
What is Executor?
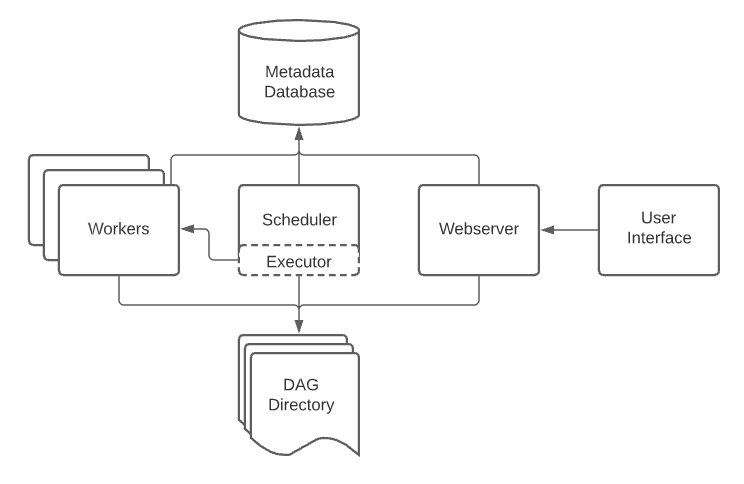
공식문서에서 명시적으로 설명하는 컴포넌트는 아래 5개이다.
- scheduler
- which handles both triggering scheduled workflows, and submitting Tasks to the executor to run.
- executor 👈
- which handles running tasks. In the default Airflow installation, this runs everything inside the scheduler, but most production-suitable executors actually push task execution out to workers.
- webserver
- which presents a handy user interface to inspect, trigger and debug the behaviour of DAGs and tasks.
- folder of DAG files
- read by the scheduler and executor (and any workers the executor has)
- metadata database
- used by the scheduler, executor and webserver to store state.
여기서는 executor 컴포넌트에 초점을 맞춰서 알아보고자 한다.
Executor는 Task instance를 실행하는 주체로, executor의 종류에 따라 worker들의 동작방식이 달라진다.
executor는 공통 API 를 가지고 있고 “pluggable” 하다. 즉, executor를 교체할 수 있으며, 한번에 오직 하나의 executor만 구성할 수 있다. (airflow.cfg파일에서 [core] 에 있는 executor option 에서 설정된다.)
Executor types
- SequentialExecutor: 단일 프로세스에서 하나씩 작업을 순차적으로 실행합니다. (airflow 설치 시, default)
- LocalExecutor: 머신에서 사용 가능한 코어 수에 따라 별도의 프로세스로 동일한 머신에서 작업을 병렬로 실행합니다.
- CeleryExecutor: Celery distributed task queue를 사용하여 여러 작업자 컴퓨터에서 병렬로 작업을 실행합니다.
- DaskExecutor: Python용 분산 컴퓨팅 라이브러리인 Dask를 사용하여 작업을 병렬로 실행합니다.
- KubernetesExecutor: Kubernetes pods를 사용하여 작업을 실행하여 Kubernetes 클러스터에서 작업을 실행합니다.
LocalExecutor
LocalExecutor는 Airflow가 작업을 로컬 컴퓨터에서 실행하는 방법입니다.
장점
- 구성이 쉽고 간단합니다.
- 로컬 컴퓨터에서 작업을 처리하므로, 작업 처리 속도가 빠릅니다.
- 작업 처리에 필요한 외부 의존성이 적어, 실행 환경이 단순합니다.
- 로컬 컴퓨터에서 실행되기 때문에 로그와 디버깅이 쉽습니다.
단점
- 단일 노드에서 실행되기 때문에, 병렬 처리 작업에 제한이 있습니다.
- 성능 제한이 있으므로 대규모 작업 처리에는 적합하지 않습니다.
- 로컬 컴퓨터의 하드웨어 자원(코어, 메모리 등)이 제한적이기 때문에, 일부 작업에 대한 처리 속도가 느릴 수 있습니다.
LocalExecutor는 단일 시스템에서 테스트 및 개발에 유용하지만 위에 언급한 단점 때문에 production workflow에서는 주로 CeleryExecutor 혹은 KubernetesExecutor를 주로 사용합니다.
