
1. Introduction
기존 Diffusion 모델들을 활용하여 caption 등의 다양한 condition을 통해 2D 이미지를 생성해내는 논문들을 볼 수 있었다. 이번에 소개해드릴 논문인 DreamFusion은 주어진 caption을 이용해서 3D object를 생성해낸다. 결과를 보면 Stable Diffusion을 활용해서 만든 이미지들인데, 이를 여러 view에 대해 생성하여 하나의 object로 만들어내는 것을 볼 수 있다.

위 사진은 project page에 가면 볼 수 있다. 이미지로 저장되어 있어서 단순한 이미지 생성으로 보일 수 있지만 다른 view마다 렌더링을 하여 합침으로서 최종적으로 3D mesh를 뽑을 수 있다.
2. Diffusion models
오늘 논문의 이해를 돕기 위해 Diffusion model들에 대한 간단한 설명을 하고 넘어가보자. Diffusion model은 패턴 생성 과정을 학습하기 위해 고의적으로 패턴을 무너뜨리고 이를 다시 복원하는 확률분포를 학습한다. 여기서 패턴을 무너뜨리기 위해 forward process를 통해 각 timestep마다 Gaussian noise를 추가해가고, reverse process에서 이 timestep마다 Gaussian noise를 제거해가면서 원래의 이미지로 복원해감으로서 parameter를 학습하게 된다.
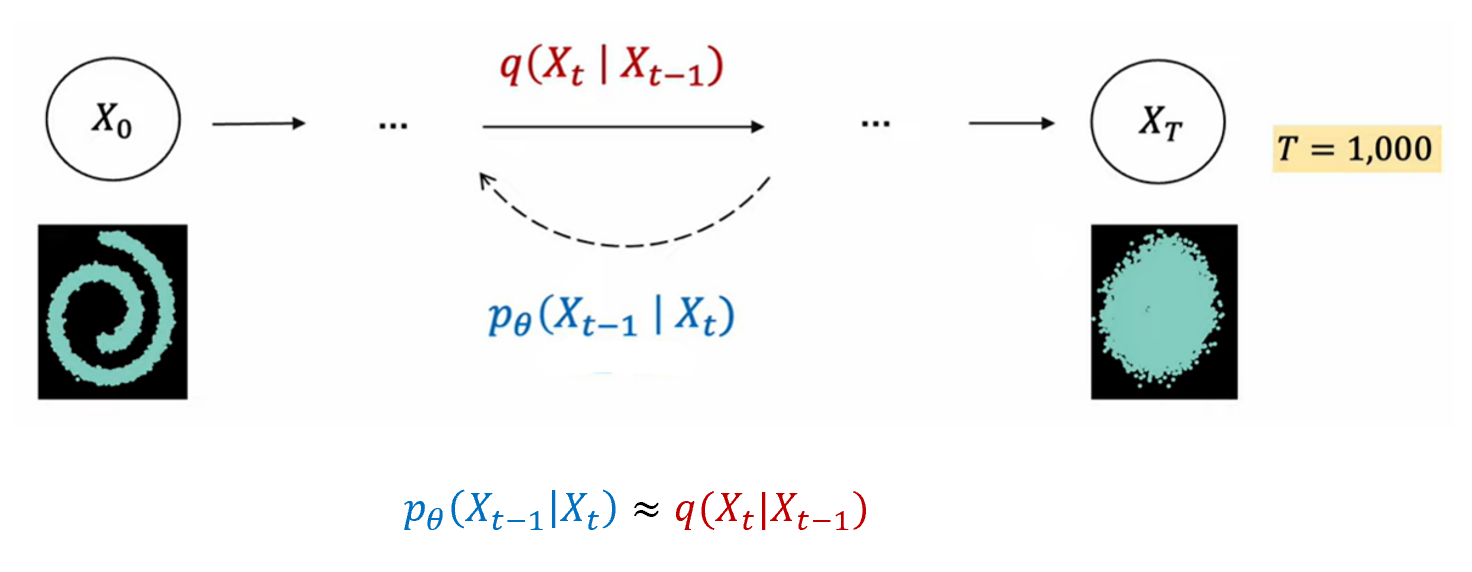
Forward process는 이전 시점인 t-1에서의 이미지에 Gaussian noise를 추가해나가는 과정이고, 아래의 식을 이용하여 noise가 주입된다. 여기서 Gaussian noise는 이고, 사전에 정의된 값이다.
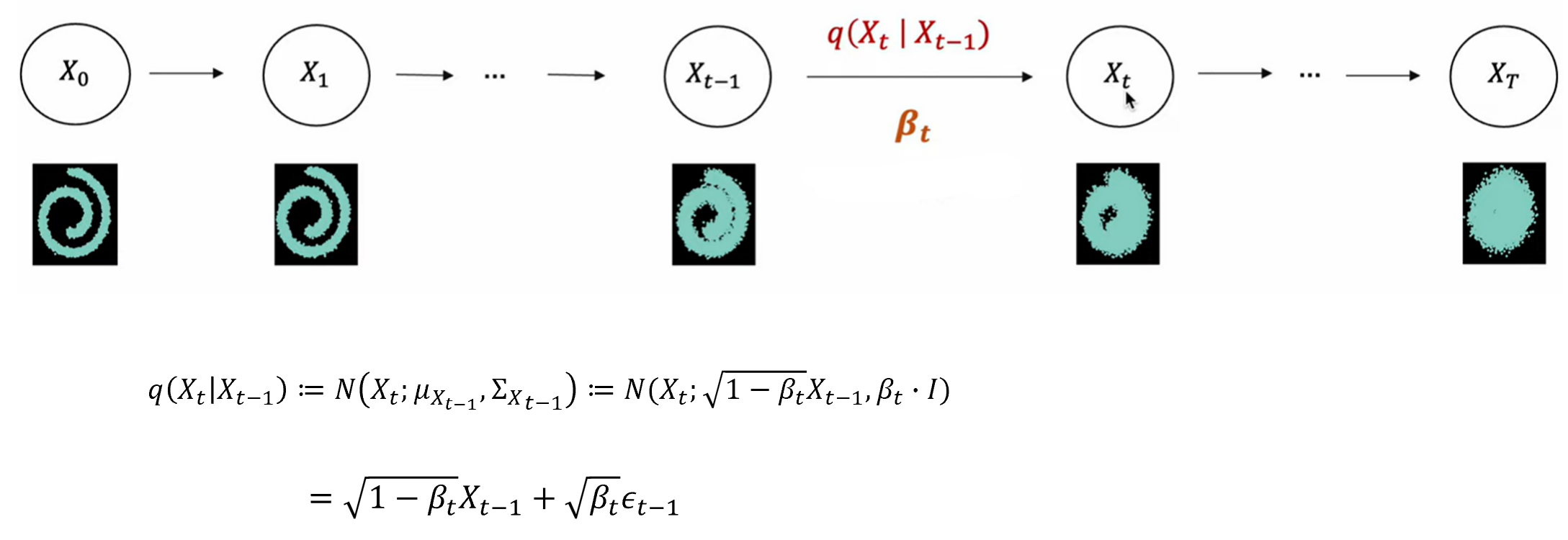
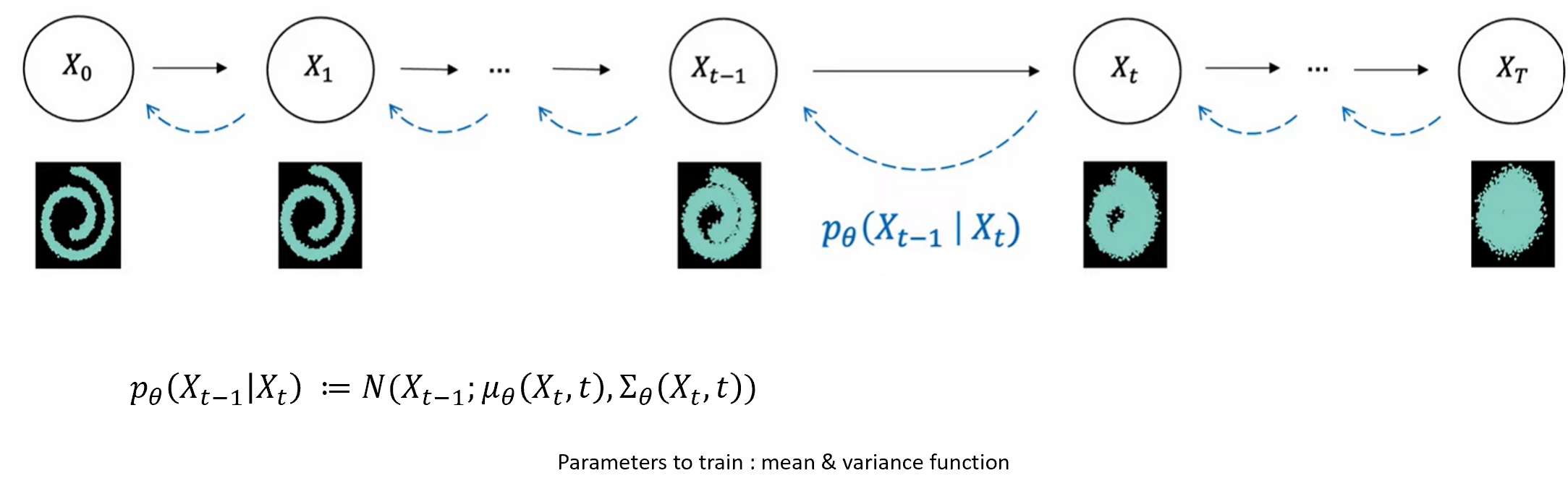
