
썸네일 이미지는 AI를 활용했지만, 글은 모두 직접 작성했습니다.
🪄 TL;DR
- 말로만 듣던 React Router를 직접 사용해보았다.
- 처음에는 모든 페이지에서 공통으로 보여줄 Header를 Router 밖에 두었다. 이상 없이 동작했지만 React Developer Tools로 구조를 보니 무언가 어색했다.
- 결국 레이아웃을 라우트의 element로 옮기고, 자식 화면은 Outlet으로 렌더링하는 방식으로 바꾸었다.
- 이러한 과정을 거치며 React Router는 단순히 페이지만 이동 시키는 도구가 아니라, 화면 구조와 레이아웃 계층을 설계하는 도구라는 걸 느꼈다.
- lazy, Suspense, ErrorBoundary, ScrollToTop까지 붙여보았다.
Prerequisite
이 글에서는 React Router의 사용법을 설명하지 않는다. 다만 React Router가 무엇인지도 잘 모르던 내가 직접 시행착오를 겪으며 구현한 경험을 담았다.
최종적으로 BrowserRouter, Routes, Route, Outlet, lazy를 적용했고, 현재 내 코드는 BrowserRouter + Routes + Route를 쓰는 가장 기본적인 Declarative mode 형태이다. React Router는 현재 Declarative / Data / Framework 세 가지 모드를 제공하고 있다.
React Router의 세 가지 모드
- Declarative:
<BrowserRouter>,<Routes>,<Route>를 JSX 안에서 직접 선언하는 방식 - Data:
createBrowserRouter같은 API를 사용해 라우트 정의와 함께 데이터 로딩, 액션 등을 다루는 방식 - Framework: React Router를 더 프레임워크처럼 사용하는 방식. Vite 플러그인, route module, 자동 코드 분할, scroll restoration 같은 기능까지 포함
Header를 아무데나 두는 게 아니었다!
처음에는 모든 페이지에 헤더가 필요하다고 생각해서 그냥 라우트 바깥에 헤더를 두었다.
export const AppRoutes = () => {
return (
<BrowserRouter>
<Header />
<div className="content-wrapper">
<Routes>
<Route path="/" element={<MainPage />} />
<Route path="/issue" element={<IssuePage />} />
<Route path="/stock" element={<StockPage />} />
<Route path="*" element={<NotFoundPage />} />해당 코드는 아무런 문제 없이 잘 동작했기 때문에 별 생각 없이 넘어갔다. 하지만 React developer tools로 확인해보자 내가 만든 구조에서 이상한 점을 발견할 수 있었다.
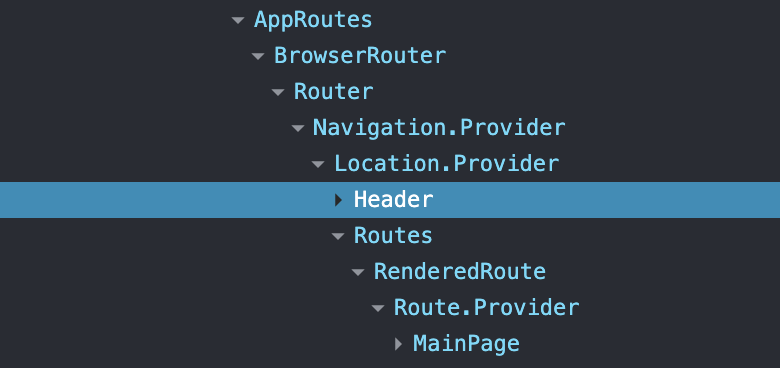
Header가 Routes 밖에 위치하고 있다.
모든 페이지에서 헤더가 잘 보여지고 있었지만, 구조적으로 볼 때 헤더는 라우터가 관리하는 레이아웃 계층 바깥에 놓여 있었다.
해당 구조가 당장 에러를 일으키거나 화면 상에서 문제를 일으키는 건 아니다. 하지만 다른 더 좋은 방향이 있을지 고민하며 헤더와 관련된 여러 상황들을 가정해보았다.