CeleryExecutor
CeleryExecutor는 Airflow가 작업을 Celery라는 분산 작업 큐 시스템을 이용해 실행하는 방법입니다.
Cloud 환경에서 Airflow를 사용할 때는 일반적으로 CeleryExecutor를 사용하는 것이 더 흔합니다. Cloud 환경에서는 대부분의 경우에 분산 컴퓨팅 리소스가 필요하고, CeleryExecutor는 분산 작업 큐 시스템을 기반으로 하기 때문에, 다수의 worker를 사용하여 작업을 병렬로 처리할 수 있습니다.
장점
- 분산 작업 큐 시스템을 기반으로 하기 때문에, 대규모 작업 처리에 용이합니다.
- 분산된 worker 노드를 사용하기 때문에 작업 병렬 처리가 용이합니다.
- 작업 처리량이 높고 작업 처리 속도가 빠릅니다.
- 확장성이 높아, 리소스의 확장이 쉽고 유연합니다.
단점
- 설정과 운영이 복잡합니다.
- 추가적인 인프라 리소스가 필요합니다.
- 작업 처리 과정에서 의존성을 파악하는 것이 어려울 수 있습니다.
Architecture
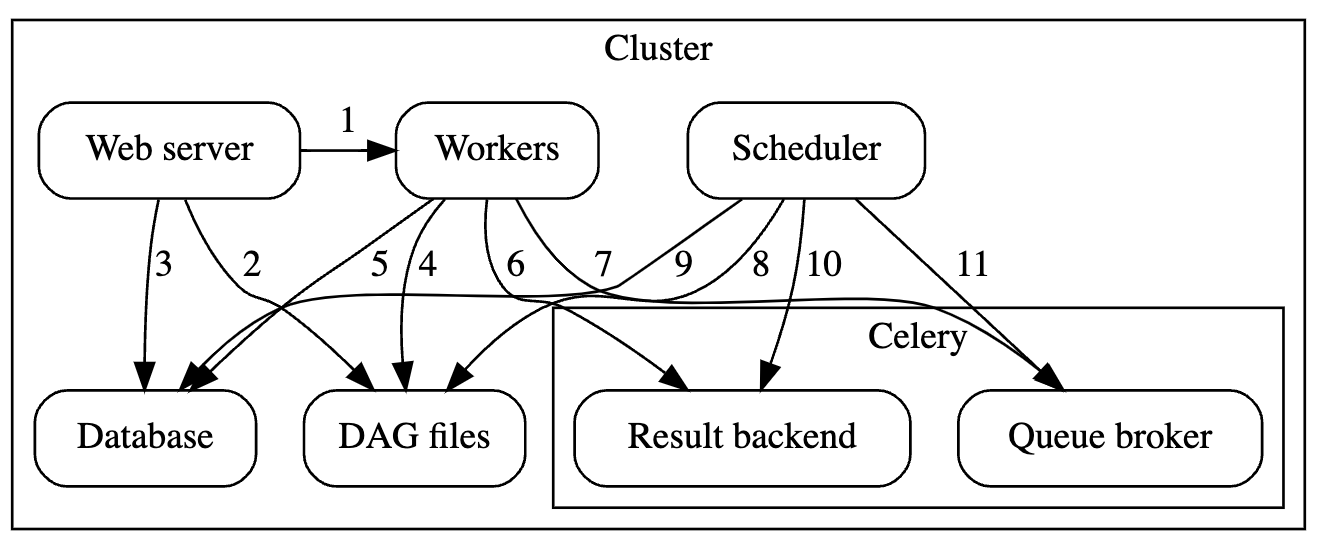
Airflow consist of several components:
- Workers - 할당된 task를 실행합니다.
- Scheduler - 필요한 task를 queue에 추가하는 일을 담당합니다.
- Web server - HTTP 서버는 DAG/작업 상태 정보에 대한 액세스를 제공합니다.
- Database - tasks, DAGs, Variables, connections 등의 상태에 대한 정보를 포함합니다.
- Celery - Queue mechanism
Celery의 대기열은 두 가지 구성 요소로 구성되어 있습니다.
