1, 테이블명2
[sample72_x]
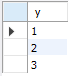
[sample72_y]
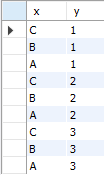
[예제_FROM구에 테이블 두개를 지정해 곱집합 구하기]
select * from sample72_x, sample72_y;
FROM 구에 복수의 테이블을 지정하면 교차결합을 한다.
- UNION 연결과 결합 연결의 차이
UNION 연결: UNION 연산자는 두 개 이상의 SELECT 문의 결과를 연결하여 하나의 결과 집합으로 만드는 것입니다. 단, 각 SELECT 문의 결과 집합은 동일한 열 수를 가져야 하며, 결과 집합에 중복된 행이 없어야 합니다. 예를 들어, 아래와 같이 두 개의 SELECT 문을 UNION 연산자로 연결하여 하나의 결과 집합으로 만들 수 있습니다.
SELECT column1, column2
FROM table1
UNION
SELECT column1, column2
FROM table2;위의 쿼리는 table1과 table2에서 column1과 column2를 선택하고, 두 결과 집합을 UNION 연산자로 결합하여 중복된 행을 제거한 후 하나의 결과 집합으로 반환합니다.
결합 연결: 결합 연결은 두 개 이상의 테이블에서 데이터를 결합하여 새로운 결과 집합을 만드는 것입니다. 이 때, 결합 연산에는 JOIN 키워드를 사용합니다. JOIN 키워드는 INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN 등 다양한 유형의 결합을 수행할 수 있습니다. 예를 들어, 아래와 같이 INNER JOIN으로 두 개의 테이블을 결합할 수 있습니다.
SELECT *
FROM table1
INNER JOIN table2
ON table1.column = table2.column;
위의 쿼리는 table1과 table2에서 column 값이 일치하는 행을 INNER JOIN으로 결합하여 하나의 결과 집합으로 반환합니다.
따라서, UNION 연결은 SELECT 문의 결과를 결합하는 것이고, 결합 연결은 테이블에서 데이터를 결합하는 것입니다.
내부결합
내부결합(Inner Join)은 두 개 이상의 테이블에서 데이터를 결합하여 새로운 결과 집합을 생성하는 데 사용되는 조인 유형 중 하나입니다.
내부결합은 JOIN 키워드와 ON 절을 사용하여 수행됩니다. ON 절은 결합할 테이블 간의 조인 조건을 지정합니다. INNER JOIN은 ON 절에서 정의한 조인 조건을 만족하는 두 테이블의 공통 열 값을 기준으로 데이터를 결합합니다.
예를 들어, customers와 orders라는 두 개의 테이블이 있다면, customers와 orders를 공통된 customer_id 열을 기준으로 INNER JOIN 할 수 있습니다.
SELECT *
FROM customers
INNER JOIN orders
ON customers.customer_id = orders.customer_id;위의 쿼리는 customers와 orders 테이블에서 customer_id 열의 값이 일치하는 모든 행을 INNER JOIN하여 하나의 결과 집합으로 반환합니다.
내부결합은 두 테이블에서 공통 열 값을 가진 행만을 결합하기 때문에, 결과 집합은 JOIN하는 두 테이블의 교집합이 됩니다. 따라서, INNER JOIN을 사용하여 두 테이블을 결합하면, JOIN하는 두 테이블에서 공통된 데이터만을 결과로 얻을 수 있습니다.
[내부결합 예제]
select from 상품;
select from 재고수;

select *
from 상품, 재고수
where 상품.상품코드 = 재고수.상품코드;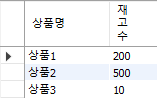
위의 SQL 쿼리는 두 개의 테이블인 상품과 재고수를 INNER JOIN하여 상품코드에 대한 정보를 함께 조회하는 것을 의미합니다.
쿼리에서 사용된 WHERE 절에서는 INNER JOIN에 사용되는 조인 조건을 지정합니다. 즉, 상품 테이블과 재고수 테이블을 INNER JOIN하는데, 상품코드 열이 일치하는 경우에만 두 테이블의 행을 결합하고, 이에 해당하지 않는 경우에는 결과 집합에서 제외됩니다.
쿼리의 실행 결과는 상품과 재고수 테이블에서 상품코드 열이 일치하는 모든 행을 결합하여 반환하므로, 두 테이블에서 공통된 데이터만을 결과로 얻게 됩니다. 결과 집합에는 상품과 재고수의 모든 열에 대한 정보가 함께 포함되어 있습니다.
INNER JOIN으로 내부결합하기
일반 내부 결합
-- 내부결합(from절에 두 테이블을 콤마로 연결)
select 상품명, 재고수
from 상품, 재고수
where 상품.상품코드 = 재고수.상품코드
;INNER JOIN : 두 개의 테이블에서 조건을 만족하는 행을 반환합니다. 즉, 교집합을 구하는 것과 같습니다.
INNER JOIN을 이용한 내부결합
-- 내부결합(inner join 키워드를 이용, 이때 innser는 생략할 수 있음.)
select 상품명, 재고수
-- from 상품 inner join 재고수
from 상품 join 재고수
on 상품.상품코드 = 재고수.상품코드
;
두개의 코드 모두 결과는 같다.