- 특정 페이지에서 헤더를 숨겨야 한다면?
- 화면 별로 헤더가 다르게 보여져야 한다면?
- 공통 UI의 범위를 라우터 안에 지정해주면 어떨까?
이런 생각들을 하다보니 지금의 구조가 확장에 불리한 구조라는 생각이 들었다.
React Router의 역할에 대해서
처음에는 React Router를 단순히 페이지 이동 라이브러리 정도로 생각했다.
실제로 BrowserRouter는 브라우저 주소창과 내장 history stack을 사용해 클라이언트 사이드 라우팅을 수행하는 선언형 라우터다. (이 개념은 이후 딥다이브 해 볼 예정!) 전통적인 방식처럼 새 문서를 다시 요청하는 대신, URL 변화에 맞춰 필요한 UI를 렌더링한다.
그런데 공식 문서를 조금 더 살펴 보니, 더 중요한 게 따로 있었다.
React Router에서 라우트는 단순히 URL 하나에 컴포넌트 하나를 대응시키는 것이 아니었다. React Router는 URL 세그먼트와 컴포넌트 계층을 연결하고, 중첩 라우트를 통해 레이아웃 구조를 자연스럽게 표현하게 만든다. 공식 문서도 중첩 라우트를 통해 자동 레이아웃 중첩이 가능하다고 설명하고 있었다.
내가 처음 Header를 Routes 밖에 두었던 건 React Router의 역할에 대한 이해가 부족했기 때문이었다. 그저 경로에 따라 화면을 바꾸는 도구로만 이해하고 있었지만, 사실 더 중요한 건 React Router가 레이아웃 계층을 표현하는 도구였다는 것이다.
React Router가 바꾼 라우팅 방식
예전 웹의 전통적인 페이지 라우팅에서는 다른 화면을 보여주기 위해 문서에서 다른 문서로 이동했다. 서버에서 새 페이지를 다시 내려받고, 브라우저는 그 문서를 기준으로 새로운 화면을 보여주게 된다.
반면 React Router 같은 클라이언트 사이드 라우팅에서는 브라우저 history stack을 조작하면서, 새 문서를 다시 요청하지 않고 현재 앱 안에서 필요한 UI만 유연하게 교체할 수 있다. React Router 문서도 client side routing을 “문서 요청 없이 browser history stack을 조작하는 방식”으로 설명하고 있다.
또 React Router v6에서는 예전 v5의 <Route component> 나 <Route render> 중심 방식에서 <Route element> 중심 방식으로 옮겨왔다. 공식 FAQ도 v6에서 render나 component 대신 element를 쓰는 이유를 설명한다.
해당 변화는 단순히 문법만 바뀐 게 아니라 라우트를 더 트리처럼 생각하게 한다. 이전 방식에서는 어떤 경로에서 어떤 컴포넌트를 보여줄지를 중심으로 구조를 구성했다면, 지금은 레이아웃의 중첩 구조를 중심으로 각 하위에 어떤 화면이 들어올지를 중심으로 구조를 구성하게 된다.
중첩 라우트와 Outlet으로 레이아웃 다시 잡기
그렇다면 헤더는 어디에 두어야 할까?
이 질문에 대해 파고들다 보니 결국 Layout과 Outlet이라는 개념으로 오게 되었다. React Router에서는 부모 라우트 아래에 자식 라우트를 중첩할 수 있고, 자식 라우트는 부모 컴포넌트의 위치에 렌더링된다.
또한 index route는 부모 URL에서 기본으로 렌더링되는 자식 라우트이고, path가 없는 route는 URL 세그먼트를 추가하지 않는 layout route로 사용할 수 있다.
