1. 리뷰
1.1. 특징
- 물체에 대한 node-edge graph를 그림
- node는 물체
- 물체애 대한 semantic 설명 + semantic feature vector 을 함께 저장 (+위치)
- edge는 가까운 물체간 관계
- 연결 뿐만 아니라, 두 물체간 상관관계를 text로 함께 저장.
- 경량화된 지도 포멧 + 풍부한 정보를 담고 있어,
- 지도를 text 형식으로 변환하여 LLM, VLM 등에 넣어줄 수 있음.
- 내가 어떤 text query를 명령했을 때
- 해당 text query와 유사도가 가장 높은 물체를 찾아줄 수 있음
1.2. Replica-Dataset
0. abstract
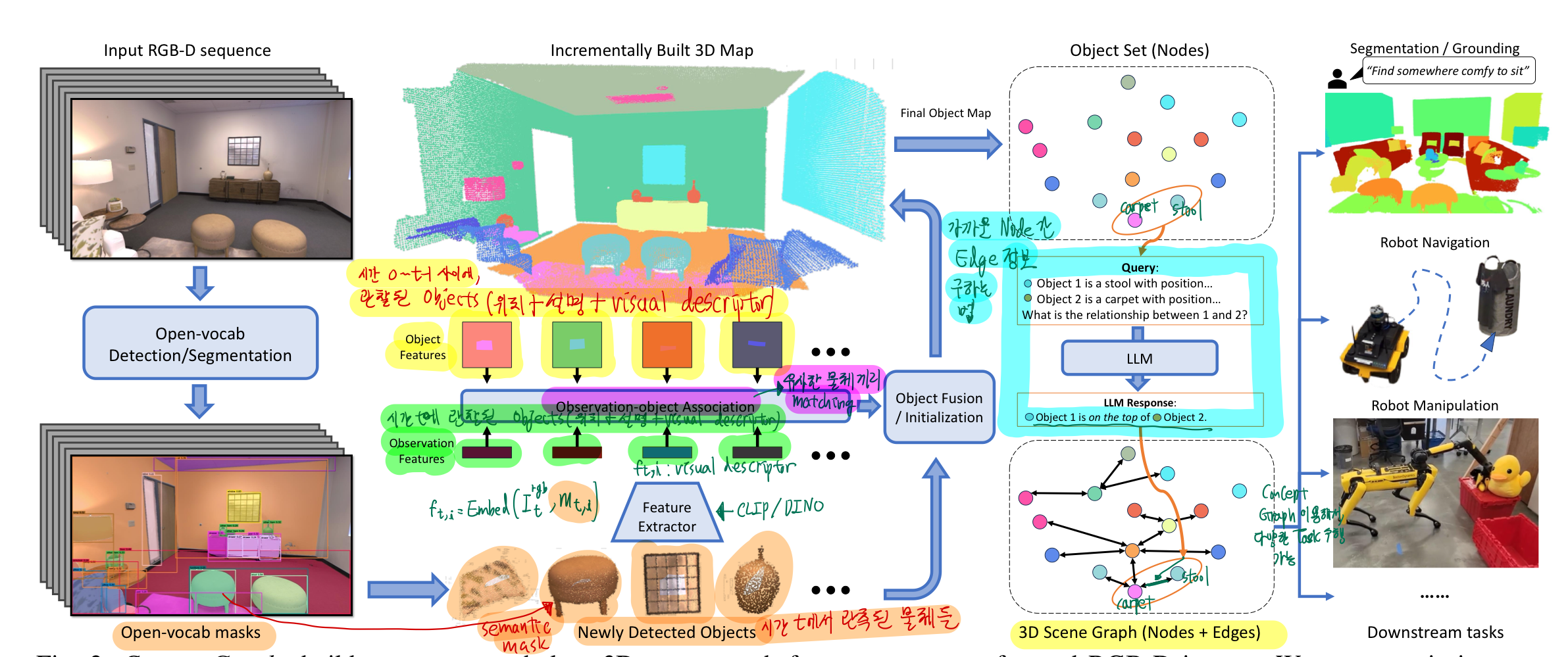
- ConceptGraph? (위 그림의 오른쪽 아래 graph)
- RGB-D + pose 정보들을 기반으로 생성함:
open-vocabulary 3D scene graph - 노드: 물체
- 예: 의자, 책상
- 물체에 대한 위치 정보 담음
- 물체에 대한 설명 text도 저장
- 물체에 대한 semantic feature vector도 저장
- 엣지: 가까운 물체 간의 관계
- 가까운 물체 간 관계를 text로 저장
- 예: 의자(node)가 카페트(node) 위에 있어요!