[예제2]

[예제2.1_중복행 처리]
아래와 같이 작성하면 오류가 발생한다.
select 상품명, 메이커명, 메이커코드
from 상품2, 메이커
where 상품2.메이커코드 = 메이커.메이커코드
;
ambiguous : 모호한
상품2와 메이커 테이블에 메이커코드가 둘다 가지고 있기때문에 어떤 값을 출력할지 애매하다는 것이다.
아래와 같이 별칭을 주어서 구분할 수 있도록 해주자.
select 상품명, 메이커명, S.메이커코드
from 상품2 S, 메이커 M
where S.메이커코드 = M.메이커코드
;
-- '위 코드나 아래 코드나 결과는 같음'
select 상품명, 메이커명, S.메이커코드
from S inner join 메이커 M
on S.메이커코드 = M.메이커코드
;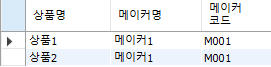
그럼 정상적으로 실행이 된다.
[예제2.2_메이커코드로 분류]
select 상품명, 메이커명, S.메이커코드
from 상품2 S, 메이커 M
where S.메이커코드 = M.메이커코드
and S.메이커코드 = 'M001'
;
-- '위 코드나 아래 코드나 결과는 같음'
select 상품명, 메이커명, S.메이커코드
from S inner join 메이커 M
on S.메이커코드 = M.메이커코드
WHERE S.메이커코드 = 'M001'
;
메이커코드 'M001'인 것만 분류해 출력한 결과이다.
외부결합
외부결합(Outer Join)은 두 개 이상의 테이블에서 데이터를 결합하여 새로운 결과 집합을 생성하는 방법 중 하나입니다. 외부결합은 INNER JOIN과 마찬가지로 JOIN의 한 유형이며, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN 등 다양한 종류가 있습니다.
외부결합은 INNER JOIN과 달리 조인 조건에 부합하지 않는 데이터도 결과 집합에 포함시키는 특징이 있습니다. 이는 조인하고자 하는 두 테이블에서 공통된 데이터가 아닌 경우에도 모든 데이터를 결과에 포함시키기 위해 사용됩니다.
LEFT OUTER JOIN: 왼쪽 테이블의 모든 행과, 오른쪽 테이블에서 조인 조건에 부합하는 데이터를 함께 결과 집합으로 반환하며, 오른쪽 테이블에서 조인 조건에 부합하지 않는 데이터는 NULL 값으로 채워진다.
RIGHT OUTER JOIN: 오른쪽 테이블의 모든 행과, 왼쪽 테이블에서 조인 조건에 부합하는 데이터를 함께 결과 집합으로 반환하며, 왼쪽 테이블에서 조인 조건에 부합하지 않는 데이터는 NULL 값으로 채워진다.
FULL OUTER JOIN: 왼쪽, 오른쪽 테이블의 모든 행을 함께 결과 집합으로 반환하며, 일치하지 않는 행은 NULL 값으로 채워진다.
외부결합은 두 개 이상의 테이블에서 데이터를 쿼리할 때, 특히 특정 테이블에서 해당하는 데이터가 없는 경우에도 모든 데이터를 결과에 포함시켜야 할 때 많이 사용됩니다.
[외부결합 예제]

select 상품3.상품명, 재고수.재고수
-- from 상품3 left join 재고수
from 재고수, 상품3
on 상품3.상품코드 = 재고수.상품코드(+) -- left join(Oracle)
;[네이버 로그인,자유게시판 데이터를 저장하는 테이블 만드는 예제]
create database naver_1;
use naver_1;
create table member
(
id varchar(30) primary key,
pswd varchar(30) NOT NULL,
name varchar(30) NOT NULL,
birth date NOT NULL, -- varchar해도 상관은없다 다만 2월에 30일을 입력했을때 insert 될 수있어서 따로 조건설정을 해줘야함.
-- 생일을 3개로 나누어서 해도 되지않느냐? -> 자바스크립트에서 concat을 이용해서 문자열을 결합시켜서 하나로 만들어도 됨.
gender varchar(5) NOT NULL,
email varchar(30),
phonenum varchar(20) NOT NULL
);
create table board
(
no int primary key auto_increment,
title varchar(30) NOT NULL, -- 제목
content varchar(20) NOT NULL, -- 내용
categori varchar(30) NOT NULL,
id varchar(10),
tag varchar(500),
regdate datetime default now(), -- 날짜값을 넣지않으면 기본값인 오늘 날짜가 들어간다는 뜻
count int, -- 조회수 insert 안했을때 0이 들어가고 제목을 클릭하면 count에 저장된 값에 대해 1씩 증가(update해주어야한다)
good int, -- 좋아요도 마찬가지로 insert 안했을때 0이 들어가고 좋아요 버튼을 클릭하면 good에 저장된 값에 대해 1씩 증가(update해주어야한다)
-- member 테이블의 id열이 부모열, board 테이블의 id열이 자식열
foreign key(id) references member(id)
);
-- table만들때 못적었으면 아래와 같이 작성
-- alter table board add constraint foreign key(m_id) references member(m_id);
이런식으로 값을 입력한 것을 회원가입을 누르면 값이 저장되도록 만들어 주어야한다.
desc 로 확인해보면 member에서 id는 기본키
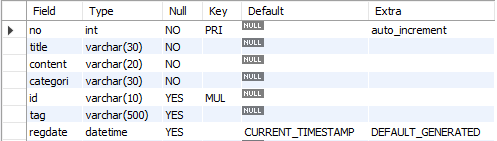
desc로 board도 확인해보면 id에 외래키로 지정된 것을 확인할 수 있다.
insert into board(title,categori, content, id)
values('안녕하세요.', '자유게시판','오늘 정모 있습니다.','bbb');member에 id가 존재하지 않는 id로 입력해서 기본키인 아이디값이 맞지않아서 오류가 발생한다.