Forward process는 조건부 Gaussian 분포로 산저했고, reverse process 또한 Gaussian 분포가 된다. 차이는 forward process는 사전에 정의된 의 크기에 의해 평균과 분포가 정의되었고, reverse process는 우리가 알지 못하는 Gaussian 분포이다. 즉, 이 평균과 분산을 학습을 통해 알아내야 한다.
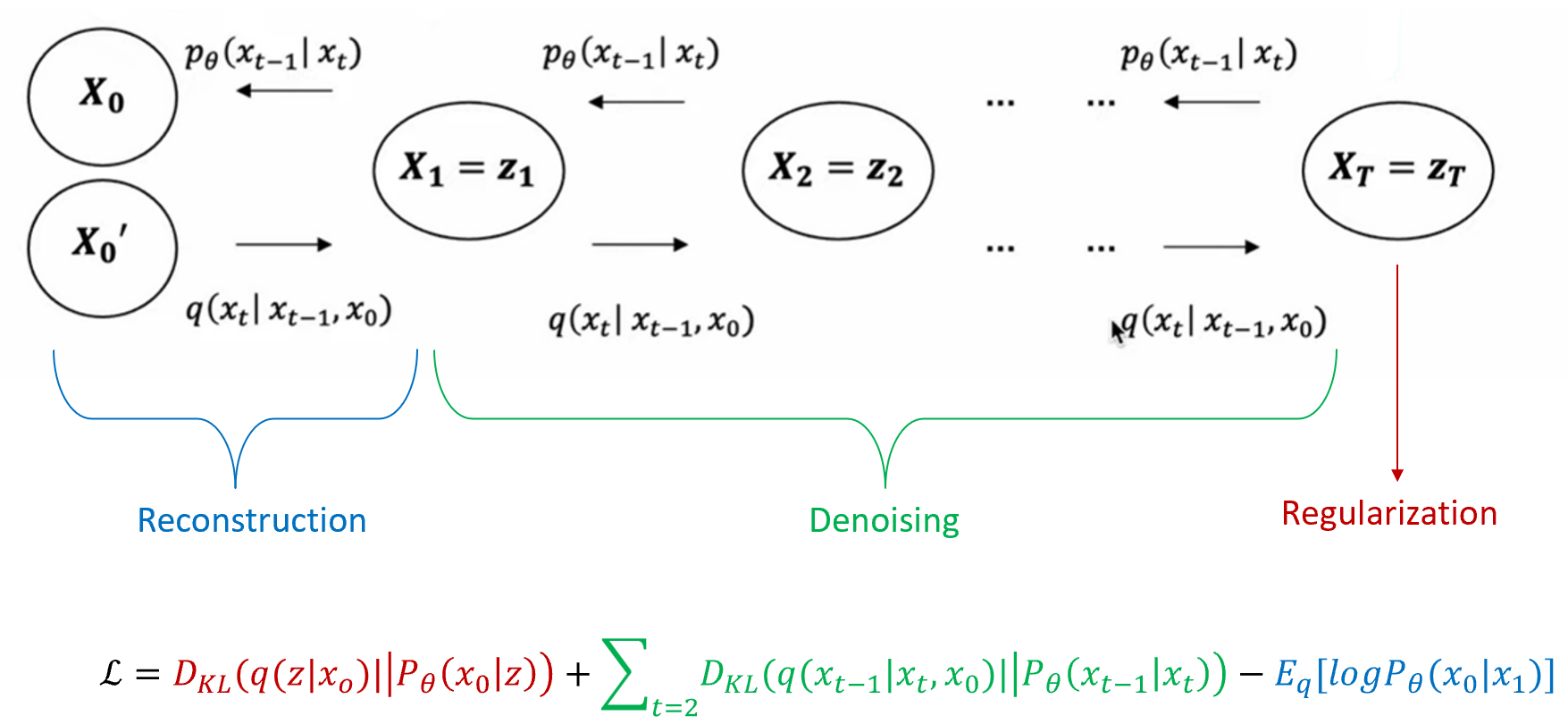
Loss term은 reconstruction loss, denoising loss, regularization loss term으로 구성괴어 있고, KL-Divergence를 이용해서 분포간의 차이를 최소화하는 방향으로 학습이 된다.
reconstruction loss는 원래의 이미지와 최종적으로 denoising되어 reconstruction된 이미지의 분포 차이를, denoising loss는 각 timestep 마다 noise가 추가된 이미지와 noise가 제거된 이미지의 분포 차이를, regularization term은 최종적으로 noise가 추가된 이미지에서의 Gaussian 분포와 standard Gaussian 분포의 차이를 비교한다.
2.1. DDPM (Denoising Diffusion Probabilistic Models)
DDPM에서 이전과 살짝 다른 부분이 있어서 짚고 넘어가보겠다. 기존 Diffusion model은 각 timestep마다 noise를 추가해가면서 서서히 Gaussian 분포로 바꿔나갔다. 하지만 이 과정을 1000번 수행하는건 상당히 비효율적이다. DDPM은 forward process를 한번에 수행해내는 수식을 발견한다. Loss function에서는 기존에 있던 regularization, reconstruction loss term을 배제하고 denoising loss term만 사용한다. 기존 Diffusion model과 다르게 에서 시점으로 계산을 할 수 있으므로, 즉 정답 분포의 평균과 분산을 알고 있으므로 noise만 예측하면 되는 꼴로 바뀌게 된다.