우선 Header를 직접 넣던 방식을 지우고, 헤더를 포함한 MainLayout을 따로 만들었다. 페이지 전체 스타일을 담당하던 content-wrapper도 이쪽으로 옮겼다.
export const MainLayout = () => {
return (
<>
<Header />
<div className="content-wrapper">
<Outlet />
</div>
</>
);
};여기서 핵심은 Outlet이다.
children은 부모가 자식을 직접 넘겨주는 방식이라면, Outlet은 현재 URL에 맞는 다음 라우트 매치를 라우터가 렌더링하는 자리에 가깝다. React Router는 Outlet을 “다음 match를 렌더링하는 컴포넌트”라고 설명한다.
이 개념을 반영해 Routes 구조를 다시 짜보면 이렇게 된다.
export const AppRoutes = () => {
return (
<BrowserRouter>
<Routes>
<Route path="/" element={<MainLayout />}>
<Route index element={<MainPage />} />
<Route path="issue" element={<IssuePage />}>
<Route path=":id" element={<IssuePage />} />
</Route>
<Route path="stock" element={<StockPage />}>
<Route path=":ticker" element={<StockPage />} />
</Route>
<Route path="*" element={<NotFoundPage />} />
</Route>여기서 함께 적용한 개념도 정리해보겠다.
index라우트는 부모 URL 자체에서 렌더링되는 기본 자식 라우트다.:id,:ticker같은 동적 세그먼트는 URL 값을 변수처럼 받아오며,useParams()로 꺼내 쓸 수 있다.- 는 와일드카드로, 정의되지 않은 경로를 잡아낼 때 사용할 수 있다. React Router는 이런 패턴을 star segment로 설명한다.
정리하자면 핵심은 부모 라우트가 레이아웃을 가지고, 자식 라우트가 그 레이아웃 안에 들어가도록 만드는 것이다. 이렇게 구조를 짜고 나니 URL 구조와 UI 구조를 같은 그룹 안에서 제어할 수 있게 되었다.
ErrorBoundary와 Suspense는 어디에?
lazy, Suspense, ErrorBoundary를 붙이기 시작하면서 또 다른 고민이 생겼다. 처음에는 AppRoutes 안에 Suspense와 ErrorBoundary를 같이 두었다.
export const AppRoutes = () => {
return (
<BrowserRouter>
<ErrorBoundary fallback={<div>Error 발생!</div>}>
<Suspense fallback={<Loading />}>
<Routes>
<Route element={<MainLayout />}>
<Route path="/">
<Route index element={<MainPage />} />
<Route path="*" element={<NotFoundPage />} />
</Route>
<Route path="/issue">
<Route index element={<IssuePage />} />
<Route path=":id" element={<IssueDetailPage />} />
</Route>
<Route path="/stock">
<Route index element={<StockPage />} />
<Route path=":ticker" element={<StockDetailPage />} />
</Route>
</Route>처음에는 한 파일에서 다 보여서 편했지만, 현재 구조에서는 AppRoutes가 너무 많은 책임을 지고 있었다.
- 어떤 경로에서 어떤 화면을 보여주는지
- 로딩 중에는 무엇을 보여주는지
- 에러가 나면 무엇을 보여주는지
이 세 가지는 각자 중요한 역할을 하고 있지만, 같은 관심사가 아니었다. 그래서 AppRoutes는 라우트 정의 자체에 집중하도록 두고, Suspense와 ErrorBoundary는 별도의 Provider로 분리했다.
이렇게 파일을 분리하자 각 파일의 역할이 명확해졌다. 라우트 파일은 라우트에 대한 책임만, 로딩과 에러는 Provider 안에서 처리하게 되었다.
lazy는 무엇인지
페이지 컴포넌트들은 lazy로 불러오고 있다.
const MainPage = lazy(() => import('features/pages/MainPage/MainPage'));
const IssuePage = lazy(() => import('features/pages/IssuePage/IssuePage'));
const IssueDetailPage = lazy(
() => import('features/pages/IssueDetailPage/IssueDetailPage'),
);
const StockPage = lazy(() => import('features/pages/StockPage/StockPage'));
const StockDetailPage = lazy(
() => import('features/pages/StockDetailPage/StockDetailPage'),
);lazy는 컴포넌트를 처음 렌더링하려는 시점까지 로드를 미루는 지연 로딩 방식이다. 아직 로드되지 않은 경우 렌더링이 suspend 되기 때문에 상위에 Suspense가 필요하다. Promise가 reject되면 가장 가까운 Error Boundary가 이를 처리한다.
