
저는 현재 리뷰를 가지고 키워드를 추출하고, 요약을 하는 업무를 하고있는데, 정규표현식을 쓸 일이 은근히 많습니다.
그럼에도 불구하고 항상 헷갈리던 개념인지라,
이번 포스팅에서는 정규 표현식에 대해 작성하려 합니다.
개념
정규표현식이란, re 모듈을 사용하며,
일치시키려는 가능한 문자열 집합에 대한 규칙을 지정하여, 문자열을 수정하거나 여러 방법을 분할할 수 있습니다.
주요 함수
-
re.search
문자열에서 패턴과 첫 번째로 일치하는 부분을 검색합니다. 일치하는 경우 매치 객체를 반환합니다.
예시: "Hello World"에서 "World" 검색import re match = re.search("World", "Hello World") print(match.group()) # 출력: 'World' -
re.match
문자열의 시작부터 패턴과 일치하는지 검사합니다.match = re.match("Hello", "Hello World") print(match.group()) # 출력: 'Hello' -
re.fullmatch
문자열이 패턴과 완전히 일치하는지 검사합니다.match = re.fullmatch("Hello", "Hello") print(match.group()) # 출력: 'Hello' -
re.findall
문자열에서 패턴과 일치하는 모든 부분을 찾아 리스트로 반환합니다.
예시: "hello 123 hi 34"에서 숫자 찾기numbers = re.findall("\d+", "hello 123 hi 34") print(numbers) # 출력: ['123', '34'] -
re.finditer
일치하는 모든 항목에 대한 이터레이터를 반환합니다.
예시: "hello 123 hi 34"에서 숫자 반복 검색for match in re.finditer("\d+", "hello 123 hi 34"): print(match.group()) # 출력: # 123 # 34 -
re.sub
문자열에서 패턴과 일치하는 부분을 다른 문자열로 교체합니다.
예시: "hello 123"에서 숫자를 "456"으로 교체replaced = re.sub("\d+", "456", "hello 123") print(replaced) # 출력: 'hello 456' -
re.split
패턴을 구분자로 사용하여 문자열을 분할합니다.
예시: "hello,world,hi"를 쉼표로 분할parts = re.split(",", "hello,world,hi") print(parts) # 출력: ['hello', 'world', 'hi']
패턴 구문
-
.(점) : 줄바꿈 문자를 제외한 모든 단일 문자와 일치합니다.
예시: "a1b2c3"에서 첫 번째 문자와 일치match = re.search(".", "a1b2c3") print(match.group()) # 출력: 'a' -
^: 문자열의 시작과 일치합니다.
예시: "Hello"가 시작 부분인지 확인match = re.search("^Hello", "Hello World") print(match.group()) # 출력: 'Hello' -
$: 문자열의 끝과 일치합니다.
예시: "World"가 끝 부분인지 확인match = re.search("World$", "Hello World") print(match.group()) # 출력: 'World' -
*: 바로 앞의 문자가 0회 이상 반복되는 부분과 일치합니다.
예시: "a*"는 "aaa"에서 연속된 'a'를 찾습니다.match = re.search("a*", "aaa") print(match.group()) # 출력: 'aaa' -
+: 바로 앞의 문자가 1회 이상 반복되는 부분과 일치합니다.
예시: "a+"는 "aaa"에서 연속된 'a'를 찾습니다.match = re.search("a+", "aaa") print(match.group()) # 출력: 'aaa' -
?:바로 앞의 문자가 0회 또는 1회 등장하는 부분과 일치합니다.
예시: "a?"는 "aaa"에서 첫 번째 'a'를 찾습니다.match = re.search("a?", "aaa") print(match.group()) # 출력: 'a'
Flags
정규 표현식에서 사용하는 flags는 검색 또는 다른 정규 표현식 작업을 수행할 때 특정 행동을 수정하거나 추가하는 역할을 합니다.
이 또한 각각의 기능과 예시를 설명하겠습니다.
-
re.IGNORECASE (re.I)
대소문자 구분 없이 패턴 매칭을 수행합니다.
예시: "Hello world"에서 "HELLO"를 대소문자 구분 없이 찾기match = re.search("HELLO", "Hello world", re.IGNORECASE) print(match.group()) # 출력: 'Hello' -
re.MULTILINE (re.M)
문자열이 여러 줄일 때, ^와 $가 각 줄의 시작과 끝에도 적용됩니다.
