이번 시간에는 직접 DAG를 작성하며, 배울 점들을 배워보자!
DAG 구성
만들어볼 DAG는 아래 5가지 Task와 모두 다른 Operator로 구성할 예정이다.
1. SQLite Table을 생성 : SQliteOperator
2. API가 Available한 상태인지 확인 : HttpSensor
3. API에서 Data를 가져옴 : SimpleHttpOperator
4. Data 중 필요한 데이터를 추출 : PythonOperator
5. 추출한 데이터를 앞에서 생성한 테이블에 삽입 : BashOperator
위와 같이 5개의 Task로 실습을 진행해 볼 예정이며, 4번 Task에서는 xcom을 이용하여
앞선 operator에서의 결과 값을 가져와볼 예정이다.
DAG 생성에 앞서..
airflow가 설치된 디렉토리에 dags 디렉토리를 생성해주고, 원하는 이름으로
dag.py파일을 생성해준다.
생성한 파일에서 우리의 첫 DAG를 생성해보자.
skeleton code
아래는 기본적인 DAG의 스켈레톤 파일이다
from airflow.models import DAG
from datetime import datetime
with DAG('user_processing', schedule_interval='@weekly',
start_date=datetime(2022, 1, 6), catchup=False) as dag:
# Task과 Operator 정의핵심은 DAG의 instantiate이다. (참고: Airflow 공식 Document)
dag_id, schedule_interval, start_date, catchup 이 파라미터로 전달된다.
이 중 dag_id는 airflow 서버 내에서 유일해야 함에 유의하자.
catchup에 대해서는 추후에 다시 설명하기로 하자.
default_args
앞으로 DAG 내에서 동일하게 계속 사용될 애트리뷰트는 default_args로 분리하여두면 코드를 조금 더 깔끔하게 관리할 수 있다.
예를 들어, task의 재실행 횟수 같은 경우 보편적으로 한 개의 DAG 내에서는 모든 Task에 동일하게 적용되기 때문에, default_args로 분리하여 두면 편하다.
default_args를 쓰는 것이 사실상 표준(de facto standard)이다.
from airflow.models import DAG
from datetime import datetime
default_args = {
'start_date': datetime(2022, 1, 6)
}
with DAG('user_processing', schedule_interval='@weekly', default_args=default_args, catchup=False) as dag:
# Task과 Operator 정의나의 경우 start_date를 default_args로 지정했다.
😭 주의사항!
Airflow에서는 하나의 Operator에 하나의 Task만을 할당해야한다.
예를 들어, PythonOperator 하나를 이용해
1. Data Cleaning
2. Processing Data
를 동시에 하도록 코드를 작성했다고 가정해보자.
만약, 1번 작업이 마무리되고, 2번 작업이 에러를 발생시켜 종료가 되었다고 쳐보자.
Airflow는 아마 전체 PythonOperator를 재실행하려 할 것이다.
그렇게되면 불필요한 1번 작업이 반복되어 재실행되는 문제가 발생한다.
또한 디버깅을 하기에도 어려워진다.
따라서 1 Operator => 1 Task 원칙을 지키는 것이 좋은 DAG를 작성하는 방법이다.
Operator의 종류
진행하기에 앞서 Operator의 종류에 대해 알아보자.
Operator에는 크게 3종류의 Operator가 존재한다
Action Operator
Task를 Action으로 수행하는 Action operator
Transfer Operator
데이터를 source에서 destination으로 전송해주는 Transfer operator
Sensors
특정 조건에 일치할때 까지 기다렸다가, 만족되면 이후 과정을 진행하도록 기다려는 Sensor
DAG Build Up!
