Transformer 논문의 제목은 'Attention is all you need'이다. 제목에서 알 수 있듯, Transformer는 RNN의 고질적인 문제(기울기 소실, 정보 손실)를 지적하며 기존의 Seq2Seq의 인코더-디코더 구조와 Attention 이론을 이용하여 RNN보다 우수한 성능을 보인다.
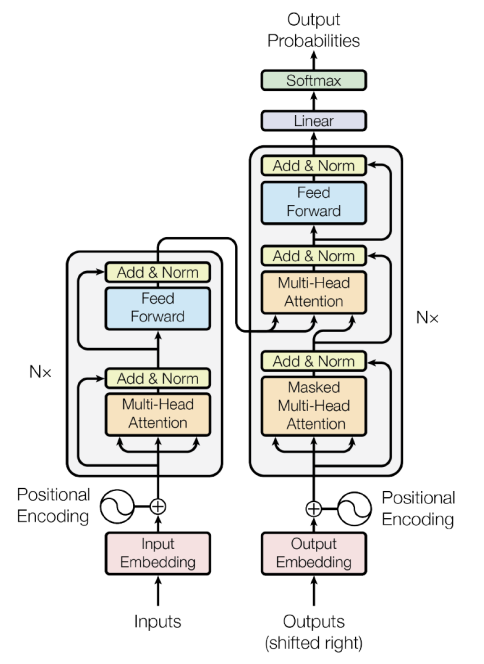
모델의 입력부터 출력까지 위 모델의 그림에 따라 정리해보겠다.
1. Input embedding
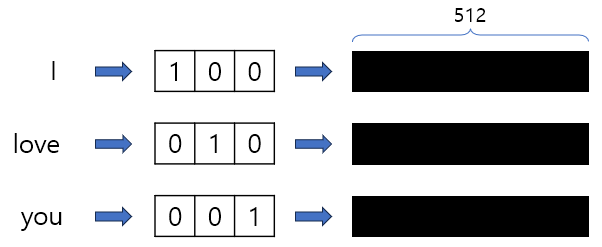
우선 입력 시퀀스는 'input embedding'을 통과해서 각 시퀀스마다 크기가 512인 벡터로 변환한다.
2. Positional encoding
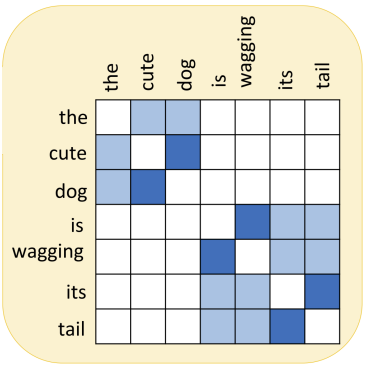
기존의 RNN은 모델 자체적으로 입력 시퀀스의 순서를 고려했지만, Transformer는 RNN이 제거되었으므로 위치 정보가 고려되지 않는다. 그래서 아래 그림처럼 입력 시퀀스의 순서를 바꿔도 attention의 결과가 바뀌지 않는다.

그래서 Transformer에서는 입력 시퀀스의 위치 정보를 제공하기 위해 positional encoding(PE)을 사용한다.
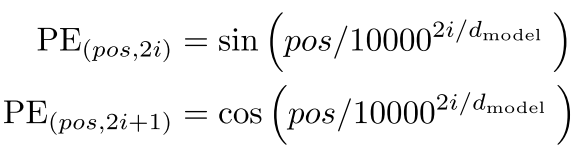
하지만 이 수식을 보면 직관적으로 와닿지 않는다. 그리고 위치 정보를 입력하기 위해 positional encoding을 하는건 알겠지만, 왜 이 방법을 쓰는지도 와닿지 않을 수 있다. 이 부분을 한 번 짚고 넘어가보자.
Positional encoding이 도입되기 전 다양한 시도가 있었다.
2.1. Positional encoding using index
단순히 입력 벡터의 인덱스를 PE로 사용하면, 입력의 길이가 길어지면서 값이 너무 커지는 문제가 발생하며, 네트워크를 학습하는데 지장이 생긴다.

2.2. Positional encoding using normalized index
2.1의 문제를 해결하기 위해 정규화된 인덱스를 PE로 사용해보았지만, 이번에는 입력의 길이가 길어지면서 주변 단어들 간의 상대적인 위치 차이가 애매해지는 문제가 생긴다.