- 가까운 물체 간 관계를 text로 저장
- RGB-D + pose 정보들을 기반으로 생성함:
- 구축하는 방법 초간단 설명
- RGB image에
instance segmentation을 적용하여 -> semantic feature vectors를 추출한 후 - depth camera와 pose 정보를 이용해서, 이를 3D pointcloud에 투영시킴
- RGB image에
- 시간이 지나면서, 여러 뷰에서 찍은 사진과 데이터들이 점진적으로 융합되면서, 3D objects (Node) 가 생성됨
1. Related work
- 과거 3D semantic representation 들의 문제점
- 모든 voxel마다 semantic feature vectors를 저장
- 확장성이 떨어지는 방법 (지도가 커질수록, 저장해야할 정보들이 너무 늘어남)
- 물체 간 관계를 고려하지 않음
- 이 관계 정보들을 포함해야, downstream task planning에 유용함
- 모든 voxel마다 semantic feature vectors를 저장
- 논문에서 제안하는 ConceptGraph ?
- 3D scene에 대한 open-vocabulary graph-structured 표현
- 새로운 semantic classes에 일반화가 잘 됩니다. (한번 scan하면, 환경이 변하지 않는 이상, 데이터를 추가로 수집할 필요 X)
-
-
ConceptGraph 란?
open-vocabulary 3D scene graph- 위 그림의, 노드(노란색, 초록색, 파란색 동그라미)-엣지(빨간색) 그래프를 의미함 (잘 안보이니 잘 찾아보세요!)
-
물체 중심의 ConceptGraph는
- 유지 보수가 쉽다
- 확장성이 좋다.
- 가까운 node간 관계 정보를 제공
-
scene graph 표현:
- 노드와 엣지를 text 형태로 변환 가능하여 ,LLM에 쉽게 input으로 줄 수 있다.
- 그래서, 복잡한 scene 질문(task)에 대답할 수 있다.
- 로봇 주변의 물체들에 대해, 유용한 정보들을 제공할 수 있다.
- traversability : 이 물체는 밀고 지나가도 되나요? 네!
- utility: 이 물체는 잡을 수 있는 물체인가요? 네!
2. Method
- ConceptGraph의 node 만드는 법
요약 설명으로 시작 하겠다! - 특정 시간 t 에서 찍은 RGBD 카메라로 얻은 RGB image에
- class-agnostic segmentation model을 써서
object candidates mask를 얻고, object candidates mask에 Depth image와 pose 정보를 결합해 3D 공간에 투영한 후,- 기존(0 ~ t-1 시간)에 3D 공간에 구해놨던
object candidates와유사도측정을 통해 겹치는게 있는지 체크하고,- 겹치면 물체(그래프의 node) 통합, 아니면 새로운 물체(node)로 초기화
- class-agnostic segmentation model을 써서
- 이런 방식으로, 3D scene graph의 node(object)를 생성
- ConceptGraph의 node 에, 물체에 대한 의미론적 설명도 함께 기록한다!
- 3D 공간의 각 노드(물체)를 형성하는데 사용되었던 카메라 이미지(RGB)들을
- (
"describe the central object in the image"의 text prompt와 함꼐) LVM에 통과시켜서, - object node에 대한 설명을 확보 (image captioning)
- (
- ConceptGraph의 Edge 에는 어떤 정보를 저장하니?
- 일단 거리상으로 근접한 node(물체)들만 연결합니다.