테이블 생성하기
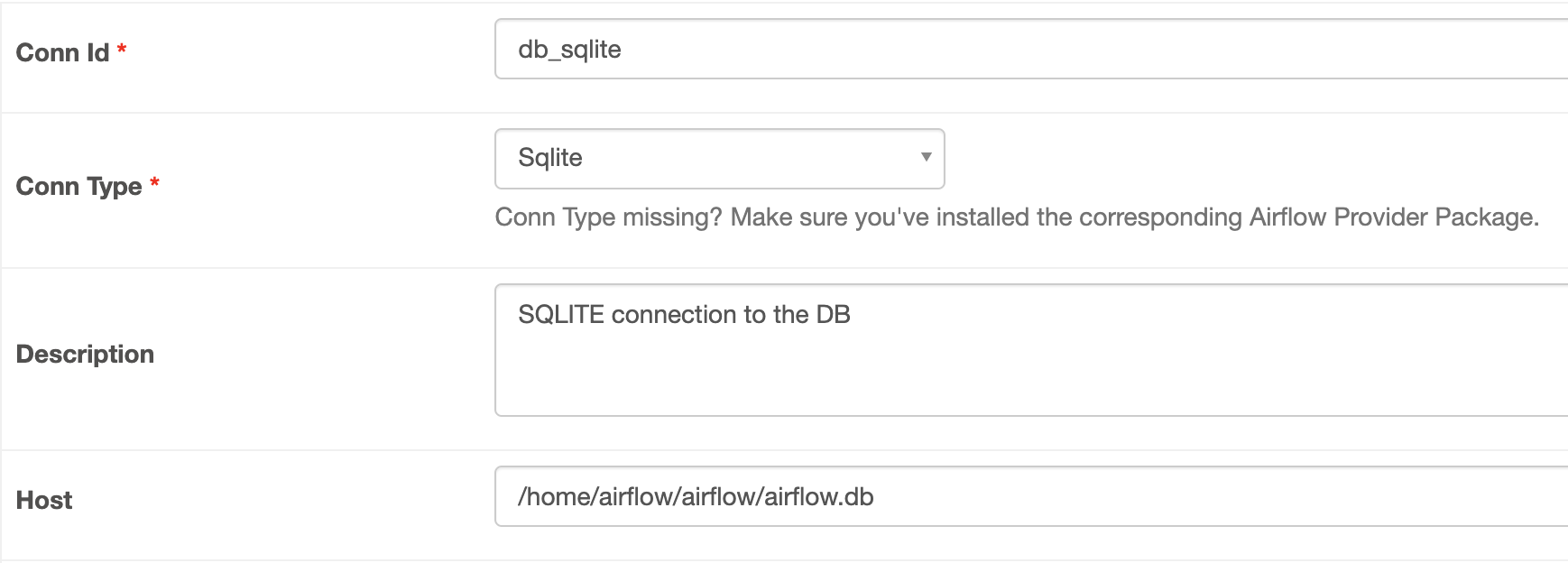
우선 우리는 SQLite DB를 이용할 것이기 때문에, SqliteOperator를 import 해준다.
from airflow.providers.sqlite.operators.sqlite import SqliteOperator그리고 아래와 같이 코드를 작성한다
creating_table = SqliteOperator(
task_id='creating_table',
sqlite_conn_id='db_sqlite',
sql='''
CREATE TABLE IF NOT EXISTS users (
firstname TEXT NOT NULL,
lastname TEXT NOT NULL,
country TEXT NOT NULL,
username TEXT NOT NULL,
password TEXT NOT NULL,
email TEXT NOT NULL PRIMARY KEY
);
'''
)dag_id와 마찬가지로 task_id는 DAG내에서 유일해야 한다.
sqlite_conn_id는 아래 이미지를 참고하여, connection을 웹 UI에서 생성해준다.
각 단계를 마친 후에는
$ airflow tasks test {dag_id} {task_id} {execution_date}
$ airflow tasks test user_processing creating_table 2022-01-01로 테스트하여 준다.
API 상태 확인하기
여기에서는 공개된 API의 상태를 HttpSensor를 이용해서 확인할 것이다.
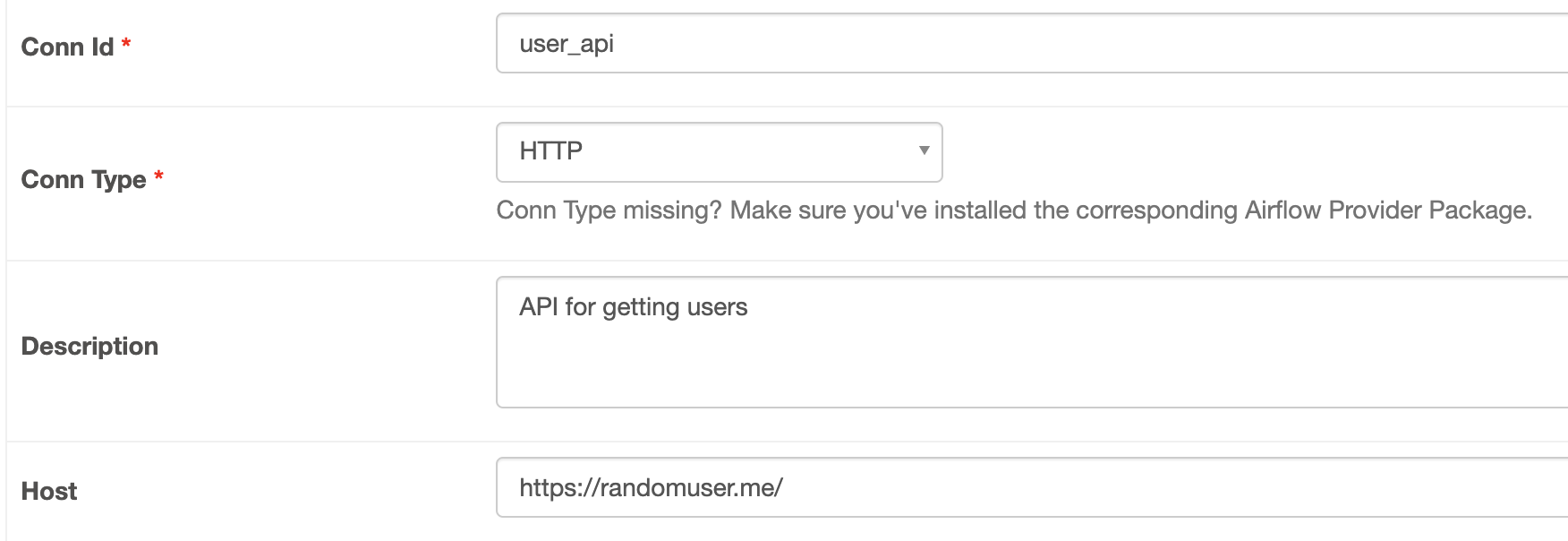
from airflow.providers.http.sensors.http import HttpSensor위 import 문을 추가하고, 아래의 코드도 입력해준다
is_api_available = HttpSensor(
task_id='is_api_available',
http_conn_id='user_api',
endpoint='api/'
)위의 SqliteOperator와 동일하게 아래와 같이 HTTP 커넥션을 추가해준다.