(기본키에 들어간 값과 외래키 설정을 확인)

insert into board(title,categori, content, id)
values('안녕하세요.', '자유게시판','오늘 정모 있습니다.','zzzz');
데이터베이스 설계
- DB설계/DB구현
테이블 명세서 : 데이터베이스에서 사용되는 테이블의 구조와 속성을 정의하는 문서입니다. 이 문서는 데이터베이스 개발자나 데이터베이스 관리자가 테이블을 생성하고 관리하는 데 사용됩니다.
SQL 테이블 명세서는 일반적으로 다음과 같은 정보를 포함합니다.
- 테이블 이름
- 테이블이 사용할 데이터베이스 이름
- 각 열(column)의 이름
- 각 열의 데이터 타입(data type)
- 각 열의 크기(size)
- 각 열이 NULL 값을 허용하는지 여부
- 각 열이 기본값(default)을 가지는지 여부
- 각 열이 Primary Key, Foreign Key, Unique Key 등의 제약 조건을 가지는지 여부
SQL 테이블 명세서는 데이터베이스 스키마 설계 및 변경, 데이터베이스 구성 관리 등에 사용됩니다.
ERD Diagram
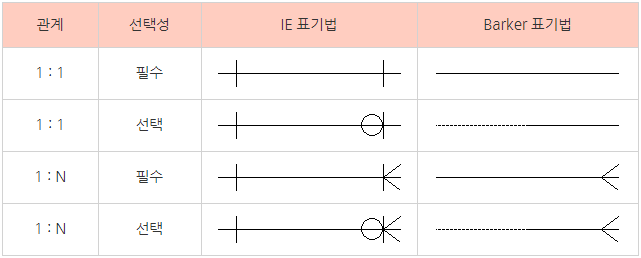
실선(identifying) : 부모 테이블의 기본키(pk)가 되는 경우
부모가 있어야 자식이 생기는 경우
점선(NON-identifying) : 부모 테이블의 기본키(pk)가 자식 테이블(fk)가 되는 경우
자식 테이블(fk)의 일반속성이 되는 경우
기호의 종류(도형 혹은 식별자)
|: 1개 / 실선은(dash) ‘1'을 나타낸다.
∈: 여러개 / 까마귀 발(crow’s foot or Many)은 ‘다수' 혹은 '그 이상'을 나타낸다.
○: 0개 / 고리(ring or Optional)은 ‘0'을 나타낸다.
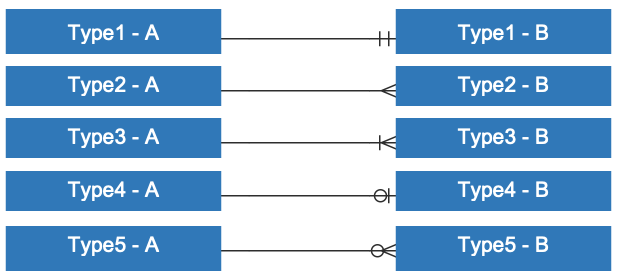
Type1(실선과 실선): 정확히 1 (하나의 A는 하나의 B로 이어져 있다.)
Type2(까마귀발): 여러개 (하나의 A는 여러개의 B로 구성되어 있다.)
Type3(실선과 까마귀발): 1개 이상 (하나의 A는 하나 이상의 B로 구성되어 있다.)
Type4(고리와 실선): 0 혹은 1 (하나의 A는 하나 이하의 B로 구성되어 있다.)
Type5(고리와 까마귀발): 0개 이상 (하나의 A는 0또는 하나 이상의 B로 구성되 있다.)
**[ERD 예제]**
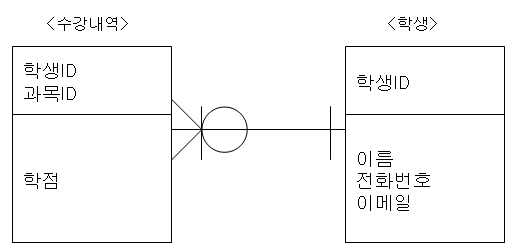
 는 1을 뜻하기 때문에 '하나의 학생'
는 1을 뜻하기 때문에 '하나의 학생'
수강내역 테이블의
 는 0~N을 뜻하기 때문에 '0~N 개의 수강내역'을 뜻한다.
는 0~N을 뜻하기 때문에 '0~N 개의 수강내역'을 뜻한다.
수강내역의 입장에서는 '0~N 개의 수강내역은 하나의 학생에게 포함되어 진다'라고 해석이 가능하다.
위 내용을 바탕으로 유추해 본다면 ERD의
- 부모 테이블은 학생 테이블이다.
- 자식 테이블은 수강내역 테이블이다.
- 부모 테이블의 PK를 자식 테이블에서 PK로 사용하고 있다.
- 학생 한 명은 0~N 개의 수강내역을 가진다.
- 수강내역은 하나의 학생을 가진다.
- 수강내역 테이블은 학생 테이블의 PK인 [ 학생ID ]를 FK로 가진다.
