궁금한점이나 해석이 잘못된 부분이 있으면 언제든지 댓글로 말씀해주시면 감사하겠습니다.
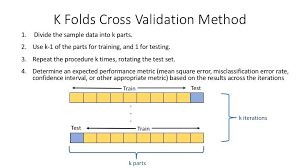
✨교차 검증 왜하는가? 그것의 정당성은?
- 기존의 hold-out 방식(train, validation 8:2분할)은 validation 하나에만 학습하기 때문에 과적합 우려가 큼
- 개선 방안으로 일반적으로 데이터 분할에 있어서 일반화의 성능을 향상시키기 위해 cross-validation 방식을 선택함
- 우리의 데이터는 구입 시간과 같은 시계열을 따르는 데이터와는 거리가 멀기 때문에 시계열 관련 데이터 분할은 진행하지 않았음
✨문제점은 없는가?
- Data Leakage는 해당 안된다고 볼 수 있음 (test dataset을 건드리지 않기 때문)
- 기존 코드에 있어서 바뀌는 부분이 크게 있진 않지만, 혼란을 야기할 수 있기 때문에 일반화된 코드로 정제해줄 필요가 있음
- 하나의 성능 향상을 위한 방안이기 때문에 현재 베이스라인의 코드보다 성능은 좋지만, 나중에 튜닝하거나 리소스가 많이 소모된다 판단되면 기존 hold-out 방식으로 진행하는 상황에 따라 유기적으로 사용해줘도 무방
- 현재 FM 모델에 대해서만 데이터 분할을 진행했는데, 다른 모델에 대해서도 일반화되게 바꿔주는 코드 작성 필요 (이 부분은 FM모델 처럼 kfold_train을 하나씩 생성해주면 되는 부분이라 크게 다르진 않을 것이라 판단됌
✨DL Model에서 K-fold 적용 실습
1. FM model class에 생성자 따로 생성
in class FactorizationMachineModel
# kfold에 사용될 새로 정의한
self.seed = args.SEED
self.trainx = data['train_X']
self.trainy = data['train_y']
self.batchsize = args.BATCH_SIZE2. kfold하기 위해서는 dataset과 dataloader를 따로 설정
Dataset 설정
def kfold_train(self):
# model: type, optimizer: torch.optim, train_dataloader: DataLoader, criterion: torch.nn, device: str, log_interval: int=100
wandb.init()
wandb.config.update({
"batch_size" : self.batchsize,
"epochs": self.epochs,
})
# kfold.split에 사용될 train_dataset
train_dataset = TensorDataset(torch.LongTensor(self.trainx.values), torch.LongTensor(self.trainy.values))
kfold = KFold(n_splits = 10, random_state = self.seed, shuffle = True)
Dataloader 설정
validation_loss = []
# fold.split 통해 train과 valid index 자동으로 fold가 5라면 4:1비율로 나눠줌
for fold, (train_idx, val_idx) in enumerate(kfold.split(train_dataset)):
train_subsampler = torch.utils.data.SubsetRandomSampler(train_idx)
val_subsampler = torch.utils.data.SubsetRandomSampler(val_idx)
trainloader = torch.utils.data.DataLoader(train_dataset, batch_size=self.batchsize, sampler=train_subsampler) # 해당하는 index 추출
valloader = torch.utils.data.DataLoader(train_dataset, batch_size=self.batchsize, sampler=val_subsampler)3.model predict에 사용될 testdataset은 dataload 모듈에 정의
def context_data_load(args):
test_dataset = TensorDataset(torch.LongTensor(context_test.drop(['rating'], axis=1).values))
test_dataloader = DataLoader(test_dataset, batch_size=args.BATCH_SIZE, shuffle=False)✨교차 검증의 효능을 극대화 시키려면?
- 하이퍼 파라미터 최적화에 있어서 교차 검증을 사용할 수 있음. Optuna

장난감이 데이터인 사람