이번 글은 Recurrent Neural Network (RNN)부터 Sequence 2 Sequence (Seq2Seq), Attention, Transformer까지의 전반적인 이론과 각 모델의 등장배경을 다뤄볼 예정이다.
최근에 멀티모달 관련 task를 맡아서 수행하게 되서 자연어처리 분야에 대한 다양한 논문도 공부할 예정이다.
오늘 다룰 글은 RNN이다.
1. RNN의 등장배경
시계열, 동영상, 텍스트, 등 다양한 시퀀스 데이터가 존재한다.

그리고 이러한 입력 시퀀스가 있을 때, 이전 시점을 통해 다음 시점을 예측할 수 있다. 이론 상 이를 무한히 반복해서 원하는 시점까지의 데이터를 예측할 수 있을 것이다.
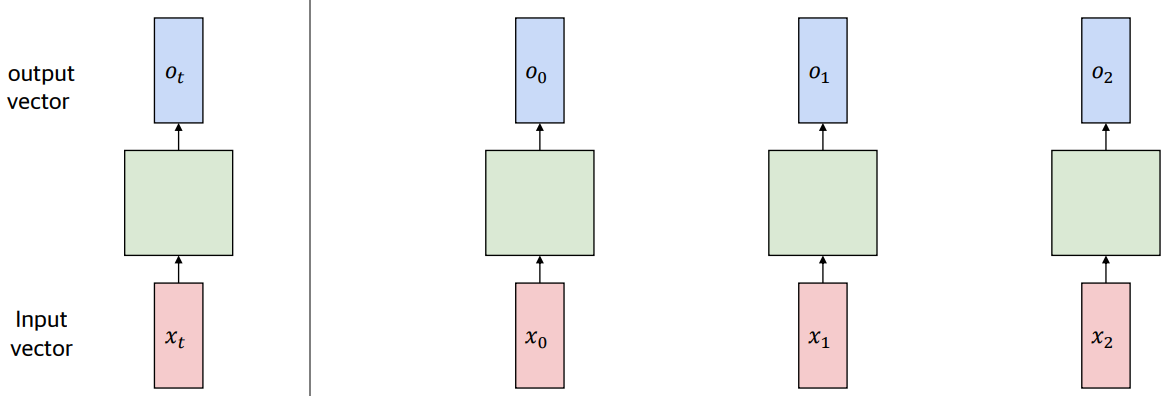
하지만 이렇게 단순히 한 시점에만 의존하여 출력을 계산하면, 이전 시점들과는 독립적이므로 부정확한 결과가 나올 확률이 크다.
그래서 등장한 것이 RNN이다. RNN은 시퀀스를 처리할 때마다 바뀌는 hidden state가 있는데, 이를 통해 이전 시점을 반영하여 다음 시점을 예측한다.
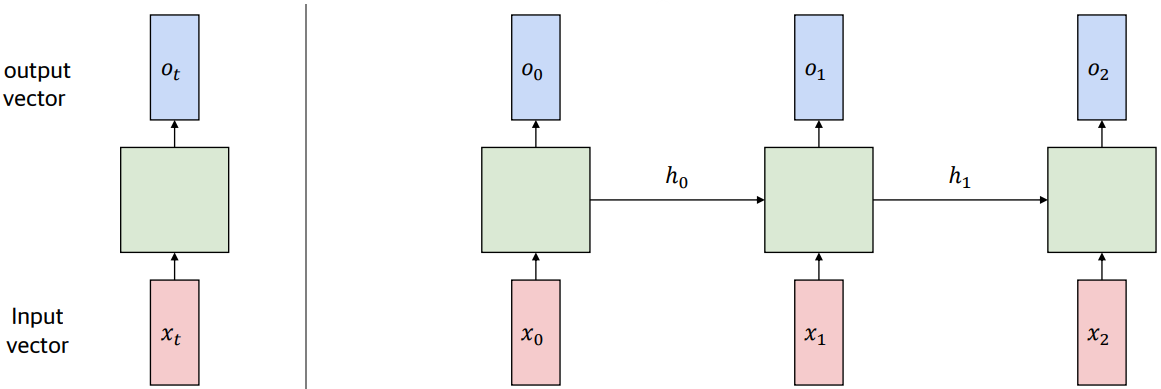
2. RNN의 연산과정
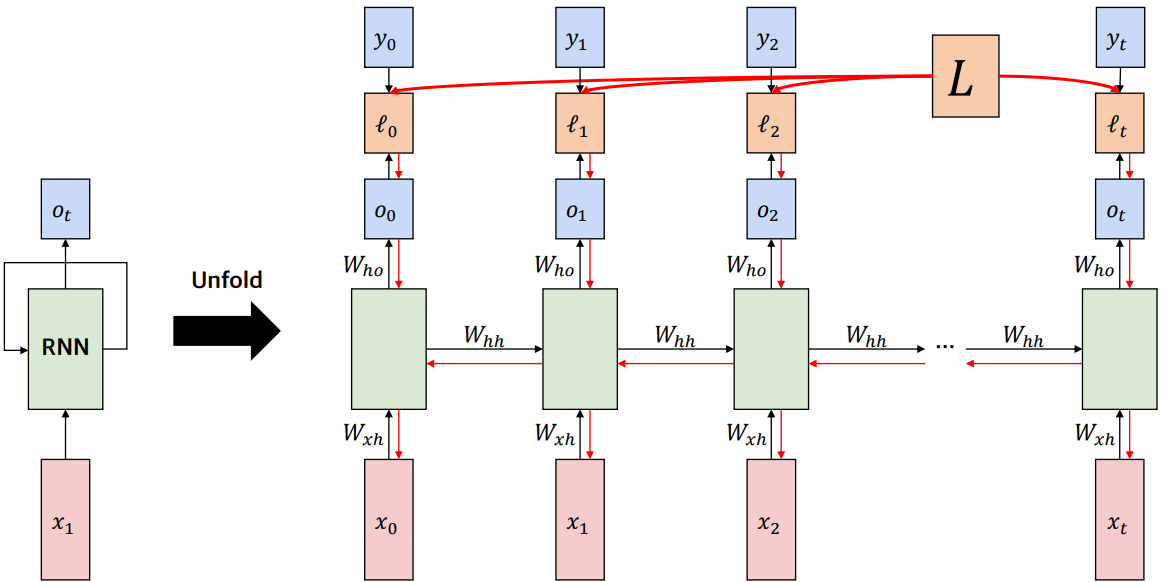
연산과정을 좀 더 자세히 나타내면 다음 그림과 같다.
