컴퓨터 구조
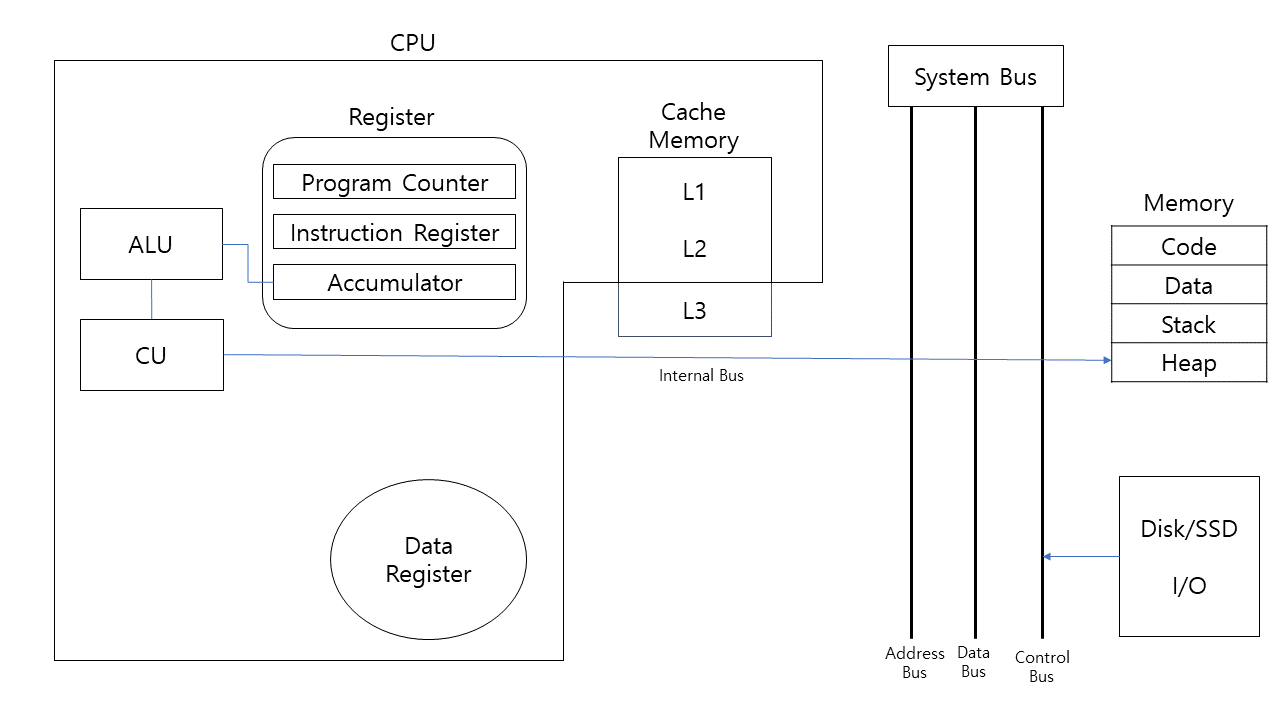
컴퓨터는 크게 4가지 구조로 이루어져 있다.
- CPU: 컴퓨터의 두뇌로, 명령어를 읽고 해석하여 실행해준다.
- Memory: CPU와 직접 데이터를 주고받을 수 있는 기억장치
- Disk/SSD
- I/O device
CPU의 구조
- ALU(Arithmetic Logic Unit): 산술, 논리 연산을 담당하는 장치
- CU(Control Unit): 명령어를 해석하고 CPU를 제어하는 장치
- Register: 임시로 데이터를 저장하는 기억장치
- Cache Memory: Memory의 일종으로 L1과 L2는 CPU내에 들어가있으며, 최신 CPU칩에는 L3도 포함되어있다.
Register
- Program Counter: CPU가 처리할 다음 명령어 주소를 가져와준다.
- Instruction Register: Memory에서 가져온 명령어(Program Counter가 전달해준)를 저장해준다.
- Accumulator: ALU가 처리해준 값을 저장해준다.
Cache Memory
CPU의 속도는 Memory보다 상대적으로 빠르기 때문에 그 속도 차이를 해결하기 위해 Cache Memory가 사용된다.
Memory에서 자주 사용되어지는 것들이 Cache Memory에 올라가기도 한다.
L1은 작고 빠르며, L2, L3로 갈수록 크기도 커지고 속도도 느려진다.
- Hit Ratio = hit / (hit + miss): CPU가 Memory에 접근하기 전에 먼저 Cache Memory를 확인하는데, 그 때 필요한 Data가 있으면 hit, 없으면 miss로 계산되며, 이를 높이기 위해 시간, 공간지역성을 기준으로 Data를 Cache Memory에 올려준다.
- 시간지역성: 최근에 사용된 Data가 다시 사용될 가능성이 높다.
- 공간지역성: 최근에 사용된 Data근처의 Data가 사용될 가능성이 높다.
Memory의 구조
- Code 영역: 실행할 프로그램의 코드가 저장되는 영역으로 OS, 시스템 소프트웨어 관련 코드도 들어가있다.
- Data 영역: 프로그램의 static변수나 전역 변수가 저장되는 영역으로 프로그램의 시작과 함께 할당되며, 프로그램이 종료되면 사라진다.
- Stack 영역: 지역변수와 함수의 매개변수가 저장되는 영역으로 컴파일때 크기가 결정된다.
- Heap 영역: 크기가 크거나, 동적할당이 일어나는 변수들이 저장되어지는 곳으로 런타임때 크기가 결정된다.