2.3. Positional encoding using binary representation
입력 벡터의 인덱스를 2진수로 나타내어 임베딩 값에 합쳐봤지만, 이 방식은 낭비되는 bit가 많고, dot-product를 수행하는 attention에 적합하지 않다.
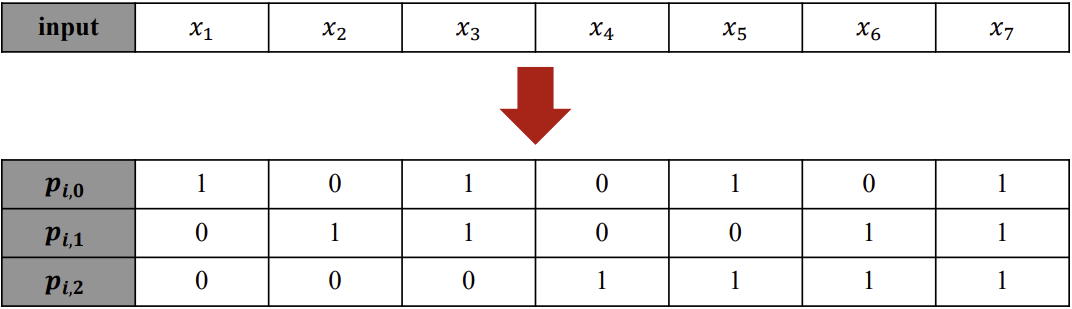
2.4. Sinsusoidal positional encoding
Sinusoidal PE는 임베딩 벡터와 같은 차원을 갖도록 위치값을 임베딩하여 입력값과 합친다.
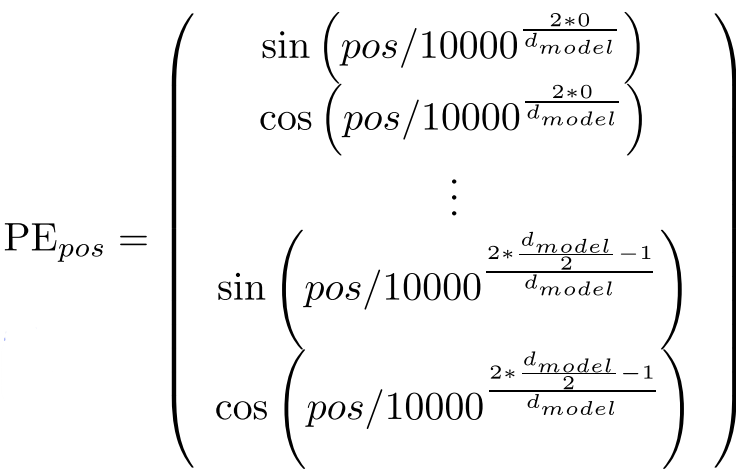
또한, 입력 시퀀스의 길이가 길어지면 문제가 있는 2.1, 2.2의 문제를 해결한다. 이는 수학적으로 증명이 가능하다.
만큼 차이나는 두 PE vector가 있을 때, 두 벡터의 dot-product를 하면 다음과 같다.

편의상 를 로 두겠다.
이는 결국 positional encoding을 적용하면 어떠한 위치든 한 시점에 대해 linear function으로 설명할 수 있게 된다.
이렇게 단어의 갯수만큼 사이즈 512인 PE 벡터를 만들어서 input embedding과 더해서 모델에 입력하게 된다.
3. Encoder
인코더는 positional encoding과 input embedding layer가 더해져서 입력된 후, 각 벡터 간의 self-attention을 수행하는 것이 핵심이다. 인코더의 구조는 아래 그림과 같다. 이 부분도 그림의 흐름에 따라 적어보겠다.
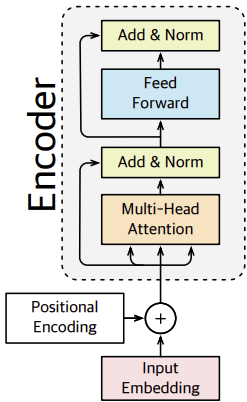
3.1. Multi-Head Attention
3.1.1. Self-Attention
이전 글에서 작성한 attention은 디코더의 target 시점에서 인코더의 각 시점과의 유사도를 계산하여, 입력 시퀀스의 어느 부분에 초점을 맞춰 출력 시퀀스에 반영할지 학습했다.
