
입력된 데이터들이 메모리 공간에서 연속적으로 저장되어있는 자료구조입니다. 이는 데이터를 효율적으로 관리하고 접근하기 위한 방법을 제공합니다.
특징
1) 고정 크기
Array는 메모리 관리를 위해 생성될 때 그 크기가 결정되고, 변경할 수 없습니다. 크기를 변결해야 할 경우엔, 크기가 동적으로 변할 수 있는 List, Linked List와 같은 다른 데이터 구조를 고려할 수 있습니다.
2) 동일한 데이터 타입
Array 에 저장된 모든 요소는 동일한 타입을 가져야 합니다. 이는 타입 안정성을 보장하고 메모리 사용을 최적화합니다.
3) Index 접근
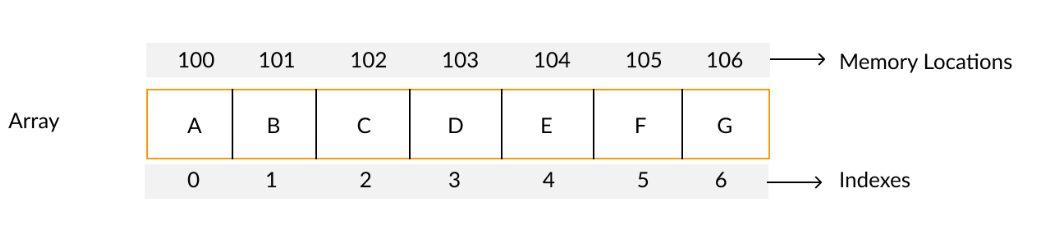
Array의 요소는 Index를 통해 접근하여 데이터를 빠르게 검색 및 수정이 가능하도록 합니다.
💡 Index?
Index는 array 내에서 각 요소의 위치를 나타내는 숫자로, 데이터 접근의 효율성을 극대화합니다.
Index는 0부터 시작하며, 사진 속 0번 Index는 ‘A’를, 1번 Index는 ‘B’를 의미합니다. (일부 환경에서 Index가 0번부터 시작할 수 있습니다)
4) 순차적 메모리 할당
Array의 요소들은 위의 사진처럼 메모리 상에서 연속적으로 위치합니다. 따라서 데이터를 순차적으로 처리할 때 높은 성능을 제공합니다.
5) 다차원 Array
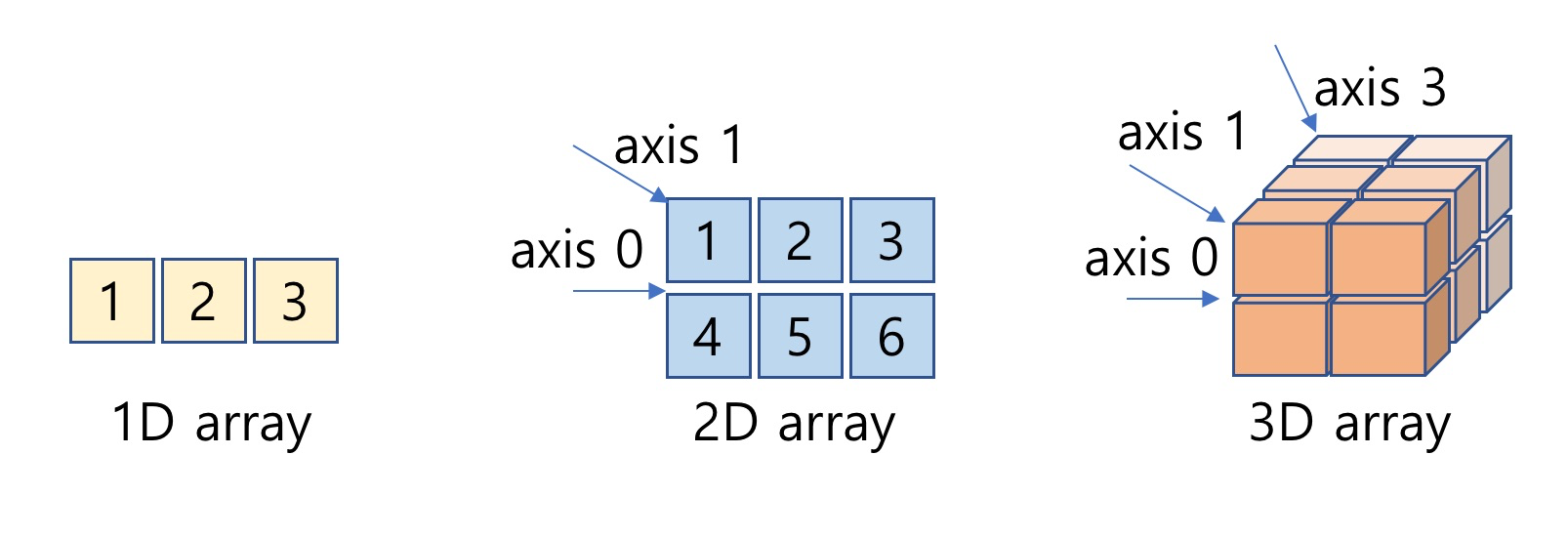
Array는 다차원으로도 생성이 가능합니다. 2차원 Array 는 행렬을, 3차원 Array는 3D 공간 속 점들을 나타내는데 사용할 수 있습니다.
