
1. 데이터 전처리
1-1 데이터 분석 절차
-
수집된 데이터를 분석에 적합한 데이터로 전처리하는 과정이 필요합니다.
-
데이터 전처리는 가장 많은 시간이 소요되는 작업인것과 동시에 중요한 작업입니다.
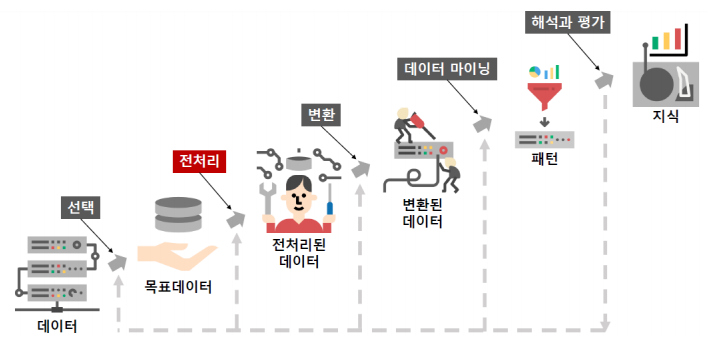
1-2 데이터 전처리 방법
-
Data Integration : 여러 source의 데이터를 하나의 데이터로 통합하는 방법
- 다른 source의 데이터가 서로 호환이 되도록 결합
- 같은 단위, 같은 양식으로 데이터 결합

-
Data Cleaning : 데이터에 존재하는 여러 문제점을 교정하는 방법
- 낮은 품질의 데이터를 활용할 수 있도록 하는 과정
- 중복값 제거, 결측치 처리, 값의 불일치 제거, 이상치 처리 등..

-
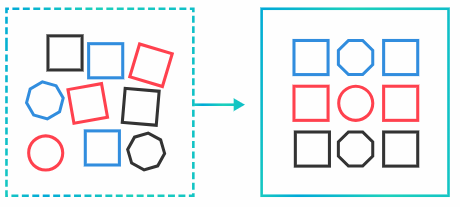
Data Transformation : 정규화, 이산화 등의 방법으로 데이터를 변환하는 방법
- 데이터의 형식이나 구조를 다르게 변환
- 원본 데이터의 특징, 사용하는 모델 등에 따라 변환하는 방식이 다르다.
- Task : 정규화(Normalization), 이산화(Discretization), 로그 변환(Log Transformation) 등
-
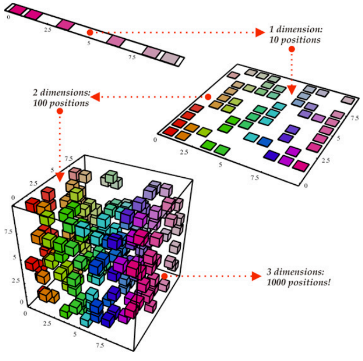
Data Reduction : 샘플링, 차원 축소(Dimension Reduction) 등의 기법으로 데이터 크기를 축소하는 방법
- 데이터의 크기가 매우 큰 경우, 복잡한 모델링을 하기 어렵습니다.
: 딥러닝을 사용하기 적합하지 않다고 알려진 정형 데이터에 대해서 특히 더 까다롭습니다. - 원래보다 작은 크기로 데이터로 표현해도 raw data의 완결성을 유지하는 것이 중요합니다.
- Task : 차원축소(Dimensionality Reduction), 수치적 축소(Numerosity Reduction) 등
- 데이터의 크기가 매우 큰 경우, 복잡한 모델링을 하기 어렵습니다.
2. 데이터 품질
2-1 데이터 품질에 영향을 끼치는 인자
-
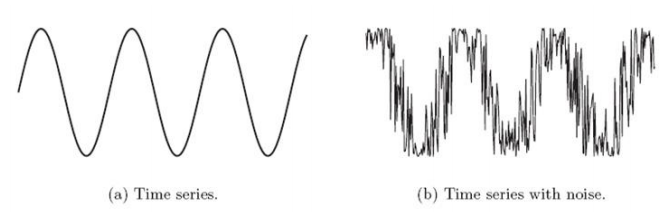
Noise
- 데이터 측정시 무작위로 발생 → 측정값에 오류를 발생시킨다.
- 임의로 발생하는 예측하기 어려운 요인
→ Noise가 크면 해당 데이터는 제거해야 함
-
Artifact
- 어떤한 요인으로 인해 반복적으로 발생하는 왜곡이나 오류를 의미
-
Precision
- 동일한 결과물을 반복적으로 측정하였을 때, 각 측정값 사이의 연관성
- 동일한 결과물을 반복적으로 측정하였을 때, 각 측정값 사이의 연관성
-
Bias
- 예측한 결과가 정답과 일정하게 차이가 나는 정도를 의미
-
Outlier
(Outlier는 분석 목적에 따라 취급이 다릅니다.)-
대부분의 데이터와 다른 특성을 보이거나, 특정 속성의 값이 유별난 데이터를 의미
-
Outlier Detection : Outlier 자체를 탐지하는게 목표 → Anomaly Detection 이라고도 함.
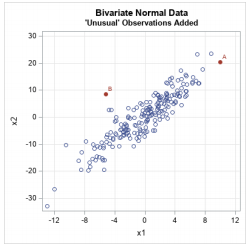
-
-
Inconsistent Value
(해당 부분을 주의해야 합니다 ㅎㅎ 👍)- ex) 여러 source 데이터를 통합시 키 속성의 형식이 맞지 않아 통합이 되지 않는 경우.
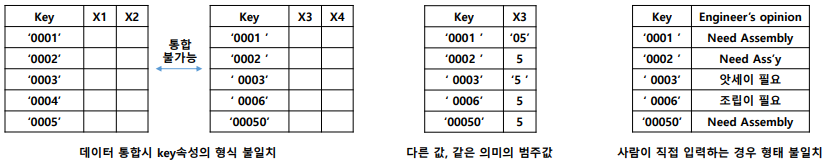
-
Duplicate
- 데이터의 중복은 언제든 발생 가능. 문제는 값의 차이가 발생할 수 있음
- 모든 속성 값이 동일 → 하나의 데이터를 제거
- 값에 차이가 존재 → 하나의 데이터로 통합하거나, 중복 제거에 대한 별도의 논의가 필요함

감사합니당. 😄👍

please bbbbbbbbb 😂
오오! 이상치가 분석 목적에 따라 달라질 수 있다는 걸 이번에 처음 알았네요! 좋은 정보 감사합니당 😆