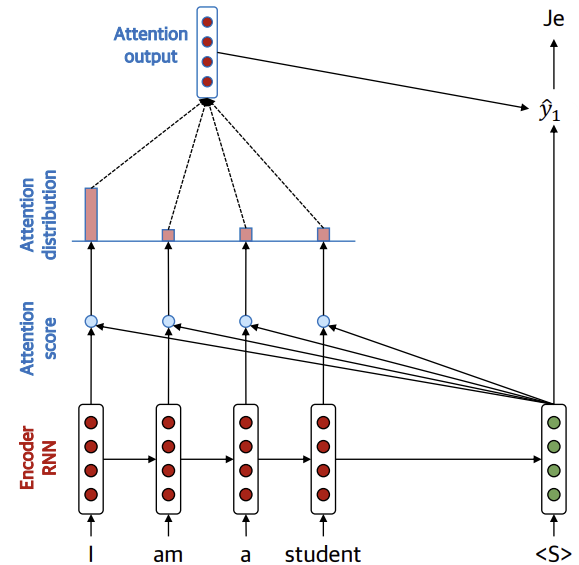
Self-attention은 인코더 내 각 입력 시퀀스 간의 관계를 비교하는 것이다.
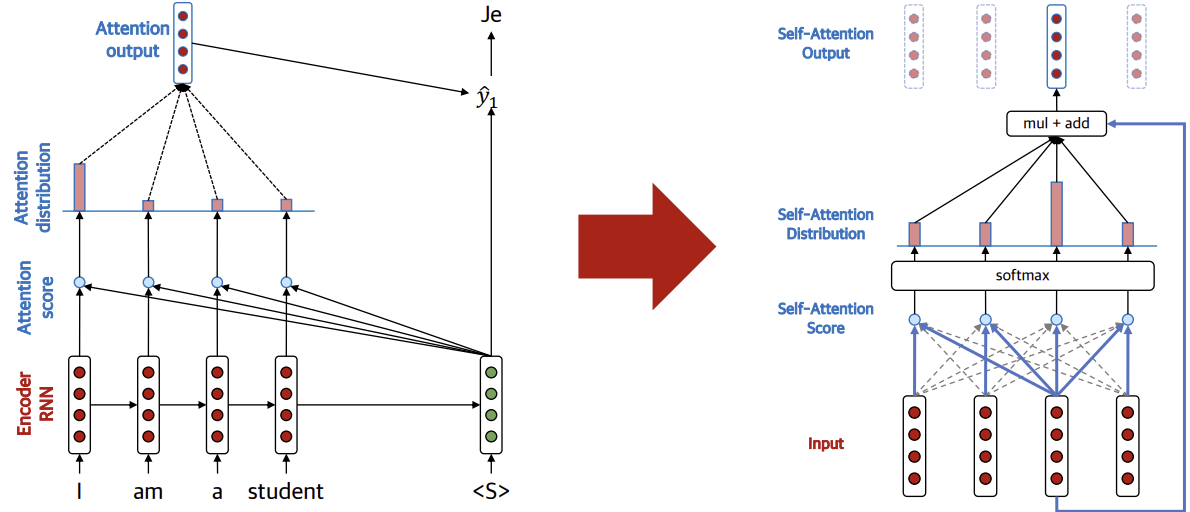
각 입력 시퀀스마다 key, value가 있고, 현재 집중할 부분을 query라 했을 때, attention을 구하는 수식은 다음과 같다.
, , 모두 크기로 임베딩된 벡터이므로, 의 크기는 그대로 유지하게 된다.
3.1.2. Scaled dot-product attention
Dot-product 시 입력값에 따라 값이 매우 크거나 작아질 수 있다. 이 값을 softmax를 그대로 취한 후 backpropagation을 하면 gradient가 모두 0으로 될 것이다. 이를 방지하기 위해 softmax를 취하기 전에 일정한 scalar 값으로 나누어 normalize를 한다. 여기서 scalar 값은 Q,K의 차원 수 의 제곱근을 보통 사용한다.
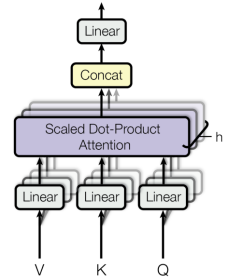
3.1.3. Multi-Head Attention
Multi-head self attention은 입력 벡터를 여러 개의 작은 벡터로 나누어, 서로 self-attention을 수행하며 입력 시퀀스 간의 관계와 패턴을 학습할 수 있도록 한다.