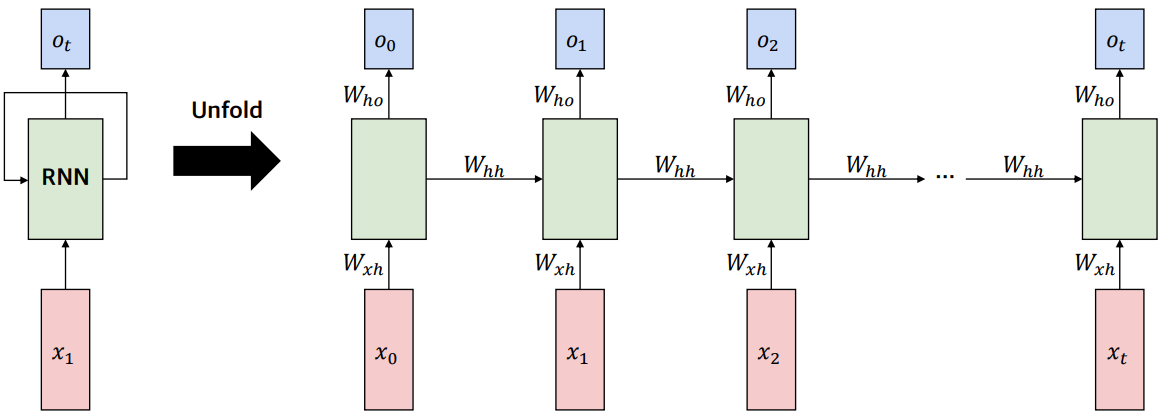
Ot=htWhoht=tanh(ht−1Whh+xtWxh)
여기서 xt, ot는 입력과 출력이고, Wxh, Whh, Who 는 0~1 사이의 랜덤 값으로 초기화된 weight matrix이다.
Weight matrix 각각의 shape은 (input 길이 × hidden 길이), (hidden 길이 × hidden 길이), (hidden 길이 × output 길이) 이다.
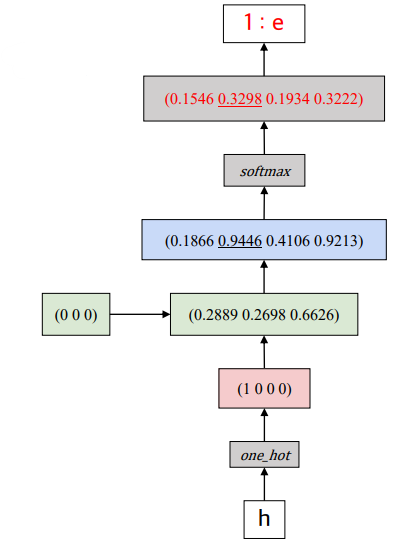
예시로 'h', 'e', 'l', 'l'이 입력으로 들어올 때 'o'를 예측하는 방법을 수식으로 풀어보자.
-
One-hot encoding
각 단어인 'h', 'e', 'l', 'o'를 벡터로 encoding한다.
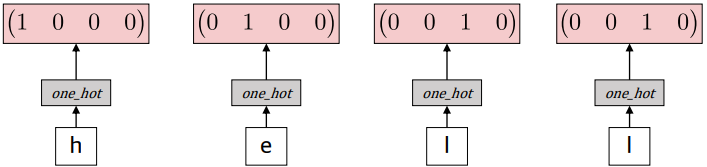
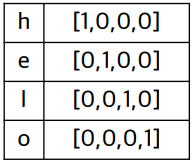
이 벡터들이 입력값인 xt가 된다.