Broker
Celery에서 Message Broker는 작업을 처리하기 위해 각각의 worker 노드에서 사용 가능한 작업들의 대기열을 관리하는 메시지 중개자(Message Broker)로서의 역할을 합니다. Celery Executor는 분산 작업 처리를 위해 Message Broker를 사용합니다.
Message Broker는 작업을 수신하여 대기열에 추가하고, 각각의 worker 노드에서 대기열에서 작업을 가져와 처리할 수 있도록 전달합니다. 이를 통해 Celery Executor는 분산된 작업 처리를 효율적으로 수행할 수 있습니다.
Celery에서 지원하는 Message Broker는 여러 가지가 있지만, 가장 많이 사용되는 것은 다음과 같습니다.
-
RabbitMQ
RabbitMQ는 AMQP(Advanced Message Queuing Protocol)를 사용하는 메시지 브로커로, 분산된 시스템에서의 데이터 전송에 사용됩니다. Celery에서 RabbitMQ를 Message Broker로 사용하면, 작업 처리 상태를 추적하고 작업에 대한 결과를 저장하는 데 사용할 수 있는 다양한 기능을 제공합니다. -
Redis
Redis는 인 메모리 데이터 저장소로, Celery에서도 Message Broker로 사용됩니다. Redis는 빠른 속도와 확장성을 제공하며, Celery Executor에서 사용할 수 있는 다양한 메시지 처리 기능을 제공합니다. -
Apache Kafka
Apache Kafka는 분산 스트리밍 플랫폼으로, 메시지 브로커로 사용됩니다. Celery에서 Apache Kafka를 Message Broker로 사용하면, 높은 처리량과 실시간 데이터 처리를 위한 기능을 제공합니다.
위와 같이 Celery에서 사용 가능한 Message Broker는 여러 가지가 있습니다. 각각의 Message Broker는 서로 다른 특성을 가지고 있으므로, 프로젝트의 성격과 작업량, 환경 등을 고려하여 적절한 Message Broker를 선택하는 것이 중요합니다.
Result Backend
Celery에서 Result Backend는 Celery Executor에서 작업 처리 상태를 저장하고 추적하는 데 사용되는 저장소입니다. 작업 처리 상태를 저장하고 추적하는 이유는, 분산 작업 처리를 위해 사용되는 worker 노드들이 서로 다른 컴퓨터에서 실행될 수 있기 때문입니다.
Celery Backend는 여러 가지 유형이 있으며, 그 중에서 가장 많이 사용되는 세 가지 유형은 다음과 같습니다.
-
RabbitMQ Backend
RabbitMQ는 메시지 지향 미들웨어 중 하나이며, AMQP(Advanced Message Queuing Protocol)를 기반으로 한다. Celery Executor의 경우 RabbitMQ를 Backend로 사용할 수 있으며, RabbitMQ는 큐와 관련된 다양한 기능과 함께 메시지 브로커로서 작동한다. RabbitMQ는 AMQP를 통해 효율적인 작업 처리를 지원하므로, 대용량 작업 처리에 적합합니다. -
Redis Backend
Redis는 메모리 기반의 데이터 구조 저장소이며, 영속성을 유지합니다. Celery Executor의 경우 Redis를 Backend로 사용할 수 있으며, Redis는 높은 성능과 확장성을 제공합니다. Redis는 메모리 기반의 저장소로 작업 처리 상태를 빠르게 저장하고 추적할 수 있으므로, 작업 처리 속도가 빠른 환경에서 적합합니다. -
SQLAlchemy Backend
SQLAlchemy Backend는 SQL 데이터베이스를 사용하여 작업 처리 상태를 저장합니다. Celery Executor의 경우 SQLAlchemy를 Backend로 사용할 수 있으며, 다양한 SQL 데이터베이스(MySQL, PostgreSQL, SQLite 등)를 지원합니다. SQLAlchemy는 ORM(Object-Relational Mapping)을 사용하여 SQL 데이터베이스에 대한 추상화 계층을 제공하므로, SQL 데이터베이스를 사용해야 하는 환경에서 적합합니다.
Celery Backend는 작업 처리 상태를 저장하고 추적하는 중요한 역할을 하므로, 프로젝트의 성격과 작업량, 환경 등을 고려하여 적절한 Backend를 선택하는 것이 중요합니다.