[Mysql에서 ERD 다이어그램 생성하기]
next 몇번 누르고 본인이 작업할 데이터베이스 영역을 체크해주고 넘기다보면 아래와 같은 화면이 나타난다.
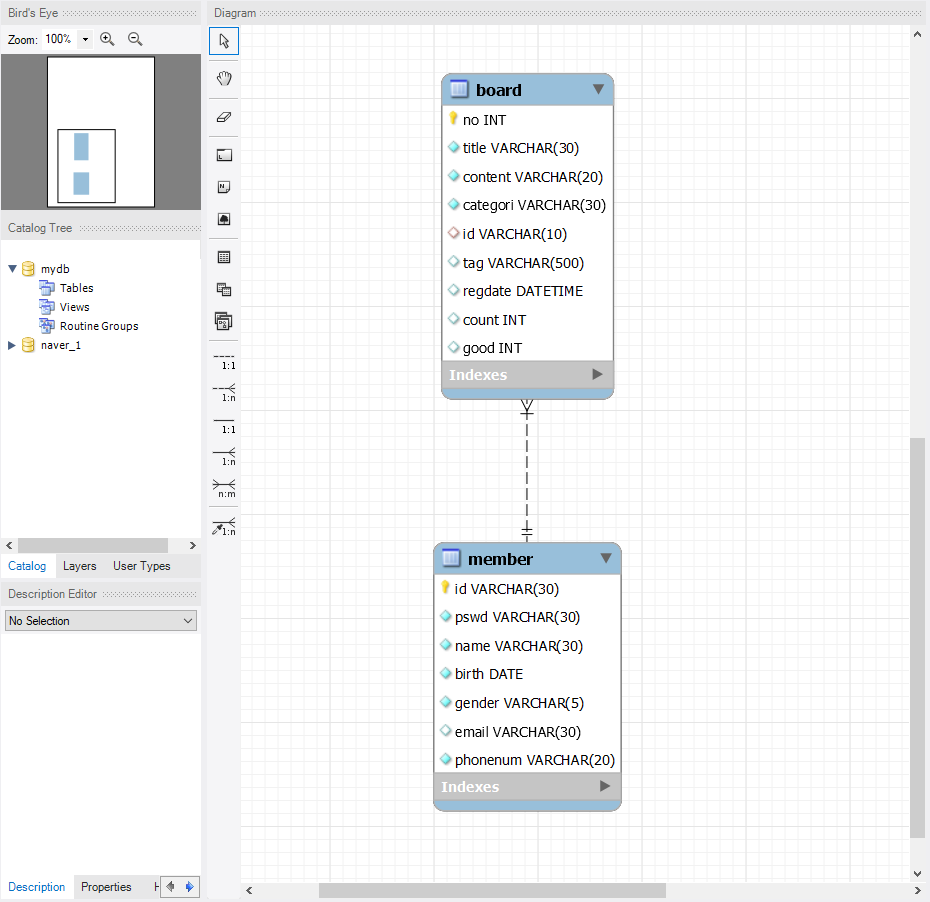
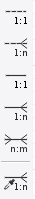
관계설정을 위해 아이콘을 눌러 해당 테이블에 클릭해서 이어주면 관계 생성이 된다.
(多쪽 먼저 클릭하고 1쪽 클릭.)
- IE표기법과 Barker표기법
정규화
정규화 : 데이터베이스 설계 시 중복 데이터를 제거하고 데이터를 더욱 효율적으로 저장하기 위한 기법입니다. 데이터베이스 정규화는 데이터 중복을 줄이면서 데이터 일관성을 유지하기 위해 테이블을 분해하는 과정입니다. 정규화는 보통 1차 정규화부터 5차 정규화까지 총 5단계로 이루어집니다.
1차 정규화: 테이블의 컬럼이 원자적인 값을 가지도록 테이블을 분해합니다. 이 과정에서 테이블은 중복된 데이터를 가지지 않게 됩니다.
2차 정규화: 테이블에 기본키를 정의하고, 모든 컬럼이 기본키에 종속되도록 테이블을 분해합니다. 이 과정에서는 부분 함수 종속성을 제거합니다.
3차 정규화: 테이블에서 후보키가 아닌 모든 컬럼이 기본키에 종속되도록 테이블을 분해합니다. 이 과정에서는 이행적 함수 종속성을 제거합니다.
4차 정규화: 테이블에서 다중값 종속성을 제거하기 위해 테이블을 분해합니다.
5차 정규화: 조인을 이용하여 테이블을 분해하여 데이터의 일관성을 유지합니다.
정규화를 통해 데이터베이스는 중복 데이터를 제거하고 일관성 있는 데이터를 유지할 수 있습니다. 그러나, 과도한 정규화는 데이터베이스 성능을 저하시킬 수 있으므로, 테이블을 적절한 수준으로 분해하는 것이 중요합니다.
제1 정규형 (1NF)
제1 정규형은 다음과 같은 규칙들을 만족해야 한다.
- 각 컬럼이 하나의 속성만을 가져야 한다.
- 하나의 컬럼은 같은 종류나 타입(type)의 값을 가져야 한다.
- 각 컬럼이 유일한(unique) 이름을 가져야 한다.
- 칼럼의 순서가 상관없어야 한다.