Suspense와 ErrorBoundary를 적용하며 자연스럽게 lazy를 사용하게 되었고, 당장 필요하지 않은 페이지 코드를 나중에 불러오도록 하여 초기 번들 부담을 줄였다.
ScrollToTop을 따로 만든 이유
SPA로 화면을 이동하다 보면 무언가 어색하게 느껴지는 순간이 있는데, 그건 바로 스크롤 위치 때문이었다. 예를 들어 어떤 페이지를 아래까지 스크롤한 뒤 다른 페이지로 이동하면, 새로운 화면도 아래에서 시작해버리는 현상이 있었다. 이 현상이 사용자 경험을 불편하게 한다고 느꼈고, 화면 전환 시 스크롤을 맨 위로 초기화해주는 기능이 필요하다고 생각했다.
React Router에서 이를 해결할 수 있는 방법이 있는지 확인했다. 실제로 ScrollRestoration이라는 기능이 존재했지만, 이 기능은 Data Router에서만 동작한다는 제약이 있었다.
또 하나 중요한 점은, ScrollRestoration은 기본적으로 이전 스크롤 위치를 복원하는 기능이라는 것이다. 반면 나는 항상 맨 위로 리셋하는 동작이면 충분했기 때문에, 목적에 맞게 커스텀한 ScrollToTop을 구현했다.
import { useEffect } from 'react';
import { useLocation } from 'react-router-dom';
export const ScrollToTop = () => {
const { pathname } = useLocation();
useEffect(() => {
window.scrollTo(0, 0);
}, [pathname]);
return null;
};export const AppRoutes = () => {
return (
<BrowserRouter>
<ScrollToTop />
<Routes>
<Route path="/" element={<MainLayout />}>
<Route index element={<MainPage />} />
<Route path="*" element={<NotFoundPage />} />
</Route>페이지 전환 시 스크롤을 단순히 초기화하는 수준으로 구현했기 때문에, 뒤로가기를 눌렀을 때 이전 위치를 복원하려면 추가적인 상태 관리나 설계가 필요하다.
현재는 스크롤 위치 리셋이라는 최소한의 문제 해결에 집중해 구현하였다.
최종 구조
작업을 진행하며 메인 레이아웃뿐 아니라, 상단 앱 바가 필요한 화면군도 분리할 필요가 있다고 판단했다. 그래서 MainLayout과 AppBarLayout을 나누어 아래와 같이 구성했다.
export const AppRoutes = () => {
return (
<BrowserRouter>
<ScrollToTop />
<Routes>
<Route path="/" element={<MainLayout />}>
<Route index element={<MainPage />} />
<Route path="*" element={<NotFoundPage />} />
</Route>
<Route element={<AppBarLayout />}>
<Route path="/issue">
<Route index element={<IssuePage />} />
<Route path=":id" element={<IssueDetailPage />} />
</Route>
<Route path="/stock">
<Route index element={<StockPage />} />
<Route path=":ticker" element={<StockDetailPage />} />
</Route>
</Route>여기서 <Route element={<AppBarLayout />}>처럼 path 없이 레이아웃만 두는 방식은 React Router가 공식적으로 지원하는 패턴이다. 이 방식은 URL 구조를 변경하지 않으면서, 특정 화면들을 공통 레이아웃 아래로 묶을 수 있게 해준다.
초기에 헤더를 라우트 바깥에 두었을 때와 비교해보면, 레이아웃을 기준으로 화면을 그룹화하면서 구조가 훨씬 명확해졌다.
마무리
이번에 React Router를 적용하며 느낀 점은, 라우터가 단순한 화면 전환 도구가 아니라는 것이었다.