예시: 여러 줄의 문자열에서 각 줄의 시작에 있는 "start" 찾기text = "start line 1\nstart line 2\nend line" matches = re.findall("^start", text, re.MULTILINE) print(matches) # 출력: ['start', 'start'] -
re.DOTALL (re.S)
. (점)이 줄바꿈 문자를 포함하여 모든 문자와 일치하도록 합니다.
예시: 줄바꿈을 포함한 문자열에서 "a.b" 패턴과 일치하는 부분 찾기text = "a\nb" match = re.search("a.b", text, re.DOTALL) print(match.group()) # 출력: 'a\nb' -
re.ASCII (re.A)
\w, \W, \b, \B, \d, \D, \s, \S가 ASCII 문자에만 적용됩니다. 기본적으로 이들은 유니코드 문자까지 포함하여 매치합니다.
예시: ASCII가 아닌 문자열에서 숫자를 찾기text = "number: 55" matches = re.findall("\d", text) # 유니코드 숫자도 찾음 matches_ascii = re.findall("\d", text, re.ASCII) # ASCII 숫자만 찾음 print(matches) # 출력: ['5', '5'] print(matches_ascii) # 출력: [] -
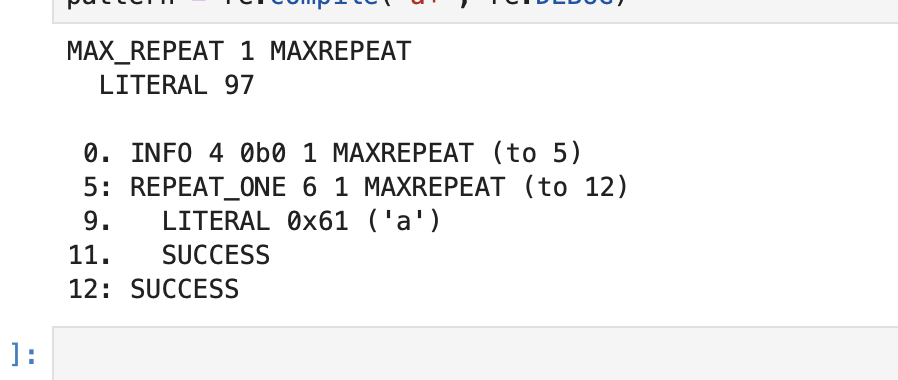
re.DEBUG
패턴 컴파일 시 디버그 정보를 출력합니다. 이는 패턴이 어떻게 해석되고 실행되는지 이해하는 데 도움이 됩니다.
예시: 디버그 정보와 함께 패턴 컴파일pattern = re.compile("a+", re.DEBUG)아래의 사진처럼, 코드 실행 시 내부적으로 어떻게 처리가 되는 지에 대한 정보를 출력합니다.
사용 사례
정규 표현식 사용 사례를 알려드리겠습니다.
1. 웹사이트 URL 추출
이 작업은 크롤링이나 데이터 마이닝 시 많이 쓰이는 작업으로, 텍스트에서 URL을 추출해내는 작업입니다.
import re
text = "Visit our website at https://www.example.com or http://www.another-site.net for more info."
# URL 패턴 정의
url_pattern = r"http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+"
urls = re.findall(url_pattern, text)
print(urls) # 출력: ['https://www.example.com', 'http://www.another-site.net']2. 데이터 정제 및 포맷팅
이 작업은 정규 표현식을 사용하여 불필요한 공백, 특수 문자를 제거하거나 데이터 포맷을 통일하는 작업인데요,
제가 업무에서 가장 많이 쓰는 작업입니다.
import re
data = " Name: John Doe ; Age: 30; Occupation: Engineer "
# 불필요한 공백과 특수 문자 제거
cleaned_data = re.sub(r"\s*;\s*|\s{2,}", ", ", data.strip())
print(cleaned_data) # 출력: 'Name: John Doe, Age: 30, Occupation: Engineer'정규 표현식은 이 외에도
로그 파일에서 특정 정보를 추출하거나,
이메일 혹은 전화번호 유효성 검사,
데이터 전처리 시 문자열 처리 작업에서 유용하게 활용되고 있습니다.
이 많은 함수들을 외우려고 하지 말고 하나씩 따라하면서 익숙해지려는 노력을 더 하셨으면 좋겠다는 생각이 듭니다.
그럼 안뇽