우리가 사용할 API는 randomuser.me/api 이다.
이 역시 완료 후
$ airflow tasks test {dag_id} {task_id} {execution_date}
$ airflow tasks test user_processing is_api_available 2022-01-01로 테스트하면 아래와 같은 결과가 나온다.

간혹 서버 상태에 따라, fail이 나올 때도 있지만, 몇차례 시도해보면 정상적으로 실행됨을 확인할 수 있다.
API 유저 정보 가져오기
여기에선 SimpleHttpOperator를 이용해서, API 서버에서 정보를 Load 해온다.
from airflow.providers.http.operators.http import SimpleHttpOperator
import json위와 같이 SimpleHttpOperator를 import 준 후, 아래와 같이 작성해준다.
extracting_user = SimpleHttpOperator(
task_id='extracting_user',
http_conn_id='user_api',
endpoint='api/',
method='GET',
response_filter=lambda response: json.loads(response.text),
log_response=True
)위에서 생성한 user_api 커넥션을 이용해서, API를 호출하고, 그 리스폰스 값을 람다함수를 이용하여 저장한다.
유저 정보 가공하기
이 단계에선 PythonOperator를 이용하여, 이전 task에서 저장한 데이터를 파일로 저장할 것이다.
from airflow.operators.python_operator import PythonOperator
from pandas import json_normalize # PythonOperator
processing_user = PythonOperator(
task_id='processing_user',
python_callable=_processing_user
)
# Python 호출 함수
def _processing_user(ti):
# xcom을 이용해서, 이전 태스크가 저장한 값을 불러옴
users = ti.xcom_pull(task_ids=['extracting_user'])
if not len(users) or 'results' not in users[0]:
raise ValueError('User is empty')
user = users[0]['results'][0]
processed_user = json_normalize({
'firstname': user['name']['first'],
'lastname': user['name']['last'],
'country': user['location']['country'],
'username': user['login']['username'],
'password': user['login']['password'],
'email': user['email']
})
# 파일로 저장
processed_user.to_csv('/tmp/processed_user.csv', index=None, header=False)이 단계가 끝나면 호출된 API에서 원하는 데이터만 /tmp/processed_user.csv 파일에 저장된다.
유저 정보 저장하기
이 정보를 다시 SQLite user 테이블에 저장해보자
from airflow.operators.bash import BashOperatorstoring_user = BashOperator(
task_id='storing_user',
bash_command='echo -e ".separator ","\n.import /tmp/processed_user.csv users" | sqlite3 /home/airflow/airflow/airflow.db'
)위 bash command는 /tmp/processed_user.csv 파일의 내용을 "," 단위로 분리하여, sqlite3 명령어로 전달하여 insert하도록 하는 명령이다.
여기까지 하면, 모든 태스크 작성이 완료됬다!
태스크 디펜던시
마지막으로 각 태스크 간의 디펜던시를 주기 위해 아래와 같이 작성한다.
creating_table >> is_api_available >> extracting_user >> processing_user >> storing_user이제 코드 작업은 전부 끝났다.
작성한 코드를 웹 UI에서 실행시켜보면, 정상적으로 작동할 것이다.
DAG 스케줄링
DAG는 코드에 입력된 start_date와 schedule_interval을 기준으로 첫 트리거 시간을 결정한다.
첫 트리거 시간은 start_date + schedule_interval 시간이다.
start_date에 단순히 실행되는 것이 아니다.
이 점은 반드시 기억해야한다.
자세한 내용은 링크를 참고하자.
Backfiling & Catchup
catchup
앞서 DAG를 생성할 때 나왔던 파라미터이다.
catchup은 DAG가 어떤 이유에서든지, 실행되었어야할 dagrun이 실행되지 못하고 밀려있다면, 밀려있는 dagrun을 수행하도록 하는 기능이다.
예를 들어, start_date가 2022-01-01이고 schedule_interval이 daily라고 가정하자.
첫 날이 끝날때(자정)에 첫번째 dagrun이 수행될 것이다.
둘쨋날에 DAG를 Pause 시켰다가 5번째 날 다시 resume 시킨 순간, 마지막 수행시점 이후로 수행하지 못했던 2-4일간의 3번의 dagrun이 수행되는 옵션이다.
catchup은 airflow에서 default로 true로 설정되어 있는 옵션이다.
이렇게 과거의 데이터를 채워넣는 액션을 backfilling 이라고 한다.
그리고 Airflow의 모든 정보는 UTC 기준임을 명심하자

전체 dag파일 볼 수 있을까요?