1. Abstract & Introduction
Multi-View Stereo (MVS)는 이미지 간의 대응점을 통한 3차원 재구성을 위해 카메라 내부 파라미터와 외부 파라미터를 요구하지만, 이 파라미터를 구하는 과정은 상당히 번거롭다. DUSt3R은 Dense and Unconstrained Stereo 3D Reconstruction의 약자로, 문장에서 예상할 수 있듯이 카메라 파라미터나 포즈에 대한 사전 정보 없이 이미지를 통해 카메라 파라미터와 포즈를 복원한다.
논문에서 소개한 네트워크는 일반적인 transformer 구조로 이루어져있고, 이미지 쌍으로부터 scene을 3D pointmap을 계산한다. 이 pointmap은 scene의 가하학 정보, 픽셀과 scene 간의 관계, 두 시점 간의 관계를 포함한 풍부한 정보를 가지고 있고, 계산된 pointmap을 이용하여 카메라 파라미터와 scene의 가하학 정보를 복원할 수 있다. 복원된 정보를 이용하여 다양한 3D vision task를 수행할 수 있고, 다양한 분야에서 SOTA의 성능을 보이고 있다.
지금까지 대부분의 3D vision 분야의 논문들이 실험을 위해 아직까지도 COLMAP을 사용하였는데, 이 방법론의 등장으로 새로운 패러다임이 제시되었다고 생각한다.
2. Method
- Pointmap
Pointmap X는 이미지 각 픽셀에 대응되는 3차원 좌표로, 해상도가 W×H인 이미지가 있다면, W×H×3 의 pointmap을 형성하게 된다. 본 논문은 카메라에서 scene을 향하는 ray가 하나의 3차원 점을 맞춘다고 가정한다.
- Cameras and scene
카메라의 내부 파라미터 K와 외부 파라미터 [R∣t], world 좌표계에서 정의된 3차원 좌표 X를 이용하여 이미지 좌표계에 대응하는 픽셀 좌표를 계산할 수 있다.
⎣⎢⎡ij1⎦⎥⎤=K[R∣t]X
카메라의 내부 파라미터 K가 주어져 있고, 실제 depth map D가 있다면, pointmap X는 다음과 같이 계산할 수 있다 (pointmap은 카메라 좌표계에 정의되어있다 가정).
Xi,j=K−1Di,j⎣⎢⎡ij1⎦⎥⎤
n 카메라와 m 카메라가 있다면, m 카메라 좌표계에서 정의된 n 카메라에 대응되는 pointmap Xn,m은 n 카메라의 외부파라미터 Pn 과 m 카메라의 외부파라미터 Pm 을 통해 다음과 같이 계산할 수 있다.
Xn,m=PmPn−1h(Xn)
여기서 h는 homogeneous 좌표계를 뜻한다. Pm,Pn은 [R∣t] 이다. 즉, Pn−1h(Xn)을 통해 pointmap을 world 좌표계에 정의하고, Pm과의 연산을 통해 m 카메라 좌표계에 정의된 pointmap을 계산하게 되는 것이다.
2.1. Overview
네트워크 f는 두 개의 이미지 I1,I2를 입력으로 받아 각 이미지 픽셀에 대응하는 pointmap X1,1,X2,1∈ℜW×H×3과 각 픽셀에 대응하는 pointmap의 확신 각 픽셀에 대응하는 pointmap의 신뢰도를 나타내는 confidence map C1,1,C2,1∈ℜW×H 를 출력한다. 이렇게 나타낸 이유는 두 pointmap 모두 1번 카메라 좌표계에 대해 나타내므로 다음과 같이 표현한다.
네트워크 구조는 다음과 같다.
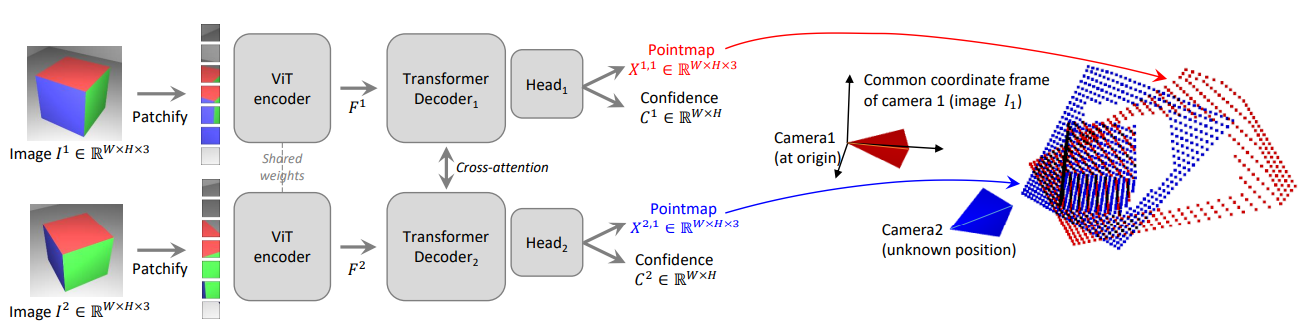
우선 기존의 ViT와 마찬가지로 이미지들을 패치로 나누어 flatten한 후 linear projection을 통해 일정한 크기의 latent vector로 나타낸 후 각각의 encoder에 입력하게 된다. 이 때 두 개의 encoder는 weight를 공유하여 동일한 feature 표현을 보장하여 비슷한 feature space에 임베딩하도록 한다.