- 연결된 Node(물체)들끼리의 관계를 추론하여, 그 관계를 text로 저장
- 인접한 node들끼리의 관계를 추론하여
그래프 edge에 반영하기 위해LLM을 사용 (스포임, 아래에 자세히 설명 나옴)
2.A. Object-based 3D Mapping
2.A.1 Object-centric 3D representation
- RGBD Observation의 sequence를 아래와 같이 정의
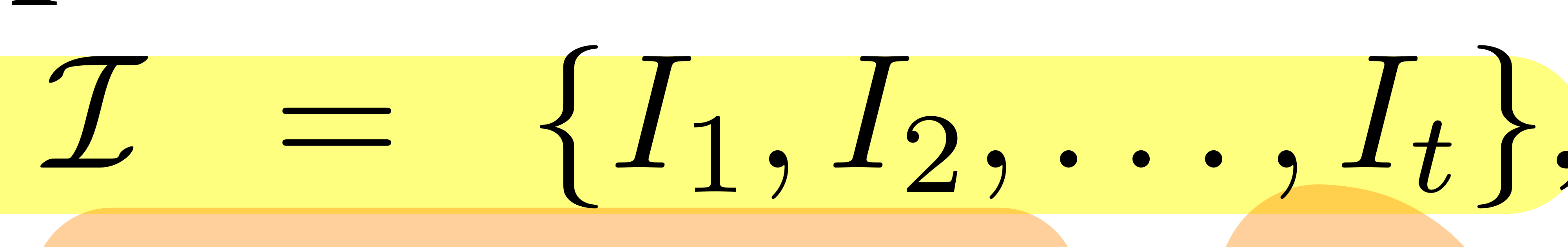
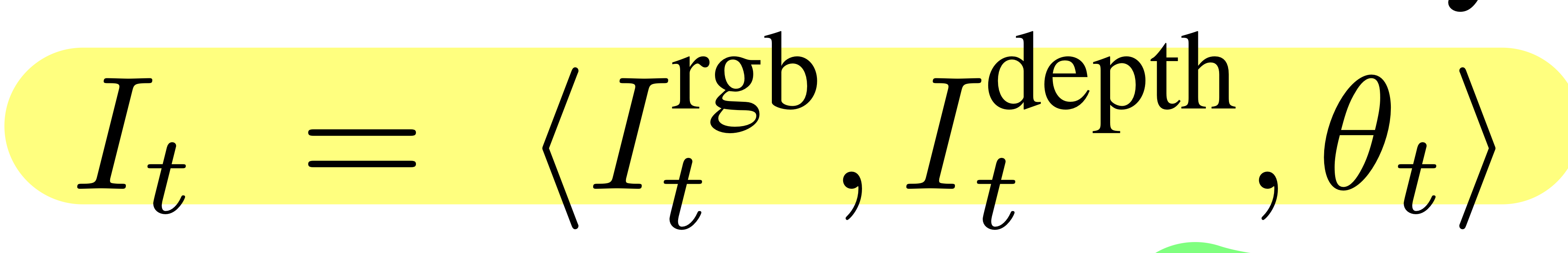
- 여기서 theta: pose
3D scene graph (Mt)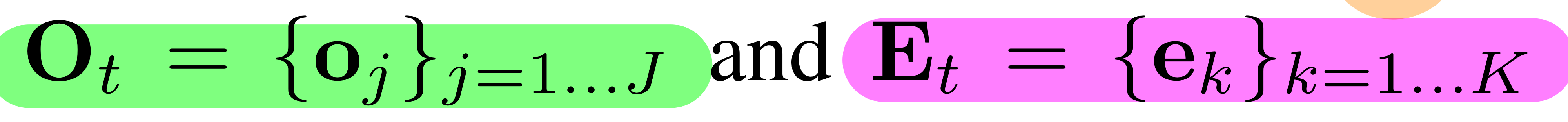
- Set of objects (그래프 nodes를 의미)
- 각 물체 Oj =
3D point clouds Poj+semantic feature vector foj
- 시간 t에서 segmentation을 수행한 후 얻은
object 후보군을object set Ot_1들과 비교해서, (어떻게 비교하는지는 아래 글에 자세히 나옴)- 겹치는 것이 있으면: Ot_1에 있었던 물체에 합치거나
- 겹치는 것이 없으면: 새로운 물체로 등록
- 각 물체 Oj =
- Set of Edges (Et)
- 인접한 노드(물체)들끼리의 관계 정보를 담음
- Set of objects (그래프 nodes를 의미)
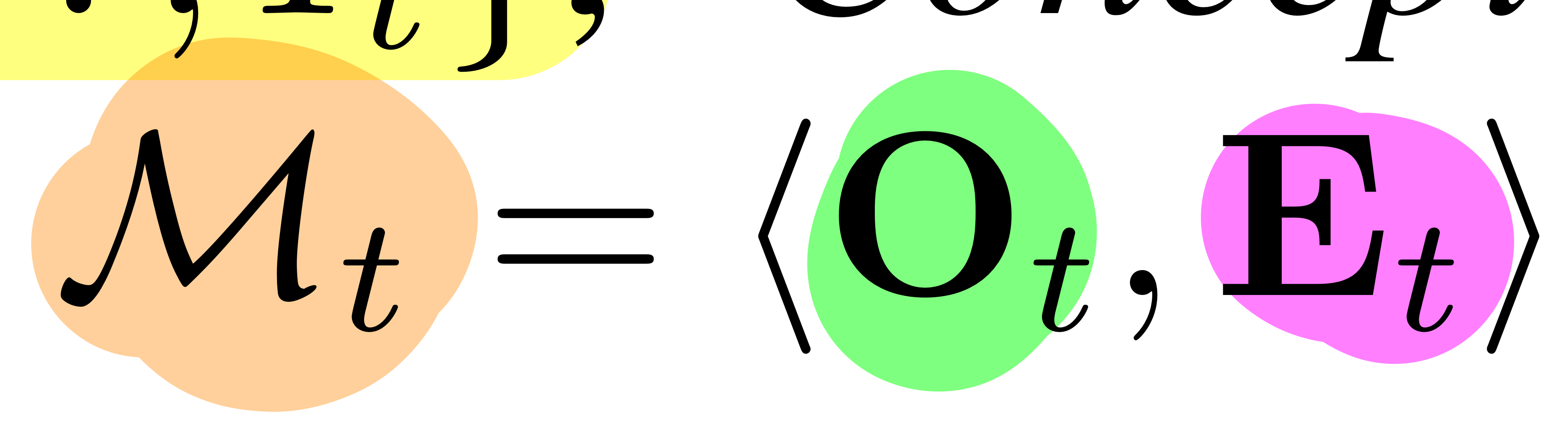
2.A.2. Class-agnostic 2D Segmentation
candidate object masks={mt,i}i=1...M = Seg(I_t^rgb)- 시간 t일 때,
- RGB에 segmentation network를 통과시켜, 여러 mask를 얻는다는 간단한 수식