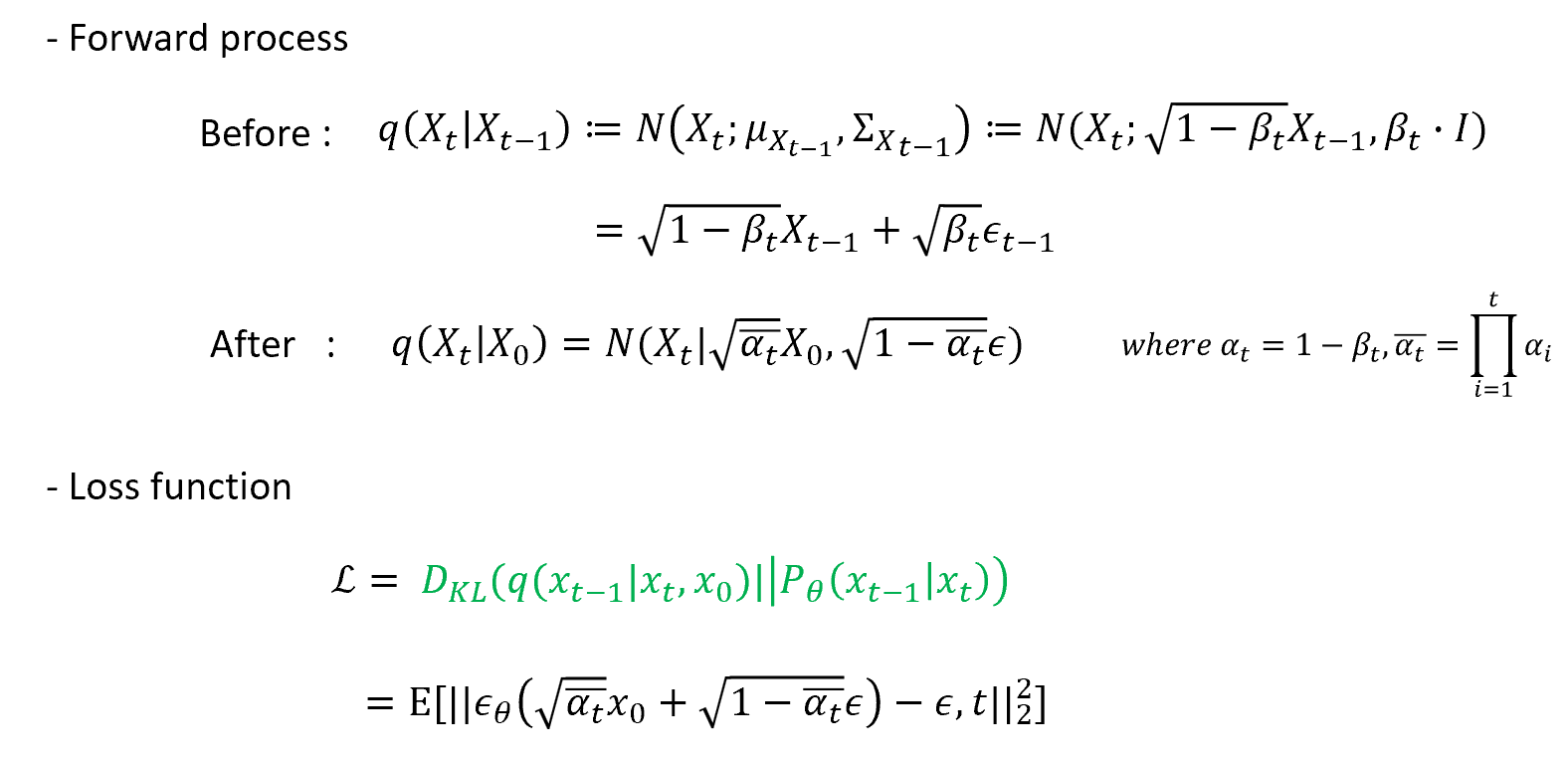
모델 architecture로 U-Net을 사용하고, 를 입력으로 를 만드는데 추가된 noise를 예측한다.
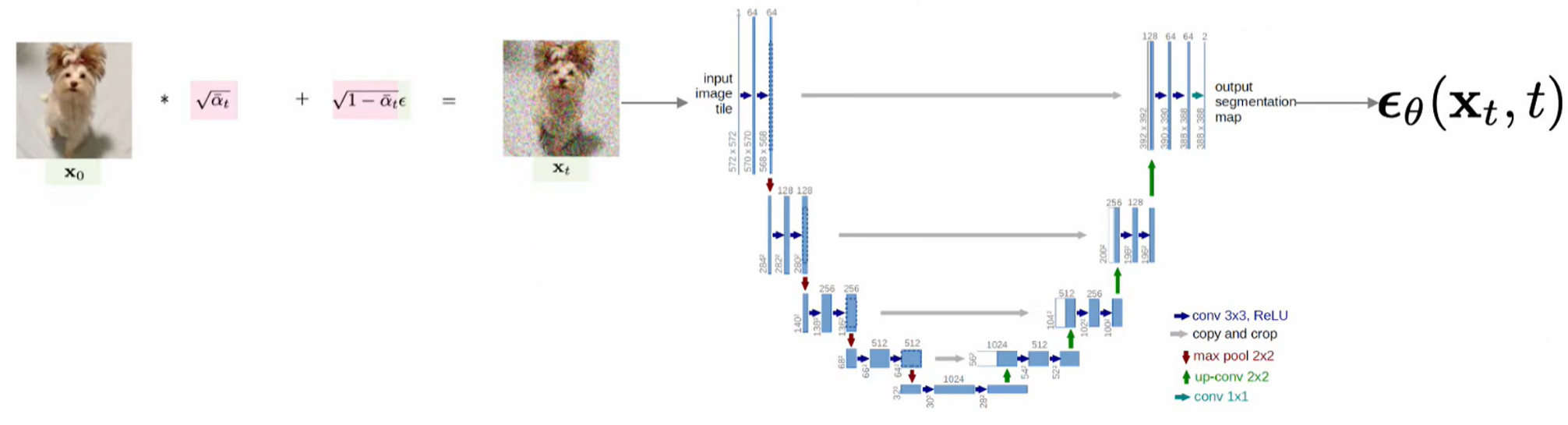
2.2. Latent Diffusion Model (Stable Diffusion)
Latent Diffusion model은 perceptual compression을 진행한 뒤에 forward process를 진행한다는 차이점이 있다. 일반적인 모델은 pixel space model, compression을 진행한 모델은 latent space model이라고 부른다. Perceptual compression을 진행하는 이유는 high frequency 한 이미지 정보가 우리 눈에게는 필요할 수 있지만 컴퓨터가 학습하는데에는 배제할 수 있으므로 compression을 한 다음 Diffusion process를 진행한다. 과정은 Autoencoder를 통해 이미지를 벡터로 encoding한 후, U-Net에 text encoder block, cross-Attention 을 추가하여 text같은 condition을 주입하게 된다. Training 과정에서는 학습된 Autoencoder를 사용해서 이미지를 latent vector로 만들게 되고, U-Net을 통해 이 latent vector에 얼마나 noise가 추가되었는지 모델이 예측을 하게 되는데, 여기에 추가적으로 text가 cross-Attention 층에 들어가게 된다. Loss function은 기존의 DDPM과 동일하지만, 가 추가적으로 들어간걸 볼 수 있다.