F1=Encoder(I1)F2=Encoder(I2)
Decoder는 일반적인 Transformer 구조를 이용하여 각 decoder block에서 self-attention과 cross-attention을 순차적으로 진행한다.
Gi1=DecoderBlock(Gi−11,Gi−12)Gi2=DecoderBlock(Gi−12,Gi−11)
i는 B 개의 decoder block에 대해 1,…,B 번 수행하고, G01,G02 는 encoder를 통해 나온 F1,F2로 정의한다.
G01,G02=F1,F2G11,G12=DecoderBlock(G01,G02),DecoderBlock(G02,G01)⋮GB1,GB2=DecoderBlock(GB−11,GB−12),DecoderBlock(GB−12,GB−11)
마지막으로, 각 branch에서의 head가 decoder의 token들을 받아서 pointmap과 confidence map을 출력하게 된다.
X1,1,C1,1=Head1(G01,…,GB1)X2,1,C2,1=Head2(G02,…,GB2)
2.2 Training Objective
학습을 위한 loss function으로는 3D Regression loss와 Confidence-aware loss를 사용한다.
2.2.1. 3D Regression loss
실제 pointmap을 Xˉ1,1,Xˉ2,1이라 하자. 실제 pointmap은 이전에 이야기했듯, 카메라의 내부 파라미터와 실제 depth를 알고 있다면 쉽게 구할 수 있다. 네트워크는 실제 pointmap에 대응하는 depth map D1,D2에서 유요한 픽셀 i∈Dv(v∈{1,2})에 대해 실제 pointmap과 예측된 pointmap 간의 Euclidian distance를 최소화하는 방향으로 학습한다.
Lregr(v,i)=∣∣∣∣∣∣∣∣∣∣z1Xv,1−zˉ1Xˉv,1∣∣∣∣∣∣∣∣∣∣z=∣D1∣+∣D2∣1v∈{1,2}∑i∈Dv∑∣∣Xiv∣∣
여기서 z는 예측된 pointmap과 실제 pointmap간의 scale을 normalize하기 위해 사용된다.
2.2.2. Confidence-aware looss
하늘처럼 무한한 곳이거나, 투명한 물체와 같은 부분에 대해서는 잘못 계산된 3차원 좌표들이 있을 수 있다. 따라서 이 부분에 해당하는 픽셀에 대해 얼마나 확신하는지를 나타내는 점수를 함께 학습한다. 최종 학습의 목적 함수는, 모든 유효한 픽셀에 대해 regression loss에 confidence를 곱한 것이다.
Lconf=v∈{1,2}∑i∈Dv∑Civ,1Lregr(v,i)−αlogCiv,1
2.3. Downstream Applications
2.3.1. Point matching
2차원 이미지에서는 SIFT와 같은 feature를 얻는 기법을 이용하여 keypoint를 찾았다. 본 논문은 두 카메라에 대해 얻은 pointmap을 이용하여, pointmap간의 가장 가까운 점들을 찾는 Nearest Neighbor 기법을 이용하여 두 카메라 모두 대응하는 3차원 좌표를 계산한다.
2.3.2. Recovering intrinsics
카메라의 내부 파라미터는 다음과 같이 정의된다.
K=⎣⎢⎡fx000fy0CxCy1⎦⎥⎤
우선 이미지의 높이와 너비를 알고 있고, 높이와 너비가 같으므로 주점인 Cx,Cy는 쉽게 구할 수 있다.
Cx=Cy=2H
내부 파라미터를 구하기 위해서는 카메라의 focal length만 계산하면 된다.
이미지 평면의 좌표는 카메라 좌표계에서 정의된 pointmap과 카메라의 내부 파라미터 간의 내적을 통해 계산된다. (1번 카메라에 대한 수식)
⎣⎢⎡ij1⎦⎥⎤=⎣⎢⎡f000f0CC1⎦⎥⎤⎣⎢⎢⎡Xi,j,01,1Xi,j,11,1Xi,j,21,1⎦⎥⎥⎤
Focal length인 f는 다음과 같은 수식을 최소화하는 f를 구하여 카메라의 focal length를 계산할 수 있다.
f1∗=f1argmini=0∑Wj=0∑HCi,j1,1∣∣∣∣∣∣∣∣∣∣(i,j)−fXi,j,21,1(Xi,j,01,1,Xi,j,11,1)∣∣∣∣∣∣∣∣∣∣
여기서 Ci,j1,1은 주점이 아닌 1번 카메라 pointmap의 각 픽셀에 대응하는 신뢰도를 계산한 confidence map이다.
2.3.3. Relative pose estimation
두 카메라 간의 상대적인 위치를 추정하는 방법은 세 가지가 있다.
- 두 이미지 간의 2D matching을 진행하고, 위의 방법을 통해 두 카메라의 내부 파라미터를 계산한다면, epipolar geometry를 통해 두 카메라 간의 변환관계를 설명하는 R,t를 계산할 수 있다.
- Procrustes alignment를 이용해서 두 pointmap을 비교할 수 있다.
P∗=σ,R,targmini∑Ci1,1Ci1,2∣∣σ(RXi1,1+t)−Xi1,2∣∣2
- 더 robust한 솔루션은 RANSAC과 PnP (Perspective n point) 알고리즘을 사용하는 것이다.
2.4. Global Alignment

아주 흥미로운 글입니다!