RAG
- 생성형 AI는 방대한 자료를 학습한 LLM의 발전에 힘입어 text response를 만드는데 탁월한 성능을 보이고 있다. 이의 장점은 LLM에서 생성된 텍스트는 읽기 쉽고 우리가 프롬프트라고 부르는 질문에 대해 광범위하게 적용할 수 있는 상세한 응답을 제공한다.
- 하지만 단점으로 response를 생성하는데 사용되는 정보는 AI를 학습하는데 사용한 정보에만 제한되어 있다는 것이다. LLM을 학습하는데 쓰인 데이터는 시간이 지날수록 예전의 정보가 되고, 새롭게 만들어지는 특정 정보 예를 들어 한 단체의 제품이나 서비스에 대한 정보 같은 것들을 포함하지 않을 것이다.
- 따라서 부정확한 정보를 내놓을 수 있고 이는 서비스적 측면에서 치명적인 단점이다. 이를 해결하기 위해 나온 방법론 중 하나가 RAG이다.
RAG: Retrieval-Augmented Generation
- RAG란 LLM의 knowledge를 augment하기 위해 추가적으로 private하거나 real-time의 데이터를 사용하는 기법이다.
- 보통 Indexing 과 Retrieval and Generation의 두 과정으로 나뉜다.
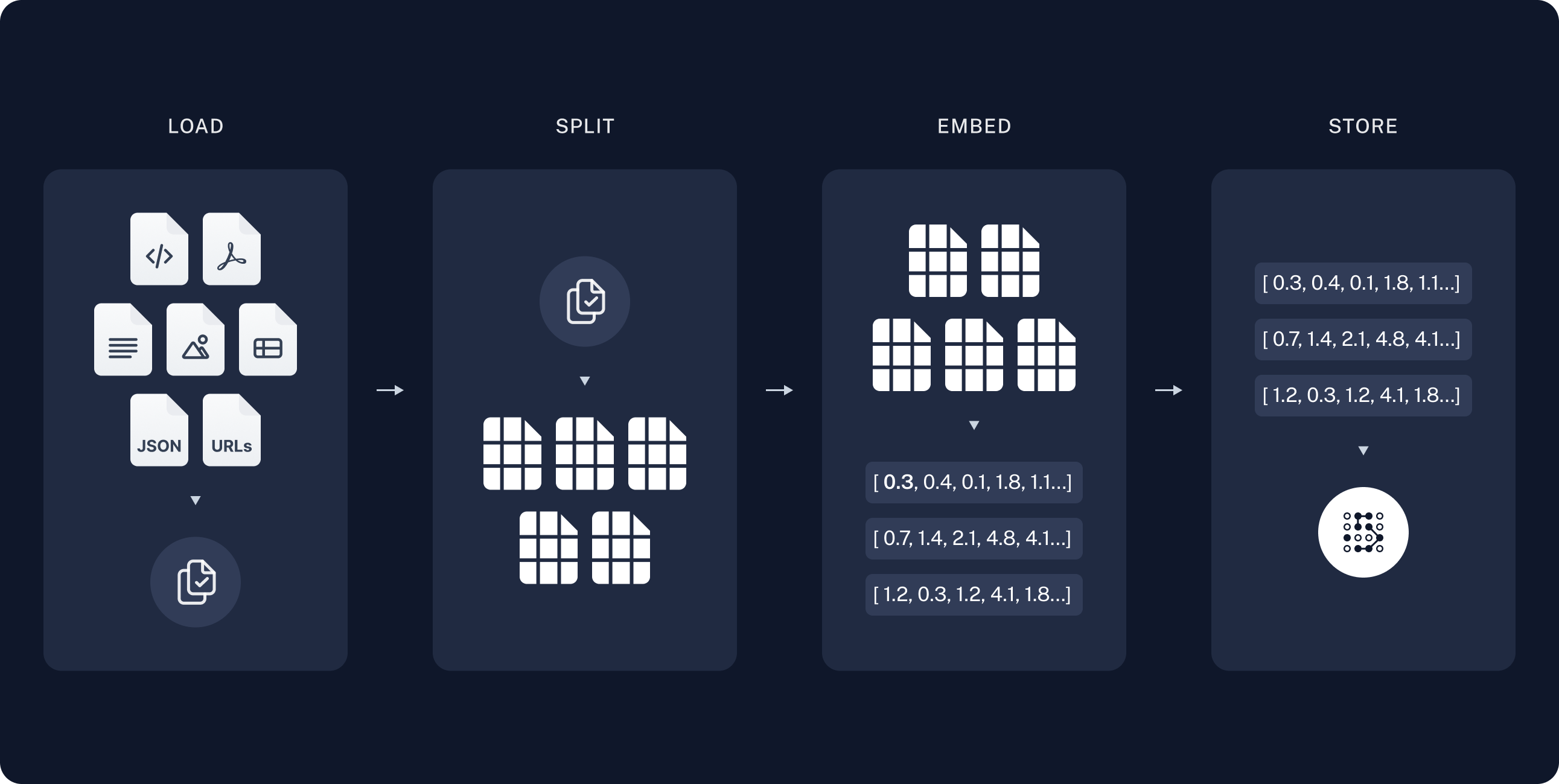
- Indexing: 소스로부터 데이터를 모아 인덱싱하는 파이프라인.