조금 복잡해보이지만, 간단하게 예시를 들면 이해가 빠르다. 아래 테이블을 살펴보자.
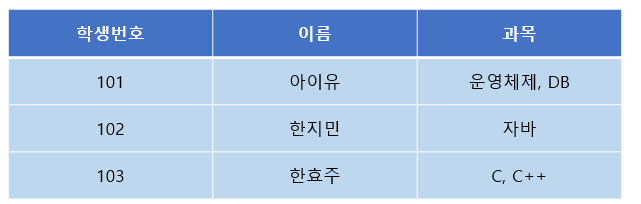
[그림 1] 1정규화가 필요한 테이블
각 컬럼이 하나의 값(속성)만을 가져야 한다. -> 불만족! 하나의 칼럼(과목)에 두 개의 값을 가짐
하나의 컬럼은 같은 종류나 타입(type)의 값을 가져야 한다. -> 만족
각 컬럼이 유일한(unique) 이름을 가져야 한다. -> 만족
칼럼의 순서가 상관없어야 한다. -> 만족
1번 규칙을 불만족하므로 이를 고치기 위해서는 아래와 같이 분해하면 된다.
[그림 2] 1NF
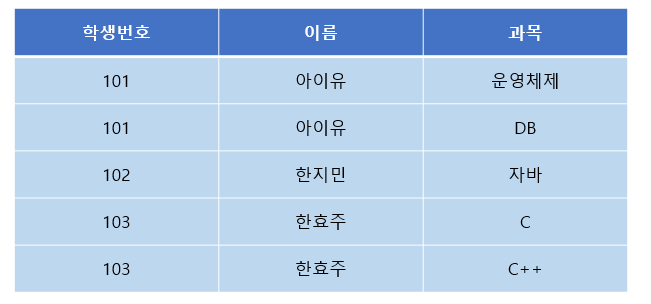
위와 같이 각 칼럼이 원자 값을 갖도록 테이블을 분해하면 1 정규형을 만족하게 바꿀 수 있다.
제2 정규형 (2NF)
제2 정규형은 다음과 같은 규칙을 만족해야 한다.
- 1정규형을 만족해야 한다.
- 모든 컬럼이 부분적 종속(Partial Dependency)이 없어야 한다. == 모든 칼럼이 완전 함수 종속을 만족해야 한다.
부분적 종속이란 기본키 중에 특정 컬럼에만 종속되는 것이다.
완전 함수 종속이란 기본키의 부분집합이 결정자가 되어선 안된다는 것이다. ( 비슷한 말이다 )
[그림 3] 2정규화가 필요한 테이블
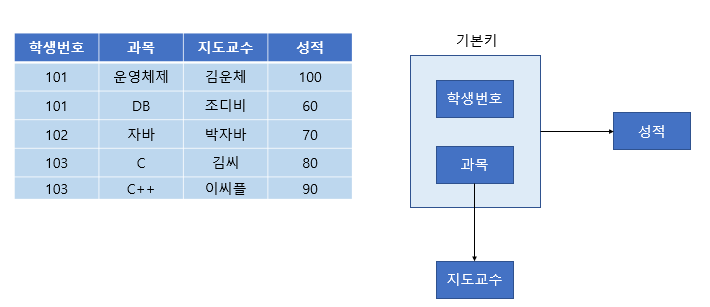
위와 같은 테이블과 FD 다이어그램을 보자.
성적의 특정 값을 알기 위해서는 학생 번호+과목이 있어야 한다. (ex : 102번의 자바 성적 70 )
하지만 특정 과목의 지도교수는 과목명만 알면 지도교수가 누군지 알 수 있다. (ex : 자바의 지도교수 박자바)
위 테이블에서 기본키는 (학생 번호, 과목)으로 복합키이다.
그런데 이때 지도교수 칼럼은 (학생 번호, 과목)에 종속되지 않고 (과목) 에만 종속되는 부분적 종속이다.
따라서 제2 정규화를 만족하지 않으므로 아래와 같이 분해해야 한다.
[그림 4] 2NF
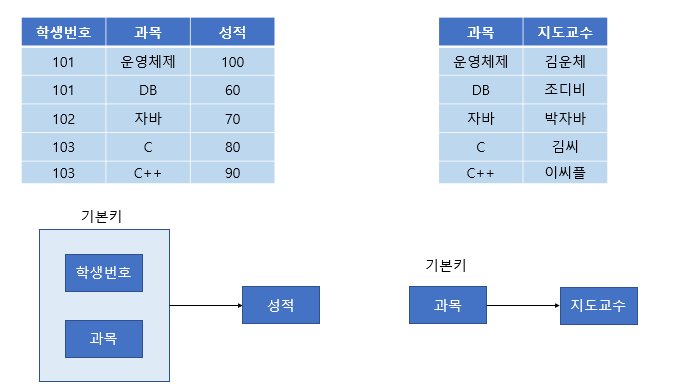
위와 같이 분해하면 제2 정규형을 만족한다.
제3 정규형 (3NF)
제3 정규형은 다음과 같은 규칙을 만족해야 한다.
- 2 정규형을 만족해야 한다.
- 기본키를 제외한 속성들 간의 이행 종속성 (Transitive Dependency)이 없어야 한다.
이행 종속성이란 A->B, B->C 일 때 A->C 가 성립하면 이행 종속이라고 한다.