- 시간 t일 때,
ft,i = Embed(I_t^rgb, mt,i)- 시간 t일 때,
- 위에서 얻은 특정 mask 와 RGB image를, 딥러닝 네트워크(visual feature extractor, 예 CLIP / DINO)를 통과시켜
- feature vector(
visual descriptor, ft,i) 를 구한다는 수식
- feature vector(
- unit-normalized
semantic feature vector로 최종적 도출- 클래스 종류를 명시적으로 담는게 아니라,
- 클래스 정보를 도출할 수 있는 semantic feature vector을 도출
- 위에서 얻은 특정 mask 와 RGB image를, 딥러닝 네트워크(visual feature extractor, 예 CLIP / DINO)를 통과시켜
- 시간 t일 때,
candidate object masks는 DBSCAN clustering을 이용하여 노이즈가 제거된 후, 3D 공간에 투영됩니다. (3D world 좌표계로 좌표변환 한다는 뜻)- 결국 우리는 object 1개에 대해, 아래 2개를 얻음
- pointclouds pt,i
- unit-normalized semantic feature vector ft,i
- 결국 우리는 object 1개에 대해, 아래 2개를 얻음
2.A.3. Object Association
- 시간 t에서 새로 생기는 물체 후보군마다, 기존 모든 objects(node)와의
semantic & geometric 유사도를 계산하여, 유사도가 δ_sim(1.1)을 넘는지 확인함- 넘으면 fusion
- 아니면, 새로운 노드 생성
- 거리도 가까워야 하고, semantic 의미도 유사해야 같은 물체라고 인정!