System Bus
시스템 버스는 Memory와 CPU, I/O device사이의 데이터를 주고받기위해 사용되는 통로이다.
- Address Bus: CPU가 Memory와 I/O device로 데이터의 주소를 보낼때 사용되는 Bus로 단방향 버스라도고 한다
- Data Bus: CPU에서 Memory나 I/O device로 데이터값을 주고받을 때 사용하는 Bus로, 데이터를 주고받기 때문에 양방향이다.
- Control Bus: Data Bus와 Address Bus를 제어하기 위한 신호(Read, Write)를 보내는 Bus로 양방향이다.
Process
일반적으로 컴퓨터에서 실행중인 프로그램을 의미한다.
- foreground process: 사용자가 볼 수 있는 공간에서 실행되는 프로세스
- background process: 사용자가 볼 수 없는 공간에서 실행되는 프로세스
보통 하나의 CPU는 한번에 한 개의 프로그램만을 실행시킬 수 있다.
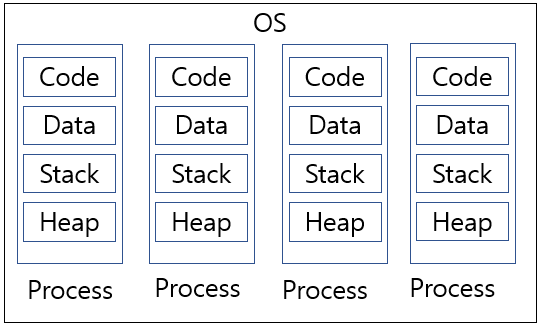
각각의 프로세스는 각자 별개의 메모리 공간을 사용한다.
Thread
어떠한 프로그램 내에서 실행되는 흐름의 단위를 의미한다.
모든 프로세스는 적어도 한 개의 스레드를 가지며, 두 개 이상의 스레드를 가지는 프로세스를 멀티 프로세스라고 한다.
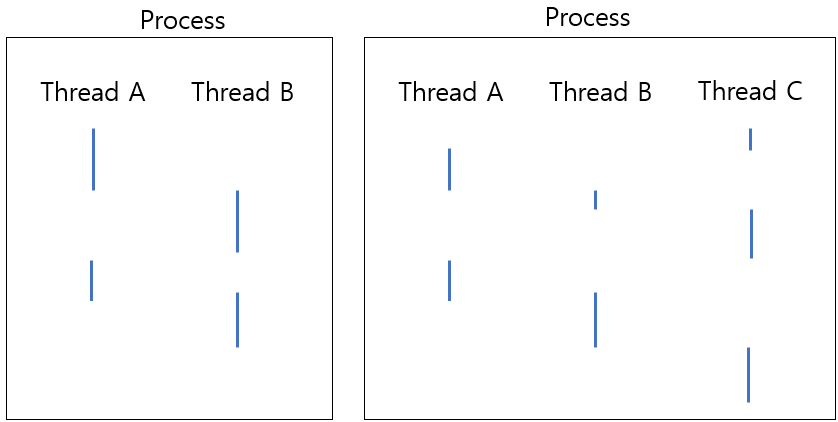
각각의 스레드는 동시에 실행되는 것이 아니라 한 스레드를 실행시키다 잠시 정지시켜놓고 다른 스레드를 실행시키는 방식으로 동작한다.
CPU는 한개의 프로그램만 실행시킬 수 있기 때문에 Thread를 통해 여러 프로그램을 동시에 실행되는 것 처럼 만들 수 있다.
이런식으로 작업들을 번갈아가며 진행시키는 것을 Context Switching이라 한다.
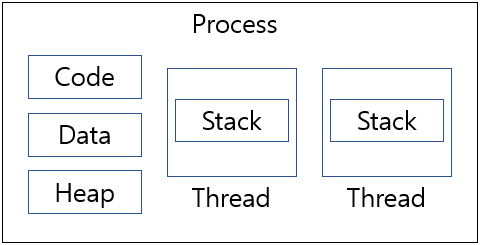
한 프로세스 내에서 각각의 스레드는 Code, Data, Heap영역은 공유하며, 각 스레드마다 Stack영역만 할당받는다.
Compiler
컴파일러는 어떤 프로그래밍 언어로 쓰여진 것을 다른 프로그래밍 언어로 옮겨주는 프로그램을 의미하며, 보통 high-level language를 low-level language로 바꾸어서 컴퓨터가 실제로 이해할 수 있는 코드로 변환시킨다.
여기서는 javasciript를 기준으로 설명하며, 각 언어마다 차이가 있을 수 있다.
- Lexical Analyzer: 어휘적 분석 단계로 구문을 위에서부터 읽어내려오며 한글자씩 Tokenizer를 수행하면서 lexer에게 넘겨주면 lexer가 의미있는 토큰인지 확인 후, Symbol로 등록한다.
- Syntax Analyzer(Parser): AST(Abstract Syntax Tree)를 생성하며, TypeScript는 type까지 포함시킨 Annotated AST를 생성한다.
- Intermediate Code Generator: 파싱의 결과로 생성된 AST가 Interpreter가 실행할 수 있는 intermediate code(byte code)로 변환된다. 이 단계에서 Type checking이 일어나며, 대부분의 메모리 주소가 결정된다.
- Code Optimizer: 사용되지 않는 코드들을 Tree Shaking해주고 Scheduling해준다. 호이스팅은 이 단계에서 시행되며, linking이 일어난다.
- Target Code Generator
Linking: 한 파일에서 다른 파일을 사용할 때 각각 따로 컴파일되기 때문에 서로 다른 파일을 묶는 과정이 필요한데, 이를 링킹이라고 한다.