작동방식
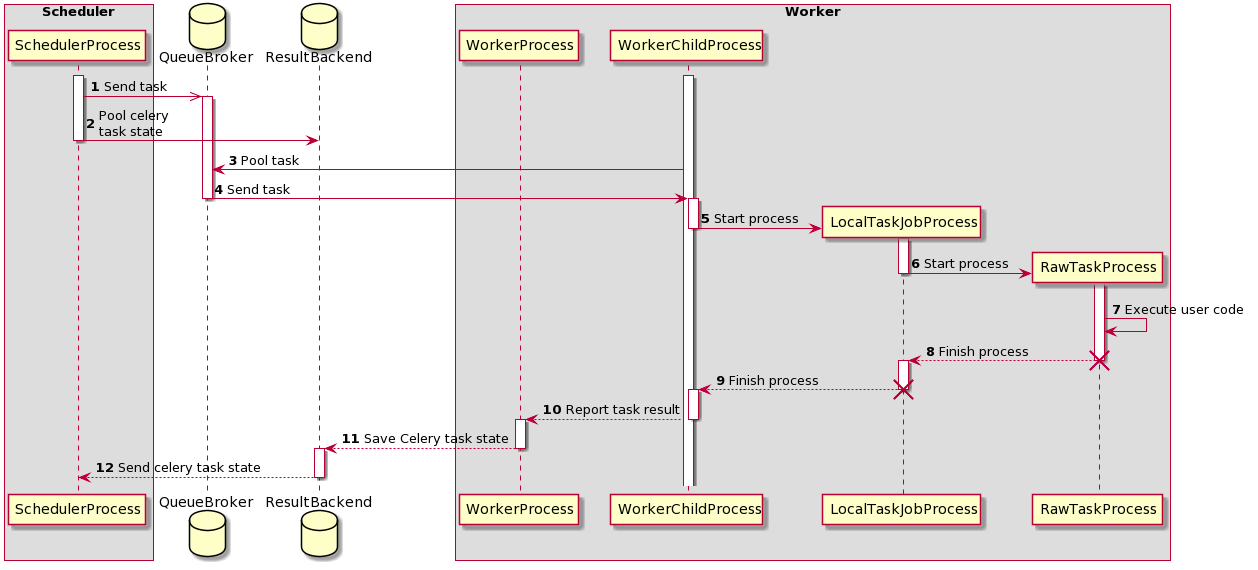
[1] SchedulerProcess는 작업을 처리하고 수행해야 할 작업을 찾으면 QueueBroker로 보냅니다 .
[2] SchedulerProcess는 또한 작업 상태에 대해 ResultBackend를 주기적으로 쿼리하기 시작합니다.
[3] QueueBroker 는 작업을 알게 되면 작업에 대한 정보를 하나의 WorkerProcess로 보냅니다.
[4] WorkerProcess는 하나의 WorkerChildProcess 에 단일 작업을 할당합니다 .
[5] WorkerChildProcess는 적절한 작업 처리 기능을 수행합니다. - execute_command(). 새 프로세스인 LocalTaskJobProcess 를 생성합니다 .
[6] LocalTaskJobProcess 논리는 LocalTaskJob 클래스별로 설명됩니다. TaskRunner를 사용하여 새 프로세스를 시작합니다.
[7][8] Process RawTaskProcess 및 LocalTaskJobProcess 는 작업이 완료되면 중지됩니다.
[10][12] WorkerChildProcess 는 기본 프로세스인 WorkerProcess 에 작업 종료 및 후속 작업의 가용성을 알립니다.
[11] WorkerProcess는 ResultBackend 에 상태 정보를 저장합니다 .
[13] SchedulerProcess가 ResultBackend에 상태에 대해 다시 요청하면 작업 상태에 대한 정보를 얻습니다.
🤖 참고로 Amazon MWAA 환경의 Apache Airflow 작업자는 Celery Executor를 사용합니다.
MWAA에서는 Redis와 Amazon SQS가 각각 Backend와 Message Broker의 역할을 분리하여 사용됩니다. 이를 통해 안정적이고 확장 가능한 분산 작업 처리를 구현할 수 있습니다.
다음시간에는 KubernetesExecutor에 대해 알아보려고 합니다.
(Airflow on Kubernetes VS Airflow Kubernetes Executor)