geometric 유사도 측정
- nnration: nearest neighbor ratio
- 새로운 pointclouds(Pt,i) 의 각 점의 nearest neighbor(δnn 거리 기준 = 2.5cm)이 Poj(기존에 있었던 object의 pointcloud) 에 있는 비율이 얼마인지
semantic 유사도 측정- normalized cosine distance within visual descriptors
- normalized cosine distance within visual descriptors
- 위 2개 유사도를 더한 결과가, δ_sim ( 1.1 )을 넘는지 확인
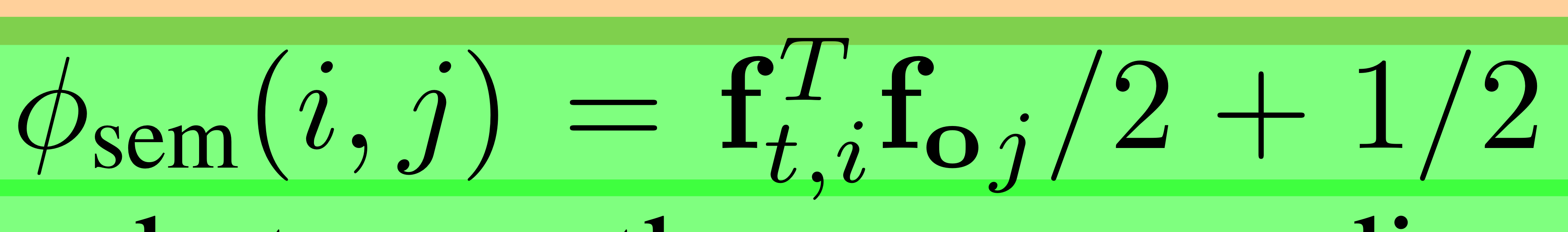
2.A.4. Object Fusion
- 기존 물체와 유사하다고 인정된 물체 후보군에 대한 융합 설명!
- 물체(노드)에 대한 feature vector(visual descriptor, ft,i) 업데이트 하는 공식
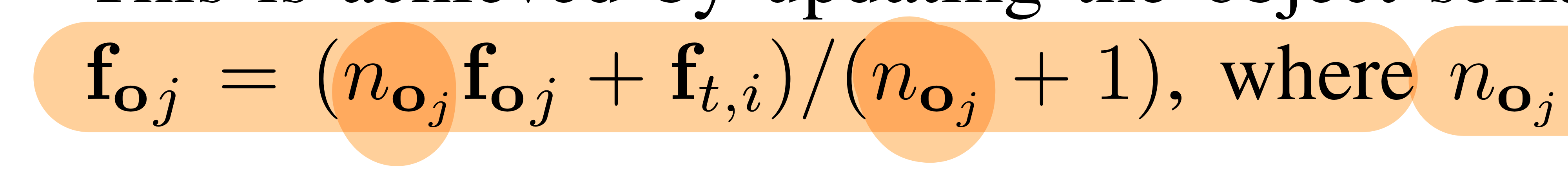
- noj = 지금까지 oj(물체)를 형성하는데 검지되었던 물체 후보군들의 수
- 물체(노드)에 대한 point_cloud는 그냥 합집합으로 더함
- 그리고, redundant points를 제거하기 위한 downsampling
- voxel size에 따라 subsampling
- 병합 후, dbscan clustering을 한번 더 사용한다.
- 그리고, redundant points를 제거하기 위한 downsampling
2.A.5. Node Captioning
- VLM을 이용해서, 노드(object) caption 을 생성함
- 각 노드(물체)는 여러 물체 후보군의 합(누적) 결과임
- 노드(물체)의 point clouds는 여러 물체 후보군 point clouds의 누적 합임
- 그 중, pointcloud 추가의 비중이 가장 높은 10개의 물체 후보군의 카메라 뷰 (RGB iamge)를 가져와서, 이미지를 LVM에 넣습니다.
- 이때, "describe the central object in the image" 텍스트 쿼리를 함께 입력함
- 아래는 LVM이 출력한 rough captions
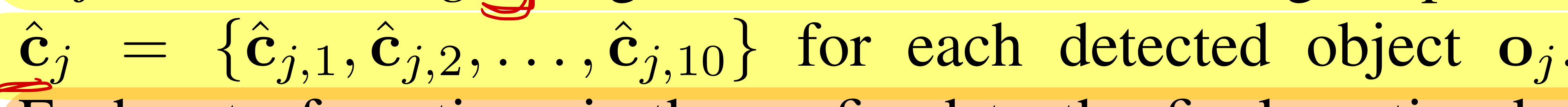
- 각 노드(물체)는 여러 물체 후보군의 합(누적) 결과임
- 위 10개 caption을 다시 LLM에 input으로 통과시켜,(
10개 captions를 일관되고 정확한 final caption으로 요약해달라는추가 text query와 함께)- 최종 caption을 생성함.