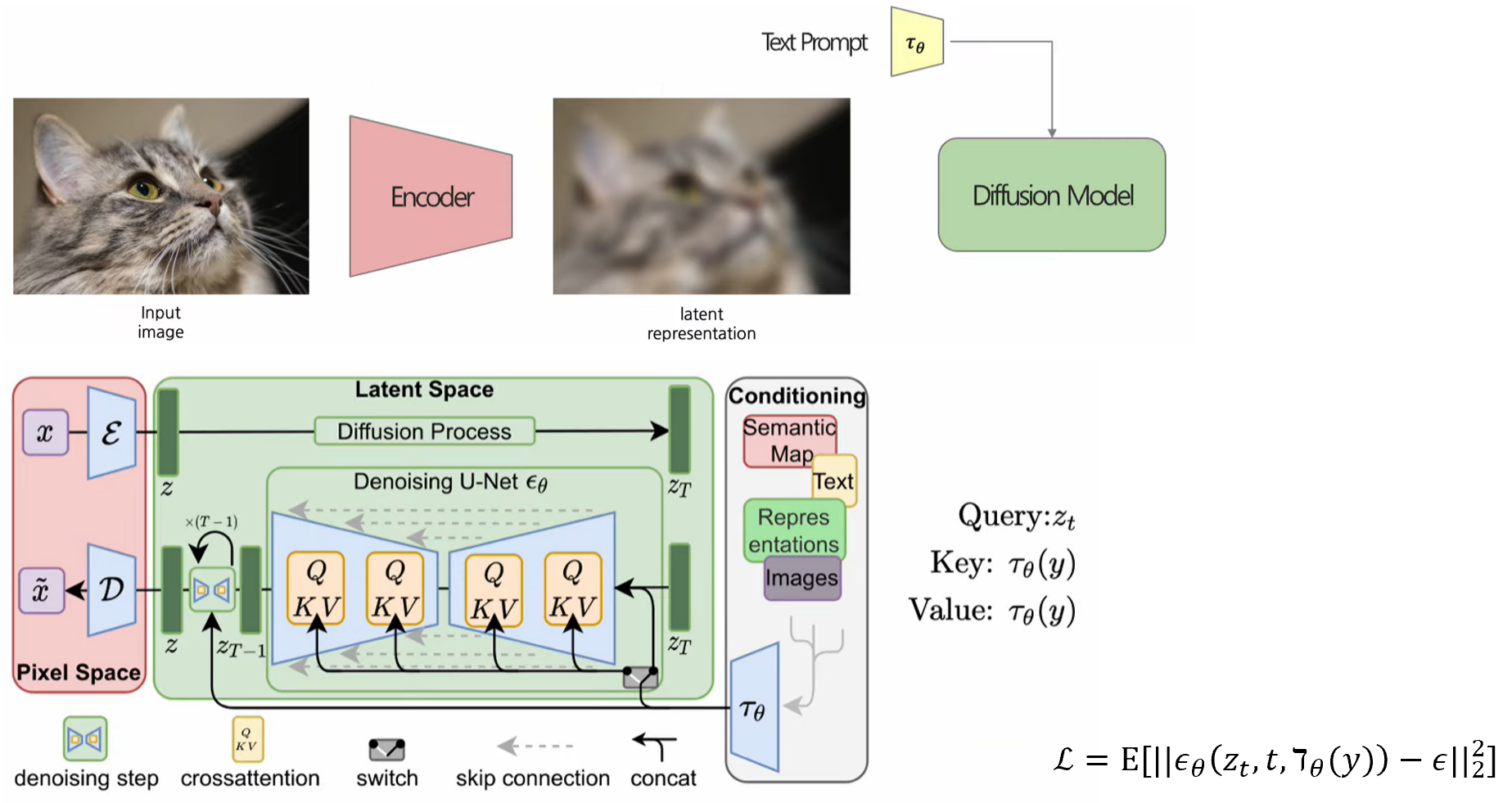
다시 한 번 loss term을 짚고 가자면, 최초 Diffusion 모델은 regularization, reconstruction, forward process에서의 loss들을 모두 더하여 최소화를 했다.
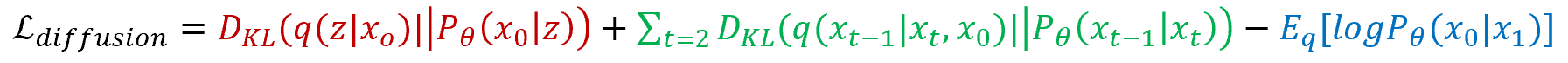
여기서 DDPM은 forward process에 대해서만 loss term을 이용하고, 추가적으로 평균과 분산을 사전에 계산할 수 있었으므로 이를 이용하여 noise만 예측할 수 있었다.
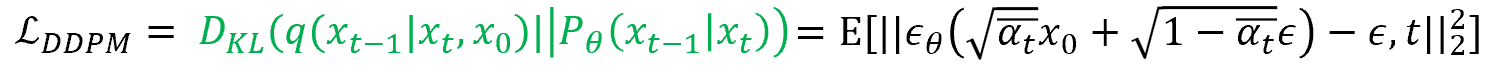