[그림 5] 3정규화가 필요한 테이블
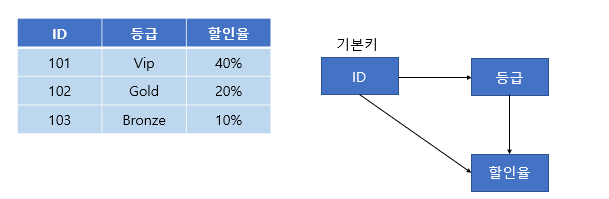
위와 같은 테이블을 보자. ID를 알면 등급을 알 수 있다. 등급을 알면 할인율을 알 수 있다. 따라서 ID를 알면 할인율을 알 수 있다. 따라서 이행 종속성이 존재하므로 제 3 정규형을 만족하지 않는다.
3정규형을 만족하기 위해서는 아래와 같이 분해해야 한다.
[그림 6] 3NF
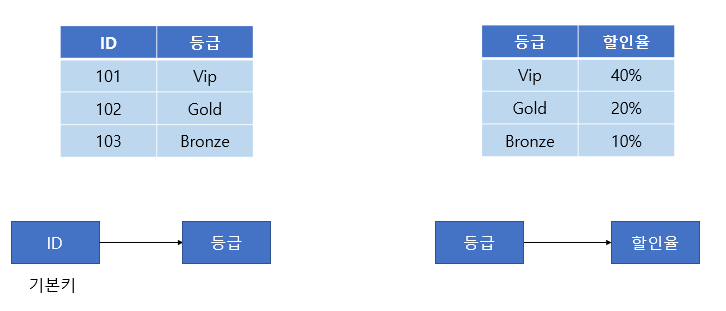
위와 같이 분해하면 제 3정규형을 만족한다.
BCNF (Boyce-Codd Normal Form)
BCNF는 제 3정규형을 좀 더 강화한 버전으로 다음과 같은 규칙을 만족해야 한다.
- 3정규형을 만족해야 한다.
- 모든 결정자가 후보키 집합에 속해야 한다.
모든 결정자가 후보키 집합에 속해야 한다는 뜻은, 후보키 집합에 없는 칼럼이 결정자가 되어서는 안 된다는 뜻이다.
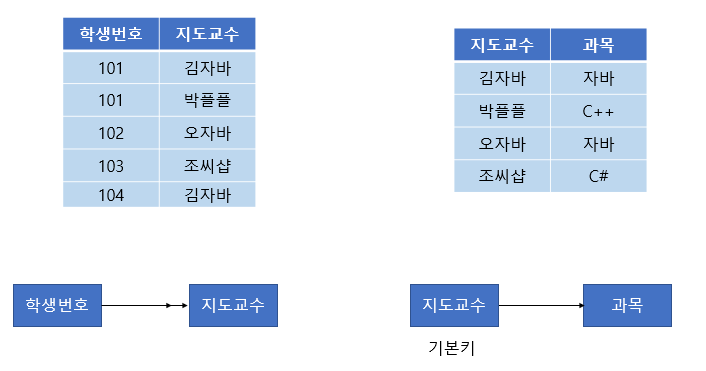
[그림 7] BCNF가 필요한 테이블
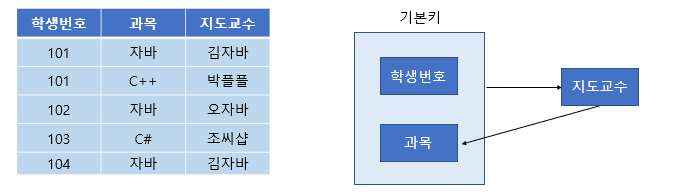
위와 같은 테이블을 보자. (학생 번호, 과목)이 기본키로 지도교수를 알 수 있다. 하지만 같은 과목을 다른 교수가 가르칠 수도 있어서 과목-> 지도교수 종속은 성립하지 않는다. 하지만 지도교수가 어떤 과목을 가르치는지는 알 수 있으므로 지도교수-> 과목 종속이 성립한다.
이처럼 후보키 집합이 아닌 칼럼이 결정자가 되어버린 상황을 BCNF를 만족하지 않는다고 한다.
(참고로 위 테이블은 제3 정규형까지는 만족하는 테이블이다 )
BCNF를 만족하기 위해서는 아래와 같이 분해하면 된다.
[그림 8] BCNF
참고로 위에서 학생 번호와 지도교수는 다치 종속성이 발생하게 되는데, 이는 제4 정규형에서 다뤄진다.
제4 정규형 이상~
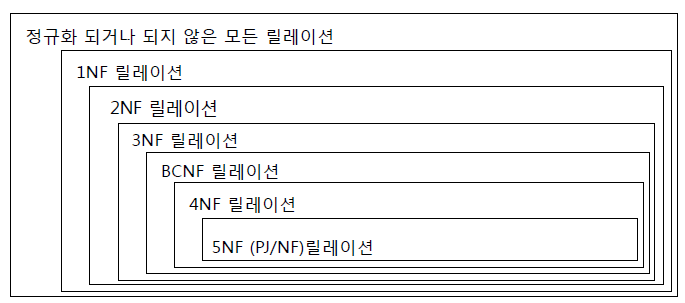
Normalization
정규형
보통 정규화는 BCNF 까지만 하는 경우가 많다. 그 이상 정규화를 하면 정규화의 단점이 나타날 수도 있다.