- Load - Split - Embed - Store
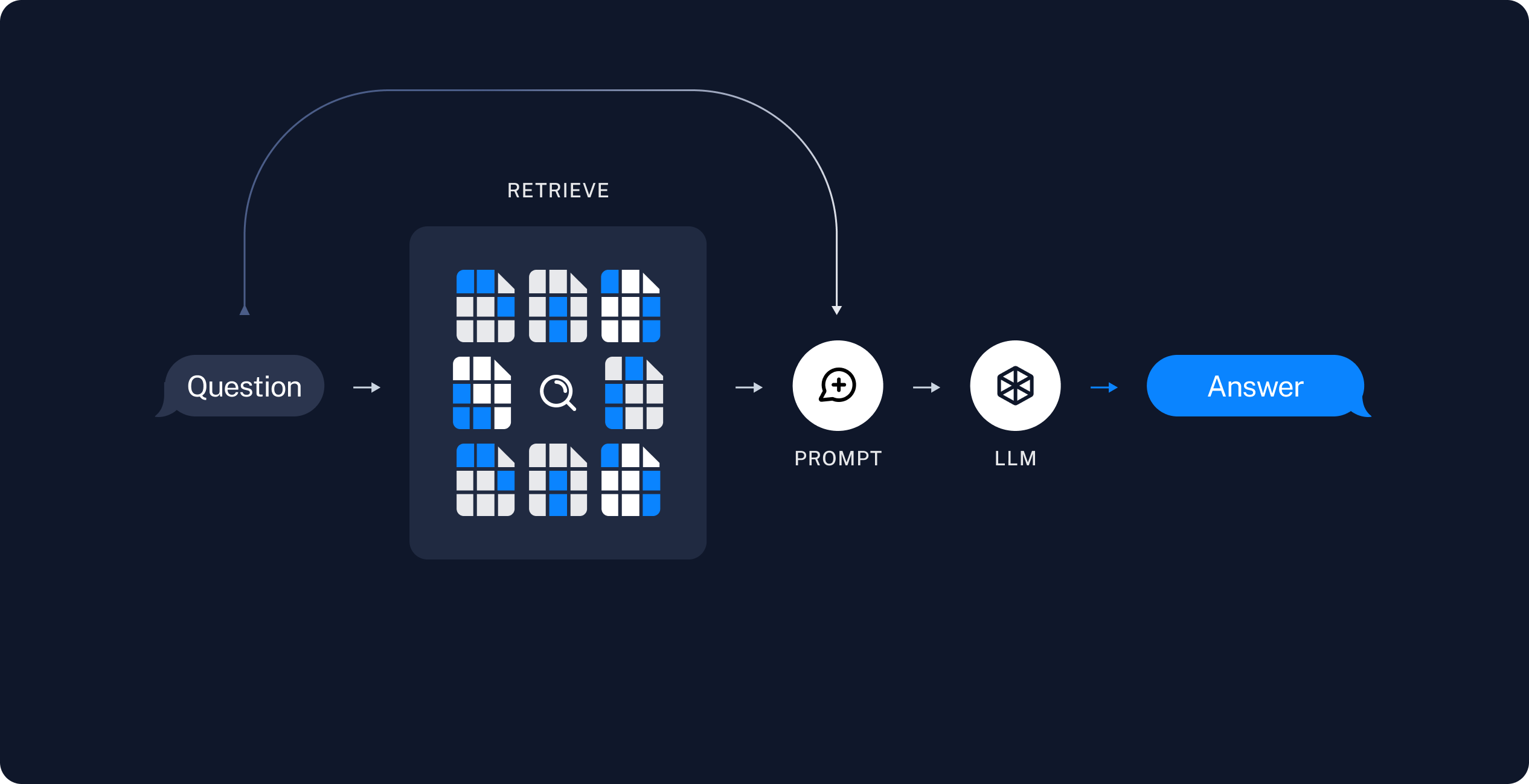
- Retrieval: 기존 정보 검색 시스템을 사용하여 target information에 대한 문서 또는 정보를 검색한다.
- Generator: Retriever가 검색한 정보를 바탕으로 의미있는 문장 또는 문단을 생성한다.
- RAG는 LLM의 기본 모델 자체를 수정하지 않고도 targeted information에 좀더 맞는 output에 대해 최적화할수 있는 방법을 제공한다. 이때 target information은 LLM보다 최신 정보일 뿐만 아니라 특정 단체나 산업에 특정할 수 있다. 이는 프롬프트에 대한 response로 좀더 contextual하게 적절한 응답을 제공할 수 있을 뿐만 아니라 해당 답변을 완전히 최신 데이터에서 기반할 수 있게 한다.
- 논문: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Retrieval의 성능을 높히기 위해 Re-Ranking, Filtering등이 추가되어 사용된다.
장점
- RAG 과정은 LLM 모델을 학습하는데 쓰인 데이터보다 최근 데이터를 포함한다.
- 최신 정보를 새로 학습하는것 보다 RAG에 쓰일 데이터 저장소를 업데이트 하는것이 훨씬 비용이 적게 든다.
- RAG에 사용되는 vector database에 있는 정보들은 데이터 소스가 분명하다. 이는 틀린 정보를 내놓을 때 RAG의 데이터를 수정하거나 삭제하여 처리하는 것을 가능하게 한다.
Challenges
- RAG과정과 이를 사용하도록 라우팅하는 과정이 들어가기 때문에 LLM자체만 사용하는것보다 비용이 증가한다.
- Knowledge library및 Vector database 내의 정형 및 비정형 데이터를 최적으로 모델링하는 방법을 결정해야 한다.
- RAG 시스템에 데이터를 점진적으로 공급하는 프로세스에 대한 요구사항 개발이 필요하다.
- Inaccuracy에 대한 reports처리가 필요하고 해당 정보 소스를 수정 또는 삭제하기 위한 프로세스를 마련해야 한다.
Reference

라이브데이터 Developer