Latent Diffusion model에서는 condition이 추가되어 loss term에 약간의 변동이 있는 것을 확인할 수 있었다.

3. Overview
모델의 전체적인 구조는 다음과 같다.
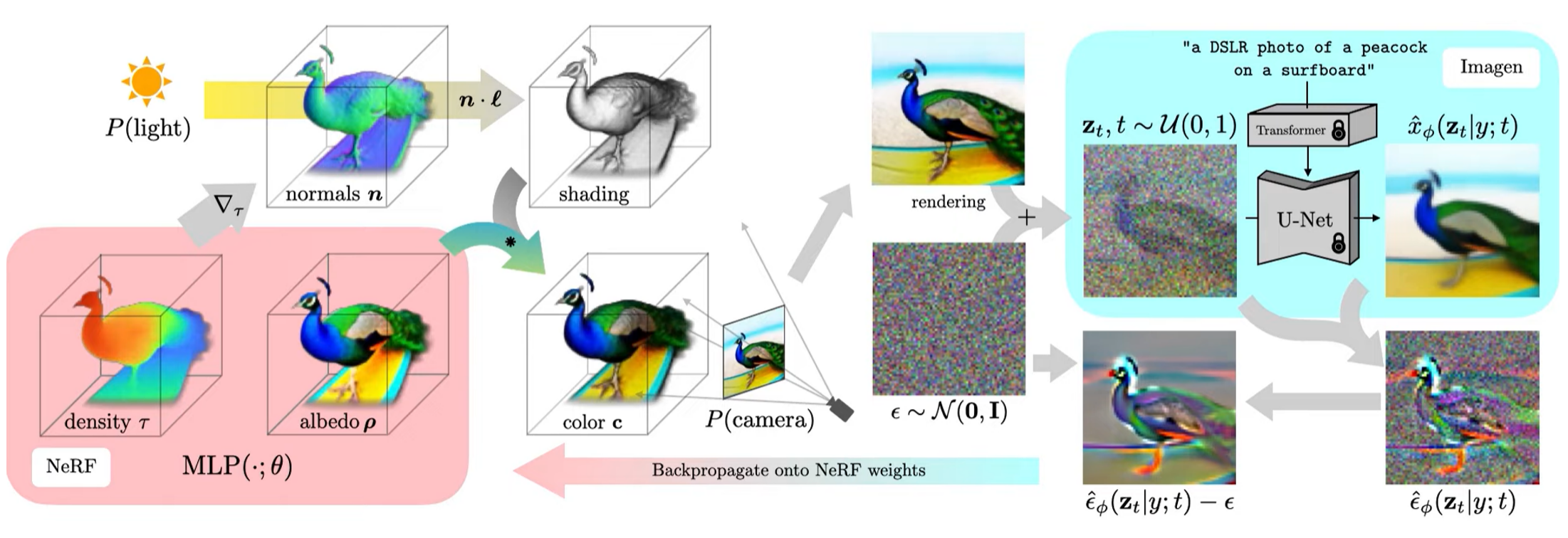
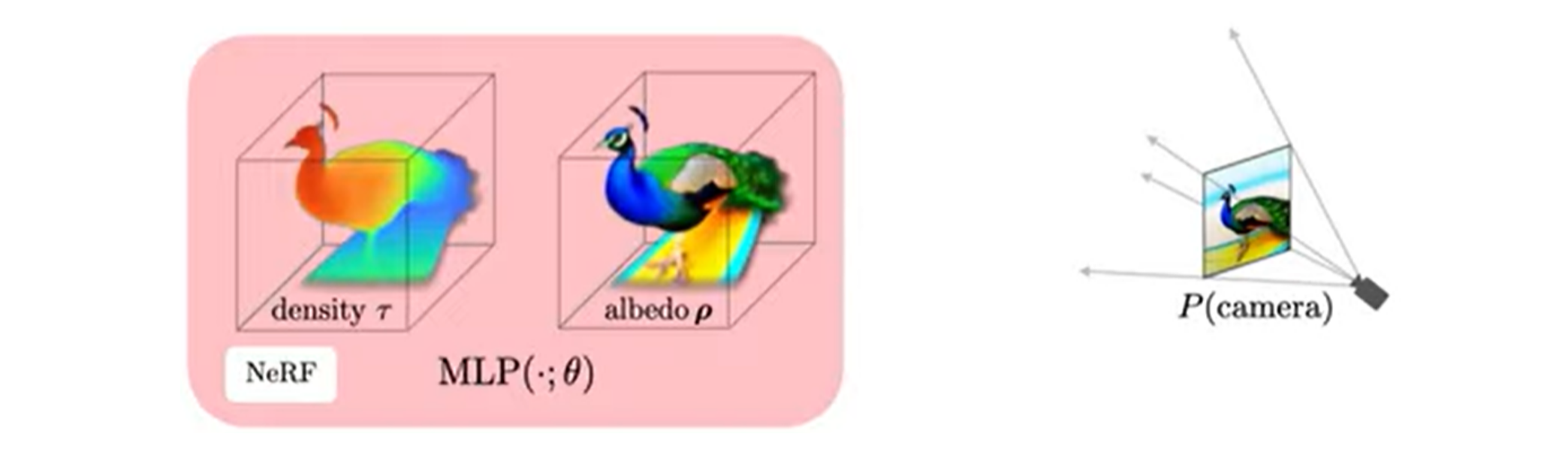
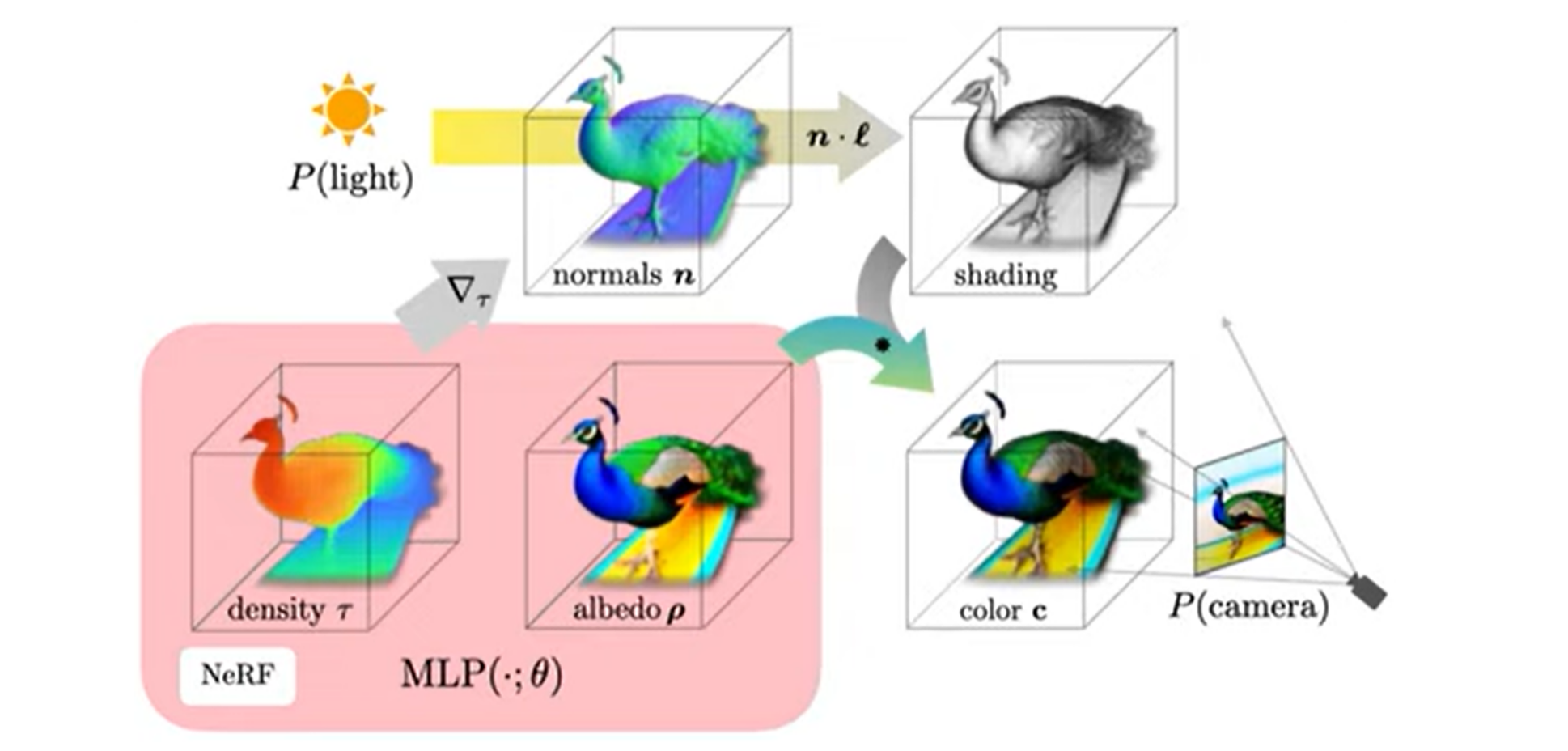
DreamFusion은 scene을 Neural Radiance Field (NeRF) 를 이용해서 표현한다. NeRF는 MLP를 통해 density와 color를 파라미터화한다.