6) 데이터 구조 기반
Array는 다른 복잡한 데이터 구조들의 기반이 됩니다. 예를 들어, 스택, 큐, 힙, 해시 테이블 등 많은 추상적 데이터 타입과 알고리즘은 내부적으로 배열을 사용하여 구현됩니다.
Python array의 시간 복잡도
💡 시간복잡도
알고리즘을 실행할 때 필요한 시간이 입력의 크기에 따라 어떻게 변하는지를 나타내는 척도입니다.
시간 복잡도를 표현할 때는 "빅 오 표기법(Big O notation)"을 사용합니다.
시간 복잡도를 통해 코드가 얼마나 효율적으로 작동할지 예측할 수 있으며, 다양한 입력 크기에 대한 알고리즘의 성능을 비교하고 최적의 선택을 할 수 있습니다.
💡 O(1) - 상수 시간(Constant Time)
입력 데이터의 크기와 상관없이, 알고리즘이 수행되는 시간이 항상 일정함을 의미합니다. 쉽게 말해 입력 데이터의 크기가 증가해도 알고리즘을 실행하는 데 필요한 시간은 변하지 않는다는 것입니다.
💡 O(n) - 선형 시간(Linear Time)
알고리즘을 완료하는 데 걸리는 시간이 입력 데이터의 크기에 비례하여 증가함을 의미합니다. 여기서n은 입력 데이터의 요소 수를 나타냅니다. 즉, 입력 데이터의 크기가 두 배가 되면, 알고리즘의 실행 시간도 대략 두 배로 증가합니다.
1) Access : 접근
- 시간복잡도 : O(1)
- Array에서 특정 인덱스의 요소에 접근하는 연산은 O(1)을 가집니다. 이는 인덱스를 알고 있다면, 그 요소를 바로 읽어올 수 있음을 의미합니다.
import array
arr = array.array('i', [1,2,3,4,5])
# 특정 인덱스의 요소에 접근
print(arr[1]) # 출력 : 22) Insertion : 삽입
- 시간 복잡도: O(n)
- 특정 위치에 요소를 삽입하는 경우, 해당 위치 이후의 모든 요소를 한 칸씩 뒤로 이동해야 하므로, 최악의 경우 전체 배열의 크기에 비례하는 시간이 걸립니다.
import array
arr = array.array('i', [1,2,3,4,5])
# 배열의 시작 부분에 요소 insert
arr.insert(0,0) # 0번째에 0을 insert -> 배열의 모든 요소가 한 칸씩 뒤로 이동
print(arr) # 출력: array('i', [0, 1, 2, 3, 4, 5])3) Deletion : 삭제
- 시간 복잡도: O(n)
- 배열에서 요소를 삭제하는 경우도 삽입과 유사하게, 삭제된 요소 이후의 모든 요소를 한 칸씩 앞으로 이동해야 하므로, 시간 복잡도는 O(n)입니다.
import array
arr = array.array('i', [1,2,3,4,5])
# 배열의 특정 요소 삭제
arr.remove(3) # 3이라는 값을 가진 요소 삭제
print(arr) # 출력: array('i', [1, 2, 4, 5])4) Search : 검색
- 시간 복잡도: O(n)
- 특정 값을 가진 요소를 찾기 위해서는 최악의 경우 배열의 모든 요소를 확인해야 하므로, 선형 검색의 시간 복잡도는 O(n)입니다.