제4 정규형(4NF)
제4 정규형은 다음과 같은 규칙을 만족해야 한다.
- BCNF를 만족해야 한다.
- 다치 종속(Multi-valued Dependency)이 없어야 한다.
여기서 다치 종속이란 다음과 같은 조건들을 만족할 때를 뜻한다.
-
A->B 일 때 하나의 A값에 여러 개의 B값이 존재하면 다치 종속성을 가진다고 하고 A↠B라고 표시한다
-
최소 3개의 칼럼이 존재한다.
-
R(A, B, C)가 있을 때 A와 B 사이에 다치 종속성이 있을 때 B와 C가 독립적이다.
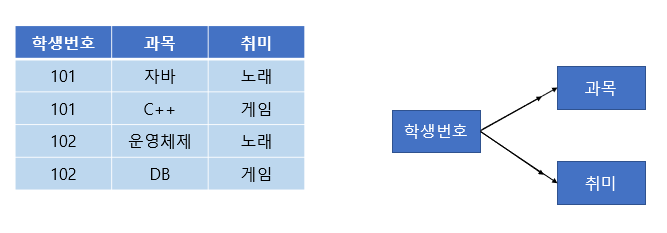
위와 같은 테이블을 보자. 101번 학생은 자바와 C++ 과목을 수강하고, 노래와 게임을 취미로 가진다.
이렇게 되면 학생 번호 하나에 과목 여러 개와 취미 여러 개가 종속된다. 이런 경우 학생 번호를 토대로 값을 조회하면 아래와 같이 중복이 발생하게 된다.
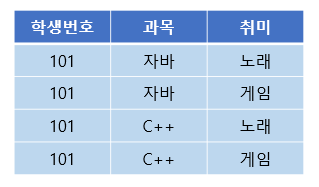
과목과 취미는 관계가 없는 독립적인 관계이다. 하지만 같은 테이블의 학생 번호라는 칼럼에 다치 종속되어버려 중복이 발생하는 문제가 생겼다.
4NF를 만족하기 위해서는 아래와 같이 분해하면 된다.
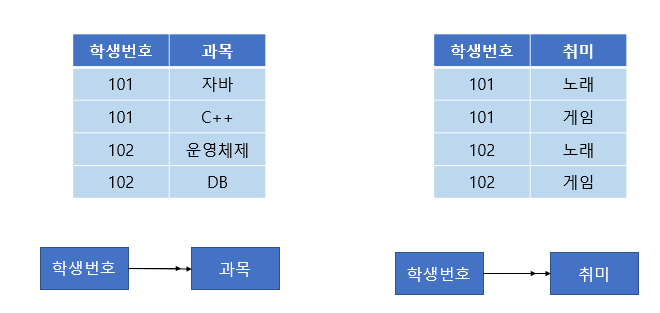
위 2개의 테이블은 여전히 다치 종속성을 가지지만, 2개 이상의 칼럼이 하나의 칼럼에 다치 종속되지는 않기 때문에 제4 정규형을 만족한다.
제5 정규형(5NF)
제5 정규형은 중복을 제거하기 위해 분해할 수 있을 만큼 전부 분해하는 것이다. 이러한 5NF는 Project Join Normal Form(PJNF)라고도 불린다. 이러한 제 5정규형은 다음과 같은 규칙을 만족해야 한다.
- 4NF를 만족해야 한다.
- 조인 종속(Join dependency)이 없어야 한다.
- 조인 연산을 했을 때 손실이 없어야 한다.
조인 종속은 다치 종속의 좀 더 일반화된 형태이다. 만약 하나의 릴레이션을 여러 개의 릴레이션으로 무손실 분해했다가 다시 결합할 수 있다면 조인 종속이라고 한다.
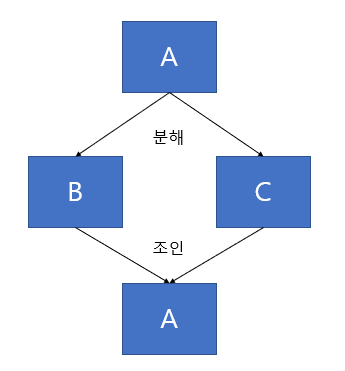
예를 들어 A라는 릴레이션을 B와 C로 분해했다가 다시 조인했을 때 그대로 A가 된다면, A는 조인 종속성이 있다고 한다.
제5 정규형의 경우 예시를 들기 복잡하기 때문에 생략하겠다.
정규화 내용 출처 : https://code-lab1.tistory.com/48
트랜잭션
트랜잭션 : 두개 이상의 sql을 동시다발로 실행하고자 할때 사용
[예시]
select * from board where no = 1125;
update board set count = count + 1 where no = 1125;
start transcation
select * from board where no = 1125;
update board set count = count + 1 where no = 1125;
select와 update 둘다 성공했으면 commit
select와 update 둘 중 하나라도 실패했으면 rollback데이터베이스의 상태를 변화시키는 하나의 논리적인 작업 단위입니다. 트랜잭션은 하나 이상의 SQL 쿼리를 묶어서 하나의 작업으로 처리하며, 이 작업은 모두 실행되거나, 모두 실행되지 않아야 합니다. 즉, 모든 작업이 성공하면 전체 트랜잭션이 성공으로 처리되고, 하나라도 실패하면 전체 트랜잭션은 실패 처리됩니다.