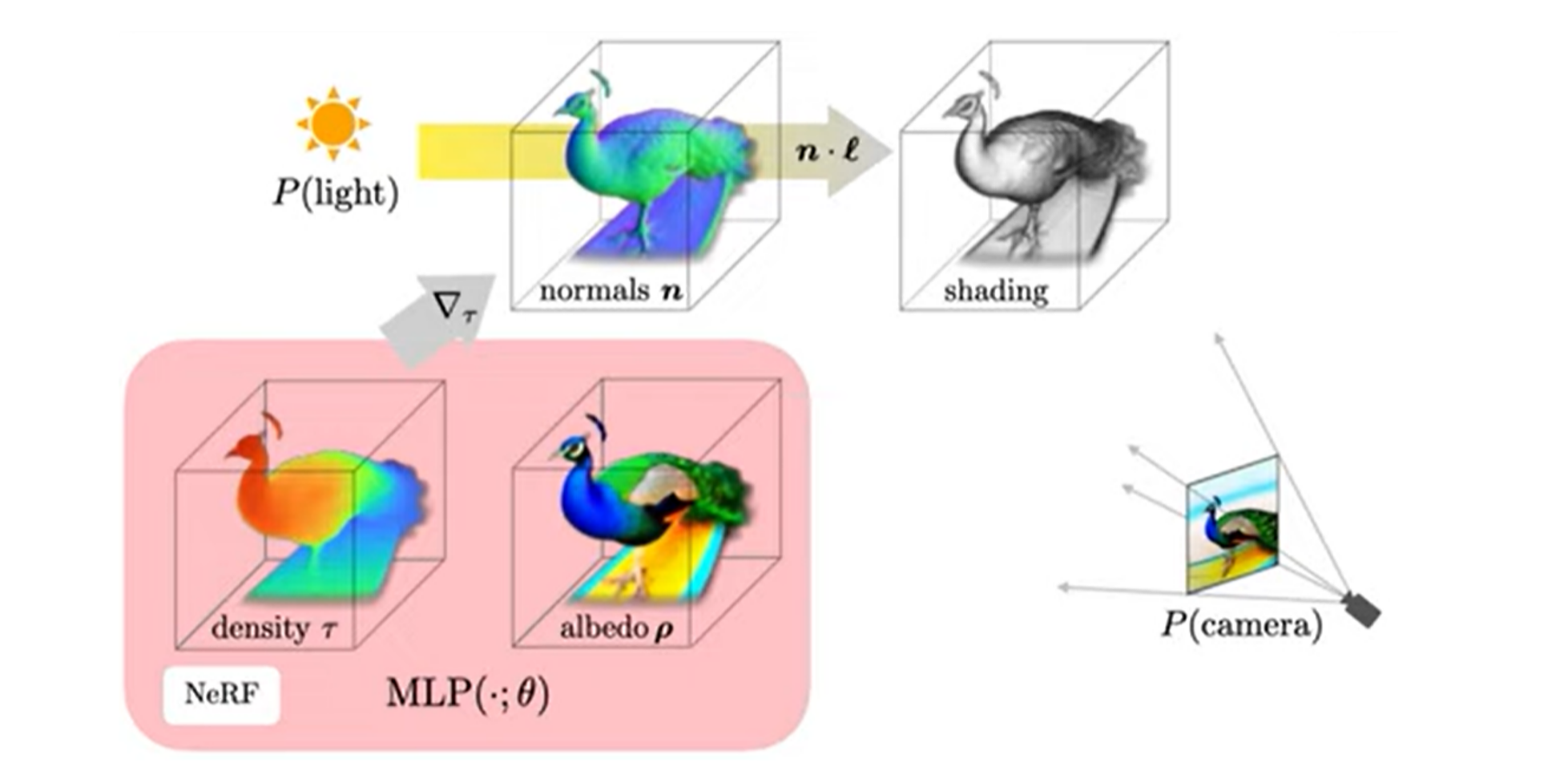
다음으로 random한 camera pose와 light pose, density를 이용해서 shading을 할 수도 있고,
color 정보도 이용하여 렌더링을 할 수 있다.
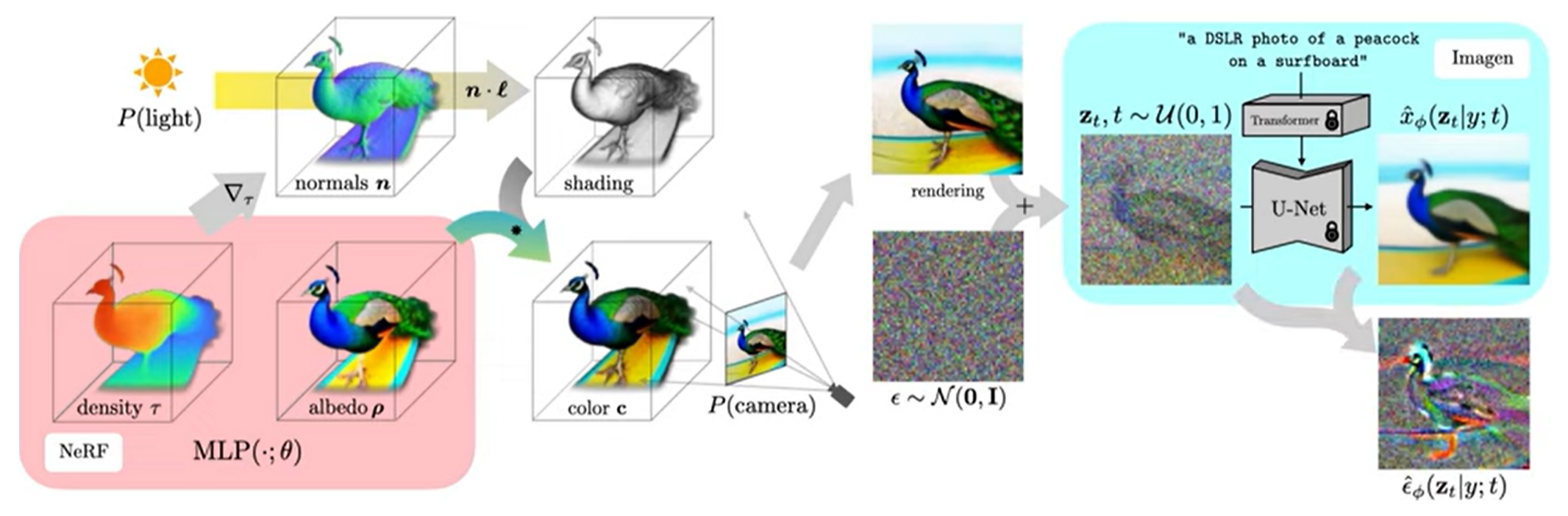
파라미터를 업데이트하기 위해 DreamFusion은 렌더링된 이미지에 noise를 더한 후, encoding된 text와 reconstruction된 이미지를 이용해서 주입된 noise를 예측하게 된다.
