
이 글은 ratsgo's blog와 Gyuseok Kim님 블로그를 참고해 작성되었습니다. 사진을 누르면 각 사진의 출처로 이동합니다.
1. HASH

-
많은 데이터들을 관리하기 위해 hash를 이용한다.
-
기존리스트에 데이터들을 저장하고 사용하는 경우에는 리스트의 내용들을 모두 돌며 찾고자하는 값을 찾아나가지만 해시함수를 이용한 해싱에서는 해당 데이터로 바로 매핑가능하기 때문에 사용한다.
-
이때 데이터만큼 테이블을 확보해 둔다면 충돌이 발생하지 않겠지만 메모리를 너무 많이 사용고, 테이블을 1개 확보해둔다면 모든 데이터를 한 곳에 넣기 때문에 해시를 이용하는 이유가 사라진다.
-
이를 고려한 적절한 사이즈의 테이블이 필요하다.
1) 용어정리
-
키: 매핑 전 원래 데이터 값
-
해시 값: 해시 함수를 거친 데이터 값
-
해시: 데이터를 효율적으로 관리하기 위해, 임의의 길이 데이터를 고정된 길이의 데이터로 매핑하는 것
-
해시함수: 해시를 가능하도록 하는 함수
-
해시충돌: 다른 키에 대하 값은 해시값을 얻게 되면 발생하는 것. (이는 many-to-one대응에 의해 발생)
2) 충돌해결
🔸chaining
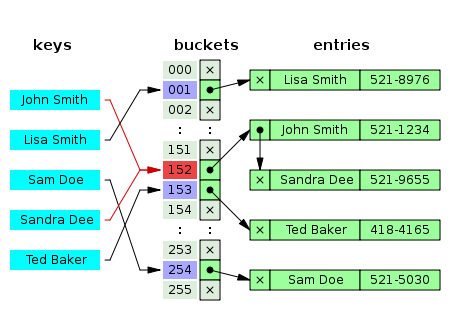
해싱 후 데이터를 저장하는 버킷에 들어가는 엔트리 수에 제한을 두지 않는 방법. 데이터가 미리 있다면 그 다음 노드로 데이터를 넣고 연결리스트로 연결해준다.
🔸open-addressing
해싱 후 할당해야 하는 버킷이 이미 차 있다면 그 다음 가장가까운 버킷에 값을 저장한다.
만약에 값을 삭제한다면 이후 버킷 탐색을 안할 우려가 있으므로 DEL을 넣어 원래있었음을 표현해준다.
🔸선형탐사
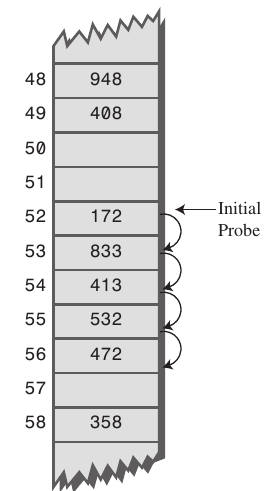
open-addressing과 유사하지만 한칸씩 이동하며 빈칸에 넣는것이 아닌 고정 폭만큼씩 이동하며 넣는다
🔸제곱탐사
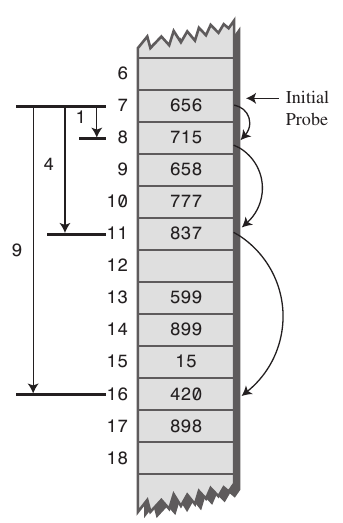
선형탐사와 유사하지만 빈칸을 찾는 폭이 제곱수로 늘어난다.
2. Hash Table