트랜잭션은 데이터의 무결성과 일관성을 보장하기 위해 필요합니다. 데이터베이스에서 데이터의 변경이 발생하면, 해당 작업을 트랜잭션으로 묶어서 처리하면, 데이터의 일관성이 유지됩니다. 만약 작업 중 일부가 실패하면, 이전 상태로 롤백하거나, 작업이 완료되지 않은 상태로 유지되므로 데이터의 무결성이 유지됩니다.
트랜잭션은 일반적으로 4가지의 속성을 갖습니다. 이것을 ACID라고 합니다.
-
원자성(Atomicity) : 트랜잭션은 원자적(Atomic)이어야 합니다. 즉, 트랜잭션 내의 모든 작업은 전부 실행되거나 전부 실행되지 않아야 합니다.
-
일관성(Consistency) : 트랜잭션을 실행한 결과는 일관성 있어야 합니다. 즉, 데이터베이스의 제약 조건을 위반하지 않아야 합니다.
-
고립성(Isolation) : 동시에 여러 트랜잭션이 실행될 때, 각각의 트랜잭션은 독립적으로 실행되는 것처럼 보여야 합니다. 즉, 다른 트랜잭션에 영향을 받지 않고 실행되어야 합니다.
-
지속성(Durability) : 트랜잭션을 성공적으로 완료하면, 해당 작업 결과는 영구적으로 저장되어야 합니다. 즉, 시스템 장애가 발생해도 데이터의 일관성을 유지할 수 있어야 합니다.
트랜잭션은 BEGIN TRAN, COMMIT, ROLLBACK과 같은 SQL 문을 사용하여 수행됩니다. BEGIN TRAN 문은 트랜잭션을 시작하고, COMMIT 문은 트랜잭션을 완료하고 변경 내용을 데이터베이스에 반영합니다. ROLLBACK 문은 트랜잭션 내에서 발생한 모든 변경 내용을 취소하고 이전 상태로 되돌립니다.
트랜잭션은 데이터베이스에서 무결성을 유지하고 데이터의 일관성을 보장하는 데 중요합니다. 하나의 트랜잭션 내에서 발생한 모든 작업이 전체적으로 성공하거나 실패하기 때문에 데이터베이스에서 발생할 수 있는 문제를 예방하고 데이터 무결성을 유지할 수 있습니다.
Auto commit
Auto commit은 데이터베이스에서 쿼리를 실행할 때 자동으로 COMMIT 문이 실행되어, 쿼리 결과가 즉시 데이터베이스에 반영되는 것을 말합니다. 이것은 일반적으로 데이터베이스에서 기본적으로 설정되어 있습니다.
Auto commit이 활성화되면, 각 쿼리문 실행 후 해당 쿼리에 대한 변경 사항이 데이터베이스에 즉시 적용됩니다. 이것은 단일 쿼리 실행의 경우에는 편리하지만, 여러 쿼리가 수행되는 트랜잭션에서는 문제가 발생할 수 있습니다. 예를 들어, 여러 개의 쿼리문이 하나의 트랜잭션으로 묶여 있을 때, 첫 번째 쿼리문에서 오류가 발생하면 해당 트랜잭션 전체가 롤백되어야 할 수 있습니다. 하지만 auto commit이 활성화되어 있으면 첫 번째 쿼리문에서 오류가 발생하여 롤백이 필요한 경우, 이전까지 실행된 모든 쿼리문에 대한 변경 사항이 이미 데이터베이스에 적용되어 있기 때문에 롤백이 불가능합니다.
따라서, auto commit을 사용하는 경우에는 데이터의 일관성과 무결성에 대한 위험이 존재합니다. 따라서, 트랜잭션을 수행할 때에는 auto commit을 비활성화하여, 모든 쿼리문이 트랜잭션 내에서 묶여 실행되고, 트랜잭션의 성공 여부에 따라 적용되거나 롤백되도록 구성해야 합니다. 이를 통해 데이터베이스의 무결성과 일관성을 보장할 수 있습니다.
[네이버 게시물 클릭했을때 조회수 올리는법]
select * from board where no = 3; -- 3번 게시물 title을 클릭하면
update board set count = count+1 where no = 3;
select * from board;
위 코드에서 일부러 board에 오타를 내보았습니다.
select * from bord where no = 3; -- 3번 게시물 title을 클릭하면
update board set count = count+1 where no = 3;select 결과에 상관없이 auto commit 되어서 count+1 모습입니다.

트랜잭션을 사용
start transaction;
select * from board where no = 3; -- 3번 게시물 title을 클릭하면
update board set count = count+1 where no = 3;
-- 정상적으로 select와 update가 되는 경우
-- commit
start transaction;
select * from bod where no = 3; -- 3번 게시물 title을 클릭하면
update board set count = count+1 where no = 3;
-- update는 정상적으로 수행되었으나, select가 제대로 작동하지 않았음. : count값을 원래대로 되롤려 줘야함.
rollback;
-- commit
select * from board;
현재 count 7인 상황
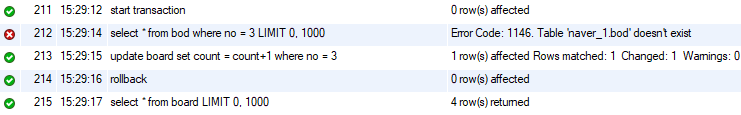
rollback으로 8이 되지않았음.