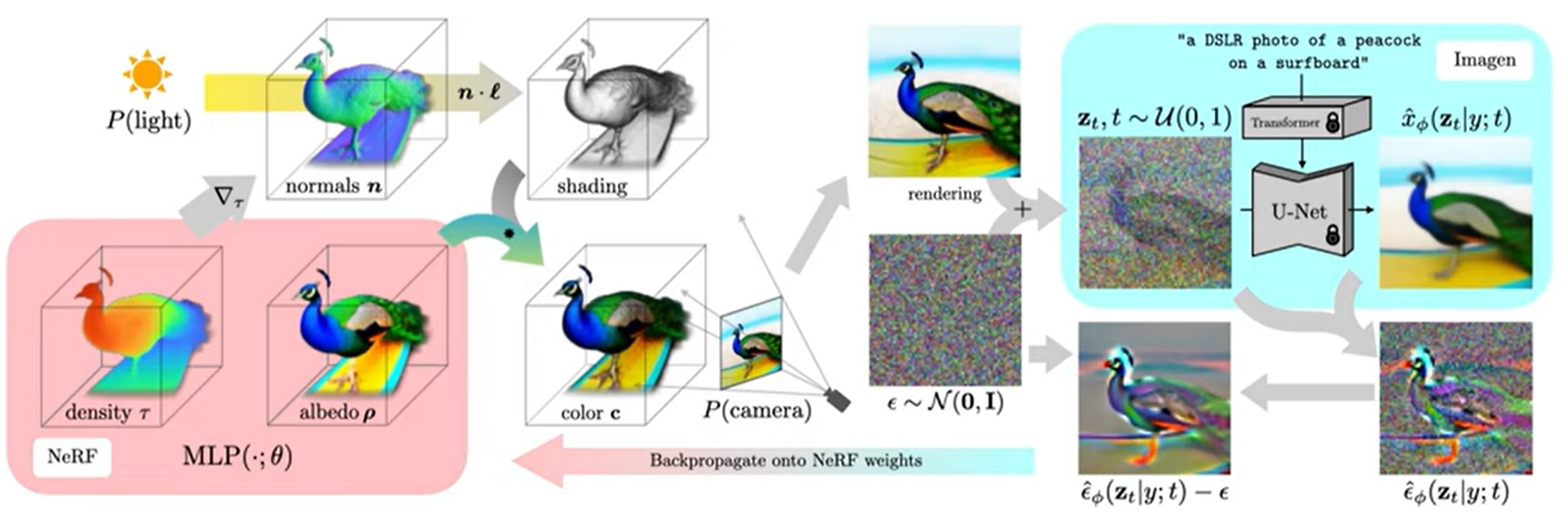
그 다음 주입된 noise를 빼서 NeRF의 MLP 파라미터를 업데이트하도록 rendering process를 따라 backpropagation을 진행한다. 이 과정을 3D 모델이 만족스러운 결과를 낼 때까지 진행하면, 모델을 통해서 mesh 획득이 가능하고, scene에 사용 또한 가능하게 된다.
4. DreamFusion algorithm
DreamFusion의 세부적인 부분을 살펴보자.
4.1. Random camera & light sampling
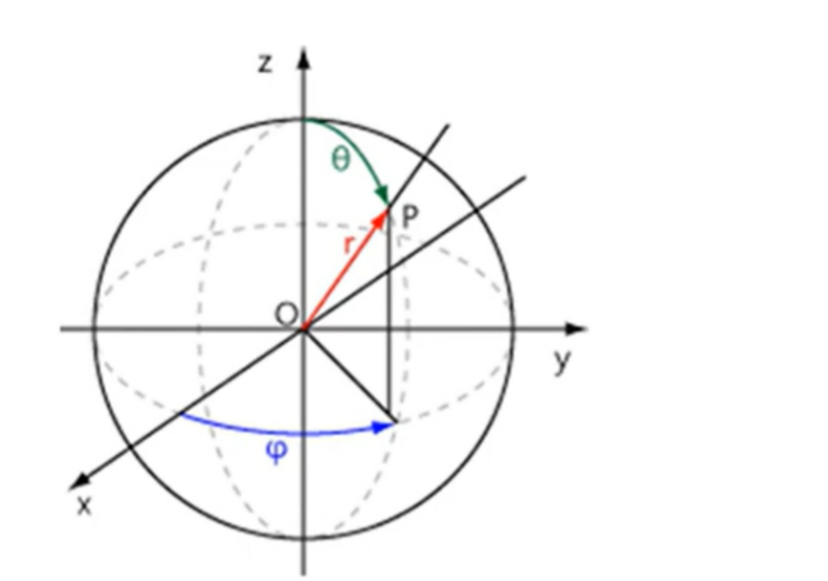
우선 random한 카메라 pose와 light pose, density를 이용해서 shading을 한다 되어있는데, 이 camera pose와 light pose는 각 iteration마다 random하게 sampling을 하여 얻는다. Camera pose는 구면 좌표계에서 , , 거리는 1~1.5 사이에서 sampling을 하고, point light의 pose는 camera pose를 중심으로 한 분포 주변에서 sampling을 한다.
4.2. Rendering
NeRF에서 이미지를 rendering하는 것은 카메라의 중심에서 이미지 픽셀 위치로 쏘는 ray를 casting하여 수행된다. 각 ray를 따라 sampling된 3D point들은 MLP를 통과하여 density와 RGB를 출력하고, density와 color를 카메라 방향으로 alpha compositing하여 최종 rendering을 하게 된다. 또한 이전 연구에서 density의 음의 기울기를 normalize 하면 object의 normal 정보를 얻을 수 있다 했는데, 이 normal 정보와 light position, albedo를 diffuse reflectance () 를 이용해서 shading 또한 할 수 있다. 마지막으로 random하게 특적 albedo를 white로 바꿔서 textureless shading도 진행할 수 있고, 위 세 가지 방법 중 하나를 random하게 선택해서 학습을 진행한다.
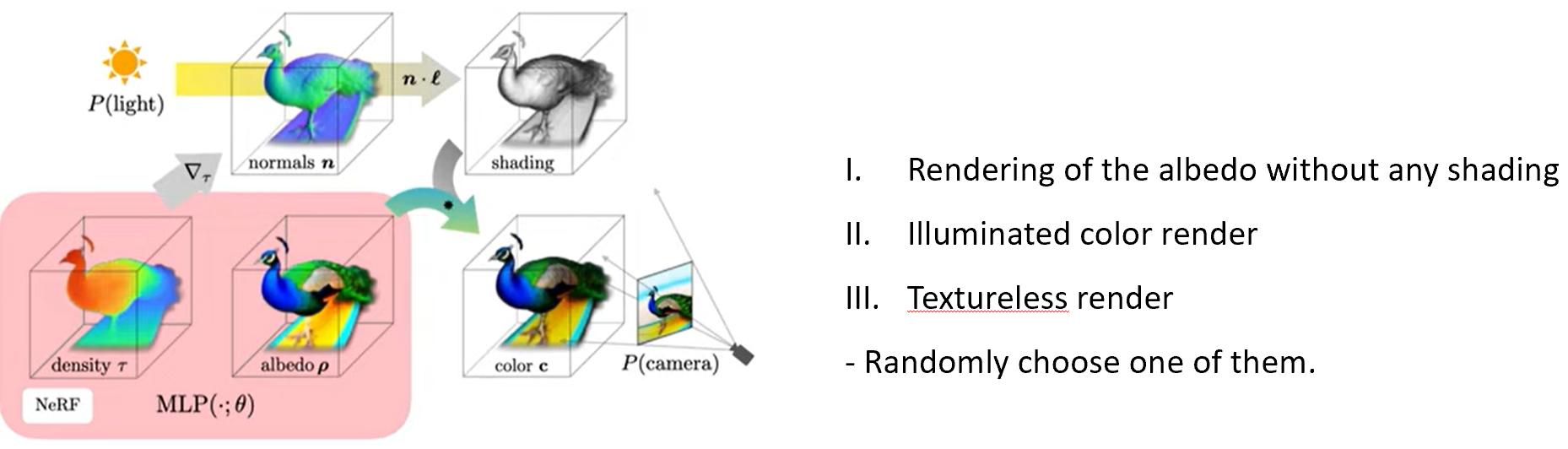
4.3. Diffusion loss with view-dependent conditioning
View-dependent conditioning은 texp prompt에 생성하고 싶은 view point를 추가해서 text prompt engineering을 진행하는 것이다. Text prompt가 standard한 view에서는 잘 생성하지만, 다른 view를 sampling하면 좋은 설명이 되지 못한다. 그래서 추가적인 text를 append함으로서 해결한다. 예를 들어 고도각이 보다 크다면 overhead view를, 이하면 방위각에 따라 front view, side view, back view를 append한다.