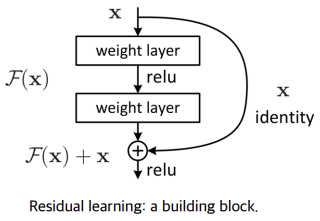
3.2. Residual Connection
Kaiming He의 'Deep Residual Learning for Image Recognition'에서 소개된 residual connection을 모델의 구조에 도입했다.
3.3. Add & Norm
Attention layer를 통과한 벡터 개와 입력 임베딩 벡터 개를 residual connection을 통해 더한 후, 안정적인 학습을 위해 분포를 갖도록 normalize를 한다.
3.4. Feed Forward
Attention layer의 출력에 non-linearity가 적용되지 않았으므로, 해당 layer를 추가하여 비선형성을 추가한다.
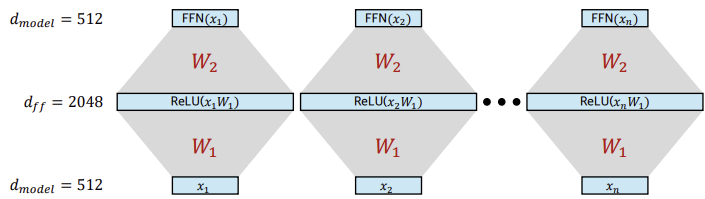
해당 layer를 통해 크기의 벡터를 크기로 늘렸다가 다시 크기의 벡터로 돌려놓는다.
4. Decoder
Output embedding은 다음 단어 예측을 위해 정답 문장을 한 칸씩 오른쪽으로 shift한 문장을 입력으로 받는다. 예를 들어, 인코더의 입력 시퀀스가 'I love you' 였다면, 디코더의 입력 시퀀스는 'start I love'가 된다.
그 다음은 인코더에서와 같이 각 시퀀스를 크기의 벡터로 임베딩하고, positional encoding과 함께 더해서 디코더에 입력하게 된다.
디코더의 구조는 다음과 같다.
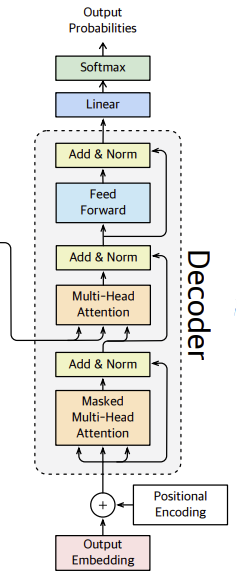
디코더의 모델 구조에서 masked multi-head attention을 제외한 나머지는 인코더 부분을 설명할 때 한 내용들이므로, 여기서는 masked multi-head attention만 짚어보겠다.
4.1. Masked Multi-Head Attention
일반적인 self-attention 방식은 미래의 출력들까지 고려하므로, 번 째 입력에 대한 출력을 구하고 싶다면 까지의 입력만을 고려해야 한다. 이를 위해 attention 계산 과정에서 n-1 시점 이후의 입력에 대해서는 masking을 적용한다.
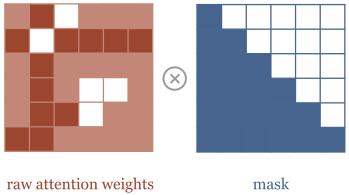
4.2. Masked Multi-Head Cross Attention
기존의 attention이라 생각하면 된다. 인코더의 시점까지의 입력 시퀀스와 디코더의 입력 시퀀스 간의 연산을 통해 인코더의 어떤 시점에 집중하여 출력값을 결정할 지 알아낸다.
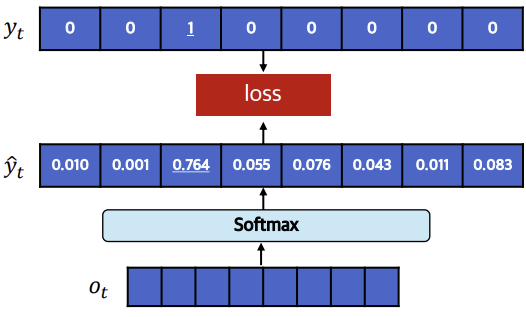
디코더를 통과해서 나온 의 벡터 (은 vocab size)를 linear layer에 통과하여 사이즈 인 벡터를 얻고, softmax를 통과하여 각 단어에 대한 확률 예측값을 구하게 된다. 이 예측 확률값들로 구성된 벡터와 one-hot encoding 된 실제 정답을 비교하여 모델 학습을 진행하게 된다.