처음에는 경로에 맞게 페이지를 이동시키는 역할로만 생각했지만, 실제로는 화면 구조와 계층을 설계하며, 서비스의 뼈대를 만드는 작업이었다.
- 이 URL 하위에는 어떤 화면들이 들어와야 하지?
- 공통 레이아웃은 어떻게 표현할까?
- 상태 관리는 어느 계층에서 처리해야 좋을까?
위와 같은 고민을 하며 라우터를 구성했고, layout도 적극적으로 활용했다. 무엇보다 화면에 잘 나오는 것을 넘어서 React Component 구조가 어떻게 되어 있는지, 그 구조를 라우터가 어떻게 해석하는지까지 함께 봐야한다는 것을 알게 되었다.
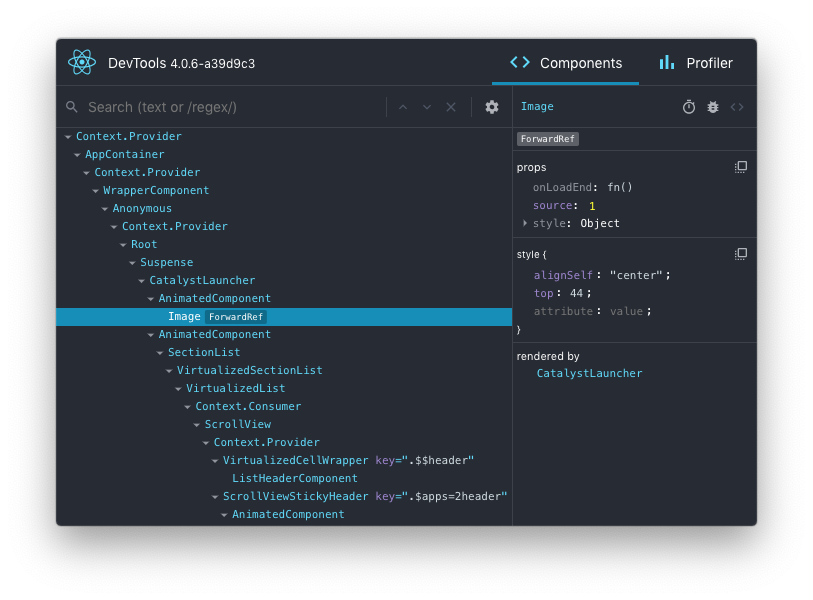
이 과정에서 React Developer Tools도 큰 도움이 되었다. 컴포넌트 계층 구조를 트리 형태로 확인할 수 있어서, 라우터로 구성한 레이아웃이 실제로 어떻게 렌더링되는지 한눈에 파악할 수 있었다. 이후 상태 관리를 도입할 때도, 상태 변화와 컴포넌트 리렌더링 흐름을 추적하는 데 유용하게 활용할 수 있을 듯 하다.
초기에 헤더를 라우트 바깥에 두었던 시점의 나는 라우터를 단순한 페이지 전환 도구로만 보고 있었다. 레이아웃을 element로 분리하고, 그 안에서 Outlet으로 구조를 나누면서 비로소 라우터를 구조적인 관점에서 이해하기 시작했다.
아직 더 개선할 수 있는 부분은 많지만, 이번 경험을 통해 React Router의 기본 개념과 활용 방식을 직접 체득할 수 있었다.
다음 글 예고
다음 글에서는 MSW를 활용해 개발 환경에서 서버를 직접 구성한 과정을 정리해보려고 한다.
처음에는 json-server로 간단하게 API를 구성하려 했지만, 실제 네트워크 흐름과는 차이가 있어 한계를 느꼈다. 이후 MSW로 전환하면서 요청을 가로채는 방식으로 더 실제 서버와 유사한 환경을 구성할 수 있었고, 이 과정에서 느낀 장단점과 선택 기준을 함께 정리해볼 예정이다.
프로젝트 진행 과정이 궁금하다면 아래 저장소에서도 함께 볼 수 있다.
그럼 안녕~~