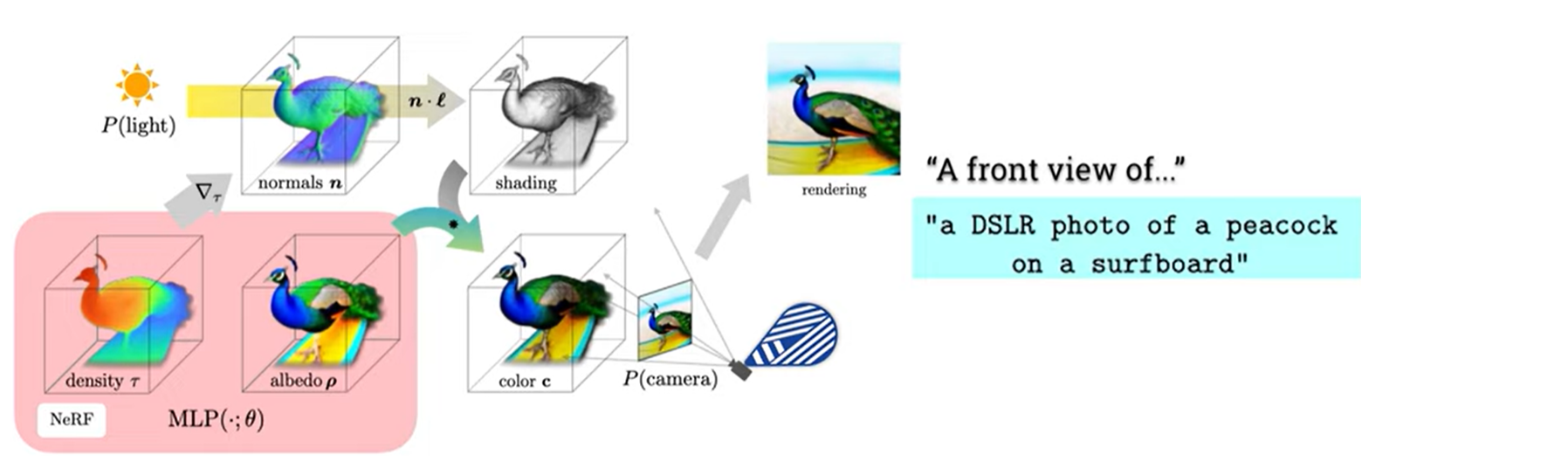
주어진 과정들을 이용해서 렌더링된 이미지와 특정 timestep이 있을 때, 여기서 noise를 sampling하여 loss 값을 구하고, 이를 통해 NeRF의 파라미터를 업데이트한다.
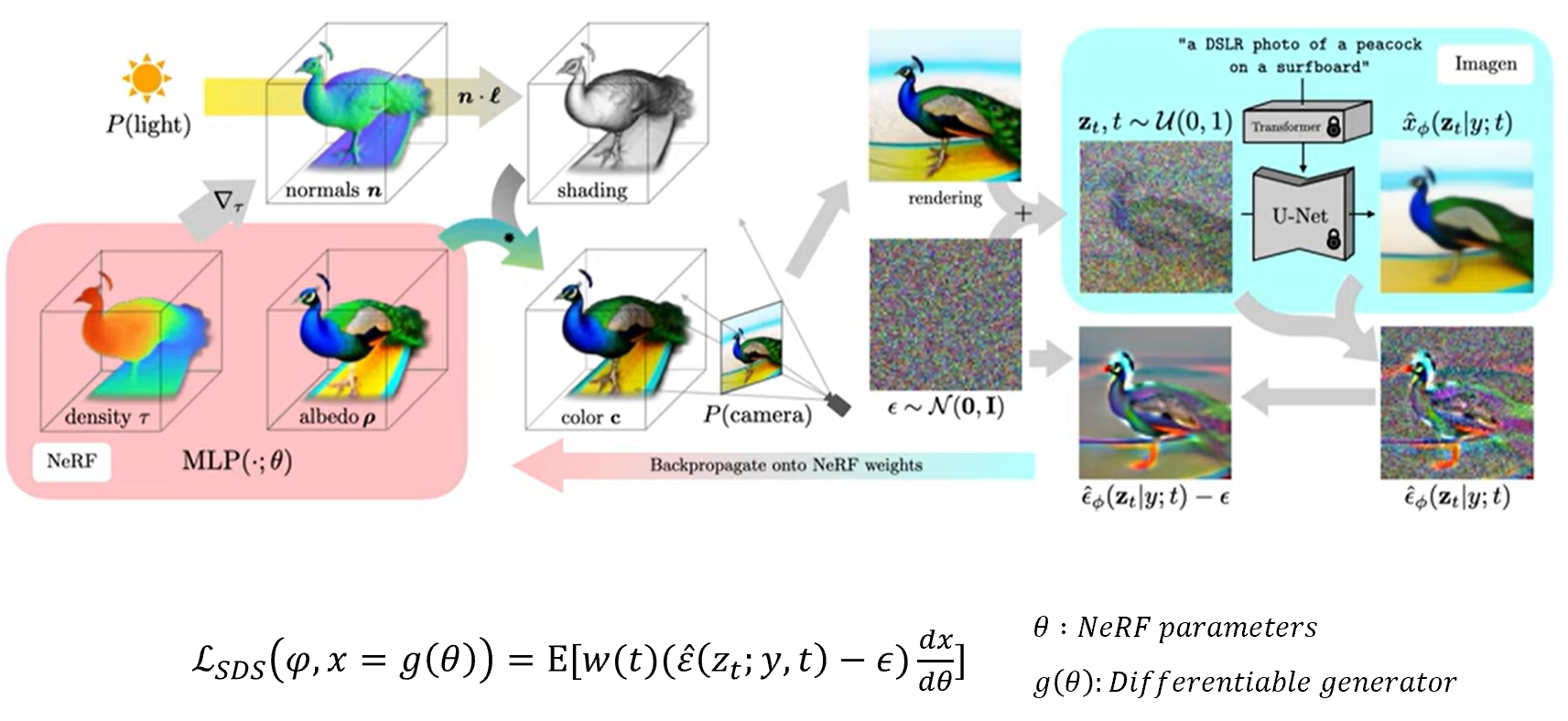
Loss function의 이해를 위해 이전에 제안된 Latent diffusion model에서의 loss function을 다시 보면, 여기서 는 입력 이미지이고, 입력 이미지에 Gaussian noise가 추가되서 U-Net을 통해 생성된 Gaussian noise를 빼주면서 새로운 이미지를 생성하게 되는데, 이 두 이미지 간의 차이를 이용해서 loss값을 업데이트하게 됩니다. 반면에 DreamFusion은 가 입력이미지가 아닌 NeRF로 생성된 이미지이므로 NeRF 파라미터를 가진 미분가능한 generator로 정의할 수 있다. 이미지가 NeRF 파라미터로 만들어진 이미지이므로 이미지 를 로 미분하여 NeRF의 파라미터를 업데이트하는 수식이 된다.
5. Experiments
평가지표로는 입력 문자에 대한 렌더링된 이미지의 일관성을 측정하는 CLIP R-precision으로 평가했다고 한다. View synthesis 분야에서는 rendering된 view와 ground-truth를 비교하기 위해 PSNR을 사용하지만, ground-truth가 없으므로 사용할 수가 없다. R-precision은 ClIP rendering된 scene에서 올바를 caption을 가져올 때의 정확도이다.