import array
arr = array.array('i', [1,2,3,4,5])
# 배열에서 값 '4' 검색
print(4 in arr) # 출력: True5) Append : 추가
- 시간 복잡도: O(1) (평균적으로)
- 배열의 끝에 요소를 추가하는 것은 대부분의 경우 상수 시간에 이루어집니다. 하지만, 배열의 용량이 가득 차서 새로운 메모리를 할당해야 하는 경우에는 더 많은 시간이 소요될 수 있습니다.
import array
arr = array.array('i', [1,2,3,4,5])
# 배열의 끝에 append
arr.append(6)
print(arr) # 출력: [1,2,3,4,5,6]Python list vs Python array
이미 Python을 배우신 분들은 Array의 특징을 읽을 후 list를 떠올리며 고개를 갸우뚱하시는 분들도 계실 겁니다. 이 두가지는 모두 데이터 컬렉션을 저장하기 위한 데이터 구조이지만 차이점이 있습니다.
(여기서 언급하는 Array는 Python의 array 모듈에 의해 제공되는 array 타입을 말하며, NumPy 라이브러리의 ndarray와는 다릅니다.)
한 눈에 보기 쉽게 표로 정리하겠습니다.
| 특성 | List | Array |
|---|---|---|
| 데이터 타입 | 서로 다른 데이터 타입의 요소를 저장할 수 있음 | 모든 요소가 동일한 데이터 타입이어야 함 |
| 메모리 사용 | 상대적으로 더 많은 메모리 사용 | 적은 메모리 사용 (동일한 타입의 요소로 인해) |
| 연산 지원 | 다양한 메소드와 연산 지원 (예: append(), extend(), pop()) | 제한적 (주로 기본적인 추가, 삭제, 접근 연산) |
| 사용 사례 | 다양한 타입의 요소를 포함하는 경우, 유연성이 필요할 때 사용 | 대량의 숫자 데이터 처리, 메모리 효율성이 중요할 때 사용 |
| 속도 | 다양한 타입의 데이터 처리로 인해 상대적으로 느릴 수 있음 | 동일한 타입의 데이터 처리로 인해 빠를 수 있음 |
| 메모리 효율성 | 낮음 | 높음 |
| 사용 예 | 일반적인 프로그래밍 작업, 다형성이 필요한 컬렉션 | 숫자 데이터의 고성능 배열, 파일 데이터 처리 |
Python array vs Numpy ndarray
위에서 언급한 array 모듈에 의해 제공되는 array 타입과 NumPy 라이브러리의 ndarray의 차이점입니다.
| 특성 | array.array | NumPy ndarray |
|---|---|---|
| 데이터 타입 | 단일 데이터 타입만 지원 | 다양한 데이터 타입 지원, 한 배열 내에서는 같은 타입 |
| 차원 | 주로 1차원 배열에 사용 | 다차원 배열 지원 |
| 메모리 효율성 | 상대적으로 높음 (단일 타입) | 크기가 큰 데이터에 대해 최적화됨 |
| 성능 | 단순 숫자 데이터 배열에 대해 효율적 | 대량의 데이터 연산에 대해 매우 빠르고 효율적 |
| 기능성 | 기본적인 배열 연산만 지원 | 복잡한 수치 연산, 통계, 선형대수 등 고급 기능 지원 |
| 용도 | 단순한 숫자 데이터 시퀀스 처리에 적합 | 과학 계산, 데이터 분석, 기계 학습 등에 필수 |
| 인덱싱 및 슬라이싱 | 기본적인 지원 | 매우 고급 인덱싱 및 슬라이싱 기능 지원 |
| 라이브러리 필요성 | Python 표준 라이브러리의 일부 | NumPy 설치 필요 |
| 사용 예 | 바이너리 데이터 처리, 간단한 숫자 배열 저장 | 이미지 처리, 고차원 데이터 분석, 복잡한 수치 계산 |
지금까지 Array에 대해 알아보았습니다.
특징에서 언급한 바와 같이, Array는 복잡한 데이터들의 구조가 되기 때문에 꼭! 이해하고 넘어가는 것이 좋은데요, 제 글이 이해에 도움이 되었으면 좋겠습니다.
오늘 포스팅 여기서 마치겠습니다.