B. Scene graph Generation
- nodes(objects)를 구했으니, edges(E_T) (물체와의 관계를 설명)를 구해보자.
- nodes간 연결은,
물리적으로 가까운 거리에 있는 노드끼리 연결하고,- 연결된 노드(edge)에 어떤 정보를 기입하니?
- 의미적(semantic)으로 어떤 연관이 있는지에 대한 text 정보 기입
- 연결된 노드(edge)에 어떤 정보를 기입하니?
B.1. spatial overlaps
그들의 spatial overlaps로 측정
- node(물체)의 3D bounding box간 IOU를 계산하여, 물체 간 similiarity matrix를 만듭니다. (모든 노드가 연결된 dense graph를 상상하라.)
- (노드수, 노드수 )shape의 numpy array이고, 값이 IOU라고 생각하면 됨
- 이 similiarity matrix를 기반으로,
minimum spanning tree(MST)를 만듦- 모든 노드를 연결하되, 사이클이 생기지 않고
- edge weight(IOU 값)의 합이 최대가 되도록?
즉, 많이 겹치는(물체)들만 연결하려고 노력
B.2. semantic relationships
- minimum spanning tree(MST)로 연결된 각 edge에 대해,
- 노드 2개에 대한 정보를 text로 LLM을 통과시켰다.
- LLM input
- 연결된 노드 2개 각각의
object captions and 3D location를 text로 입력 - 추가 text query:
요구사항: 물체 2개 간 공간적 관계를 묘사해주세요!(예: "a on b"? "b in a"?)
- 연결된 노드 2개 각각의
- output
- 노드 2개 간 관계를 설명한 text
- 관계에 대한 자세한 이유를 설명
- LLM을 사용함으로써,
- 가까운 물체들 간 "언어 모델이 해석할 수 있는" 구체적 관계를 정의할 수 있음
- 예
- edge 설명:
옷장에 보관되어 있는가방 - edge 설명:
쓰레기통에 있는 재활용 가능한종이 한장
- edge 설명:
- 이러한 그래프 edge 구조는 downstream task 수행에 효과적인 표현임
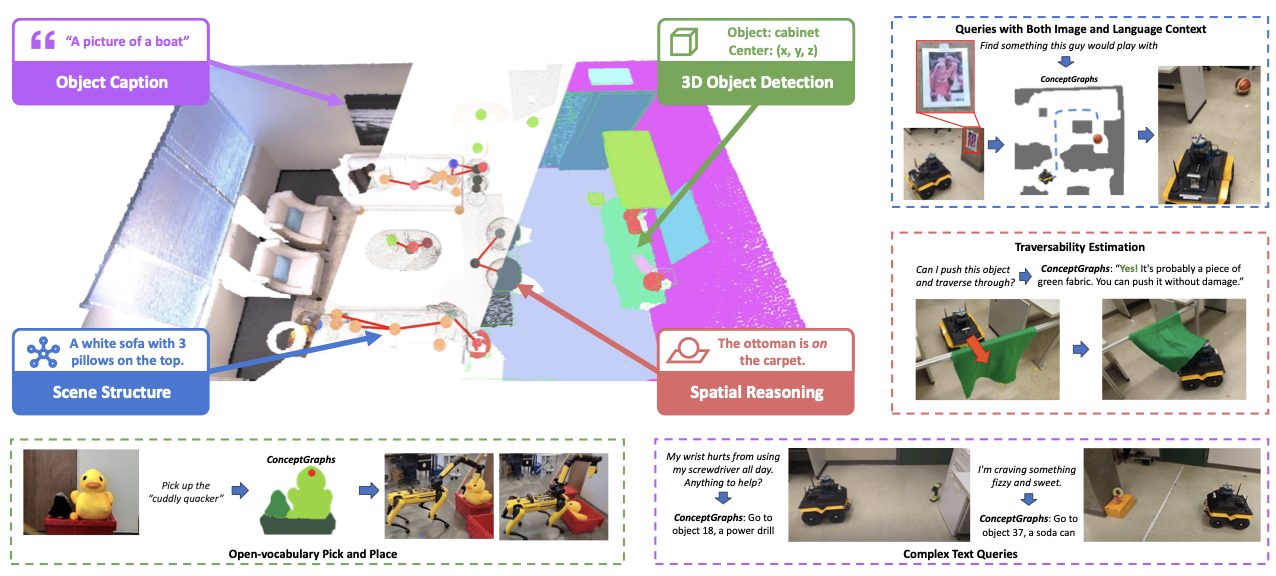
C. Robotic Task Planning through LLM
-
이제, 이렇게 완성한 ConceptGraph를 이용해서 Robotic Task planning을 수행해보자!