-
Hidden state 계산
입력값 xt와 이전 시점의 hidden state ht−1, 그리고 다음 hidden state로 보내는데 사용되는 두 개의 weight matrix Wxh, Whh 를 이용해서 다음 hidden state를 계산할 수 있다.
ht=tanh(ht−1Whh+xtWxh)
이 식을 따르면 h1=tanh(h0Whh+x1Wxh) 가 된다.
x1은 (1,0,0,0)이고, 초기 은닉 상태값은 영행렬로 설정한다. h의 shape은 하이퍼파라미터이고, h0는 (0,0,0)이라 하겠다. 그럼 Whh, Wxh는 각각 (4×3), (3×3)이 될 것이다.
Whh=⎣⎢⎡0.31520.30080.97410.50830.60580.34190.94540.29990.9133⎦⎥⎤
Wxh=⎣⎢⎢⎢⎡0.29730.38690.55380.22060.27660.91700.56460.68010.79740.41250.50260.3880⎦⎥⎥⎥⎤
이 값들을 가지고 계산해보면,
h0Whh=[000]⎣⎢⎡0.31520.30080.97410.50830.60580.34190.94540.29990.9133⎦⎥⎤=[000]
x1Wxh=[1000]⎣⎢⎢⎢⎡0.29730.38690.55380.22060.27660.91700.56460.68010.79740.41250.50260.3880⎦⎥⎥⎥⎤=[0.29730.27660.7924]
tanh(h0Whh+x1Wxh)=tanh([0.29730.27660.7924])=[0.28990.26890.6626]
-
출력값 계산
출력값 o1은 다음과 같이 계산된다.
o1=h1Who
Who의 shape은 (3 × 4)가 될 것이다.
Who=⎣⎢⎡0.31890.02600.13200.62160.62300.90090.51640.01790.38730.75010.61230.8142⎦⎥⎤
h1Who=[0.28990.26980.6626]⎣⎢⎡0.31890.02600.13200.62160.62300.90090.51640.01790.38730.75010.61230.8142⎦⎥⎤=[0.18660.94460.41060.9213]
-
Softmax & Argmax
출력값 o1에 대해 softmax를 취해 각 인덱스에 대한 확률값을 구한다.
softmax(o1)=[0.15460.32980.19340.3222]
여기에 argmax를 적용하면 1번 인덱스 값인 'e'가 최종 output이 된다.
이후 다음 output을 계산할 때의 weight matrix는 동일한 weight matrix를 사용해서 다음 시점의 output을 구해나간다.
이 모든 과정을 시각화하면 다음과 같다.
이 과정을 모든 시점에 적용하여 마지막 시점까지의 출력값을 계산한 후, 각 시점에서의 출력값과 실제값의 차이를 모두 합하여 cross-entropy에 적용하여 얻은 loss값을 토대로 backpropagation을 진행해서 weight matrix를 업데이트 한다.
3. RNN의 한계
-
Short-term memory
RNN은 입력 시퀀스가 길어지면 앞 쪽 시점에 대한 정보를 잘 반영하지 못한다는 단점이 있다.
-
Gradient vanishing
RNN은 activation function으로 tanh를 사용하지만, 값이 거의 항상 1보다 작아서 기울기 소실 문제가 발생한다.
이 문제를 해결하기 위해 gate를 추가하여 선택적으로 정보를 기억할 수 있도록 개선하는 논문들도 등장하였다.
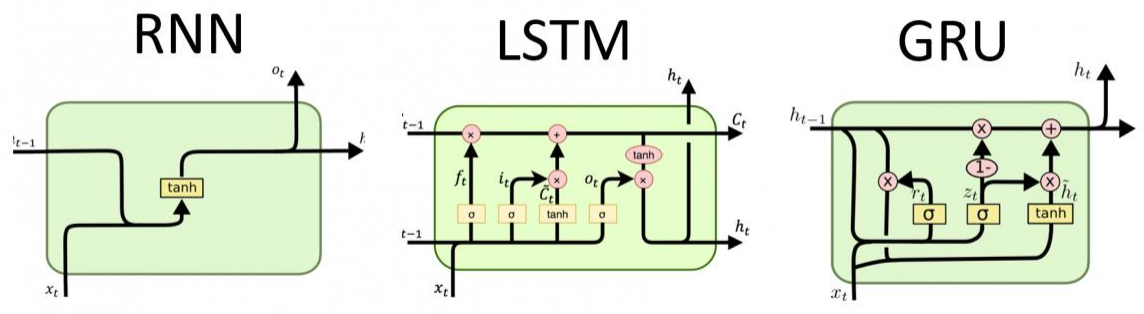
하지만 위에서 든 단어 예측 예시는 입력 시퀀스와 출력 시퀀스가 1:1 매핑이 되서 사용이 가능한거였고, 번역과 같은 task의 경우에는 입력 시퀀스와 출력 시퀀스의 길이가 다를 수 있어서 한계가 있다.
이 한계점들을 극복하기 위해 다음 글에서 소개할 Sequence 2 Sequence가 등장한다. 이에 대한 내용은 다음 게시글에 작성하도록 하겠다.