-
로봇 사용자가 임의의
자연어로 묘사한 task를 수행할 수 있게 하려면,scene graph M_T를 LLM의 input으로 같이 넣을 수 있어야 한다.
-
각 노드(object) O_T에 대해,
- JSON structured text description으로 변환
- 3D location(bounding box) 정보 포함
- node(object)에 대한 설명(caption) 포함
- JSON structured text description으로 변환
-
자연어로 묘사한 task를 받았을 때, LLM은 그래프에서 가장 관계있는 물체를 찾는다.- 찾은 물체의 node(위치와 설명), 그리고 주변 edge 정보들을 downstream task(grasping / navigation) pipeline에 준다.
- 로봇 주변의 물체들에 대한 semantic 특성을 제공함으로써, 로봇은 다양한 open vocabulary task를 수행할 수 있다.
- scene graph의 text 변환 길이가 너무 길면, 우리는 LLM 대신 LLM planners [52]를 쓰면 된다.
-

-
단계 1: LLM에게 ConceptGraph와 user query(something to wear for a space party) 던지면 ->
most relevant object를 찾아줌- 대답: Gray Nasa shirt on a chair
-
단계 2: VLM을 이용해서,
most relevant object이 기대된 위치에 있는지 가봄 -
단계 3: 가봤는데 없으면, LLM에게 다시,
가장 가능성 있는 위치에 대해 물어봄- 예를 들어: 매핑한 후, 누가 티셔츠 위치를 옮겨놓은 경우.
- 대답: Likely location: large gray laundry basket
-
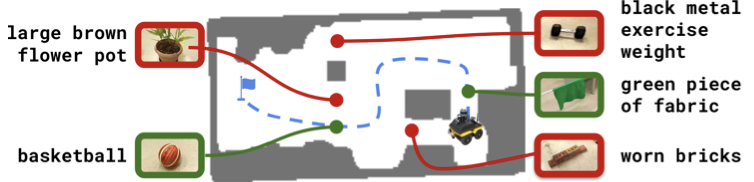
-
목적지로 가는 길이 물체로 인해 막혀 있을 때,
-
LLM에게 물어봐서, 어떤 물체는 밀고 지나가도 되는지 판단할 수 있음
-
LLM은 traversability prediction을 하기 위해, ConceptGraph의 node caption에 의존함.
D. Implementation Details
- Segmentation model: SAM 이용
- feature extractor: CLIP 이용
- VLM: LLAVA 이용
- LLM: GPT4(gpt-4-0613) 이용
- voxel size : 2.5 cm
- pointcloud를 down sampling 할 떄 씀
- ConceptGraphs-Detector (CG-D) 라는 것도 개발함
- image tagging model (RAM[54])을 사용
- 사진에 있는 object classes를 listgkrl dnlgka
- open vocabulary 2D detector (Grounding DINO)를 사용해서
- object bounding boxes를 얻음
- image tagging model (RAM[54])을 사용
- 이 경우, 우리는 검지된 background 물체들(벽,천창, 바닥)을 다뤄야한다.
- 유사도 점수와 관계없이 merging하는 방식으로
코드
구버전
- SAM을 돌린 mask 결과의 bounding box를 가지고,
- CLIP에 넣어서 feature 뽑음
신버전
- YOLO-world를 돌린 결과의 bounding box를 가지고 SAM을 돌려서 mask를 얻은 후
- CLIP에 넣어서 feature 뽑음

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.