1. ICP 의 목적
- ICP(Iterative Closest Point) 알고리즘은
두 포인트 클라우드 또는 데이터 세트 간의 정합성을 최대화하기 위해 사용되는 알고리즘 - 이 방식은 주로 3D 모델링에서 사용되지만,
- 2D 데이터 세트, 특히 로봇 위치 추정 및 지도 생성과 같은 분야에서
예측된 2D 로컬 맵과 실제 2D 로컬 맵을 비교하는 데에도 사용
ICP의 기본적인 목적두 맵 간의 최소 제곱 오차를 최소화하는 최적의 변환(회전과 이동)을 찾는 것
2. ICP 알고리즘의 기본 단계
2.1. 초기 추정치 설정
- 두 데이터 세트 간의 초기 정렬(회전 및 이동)을 추정
2.1.1. 초기 추정치의 중요성
- 수렴 속도: 적절한 초기 추정치는 알고리즘의 수렴 속도를 크게 향상시킬 수 있음.
- 글로벌 minimum 도달 가능성: 올바른 초기 추정치 없이 지역 최소값에 갇힐 위험이 있습니다.
2.1.2. 초기 추정치 설정 방법
2.1.2.1.localization 알고리즘 활용
- 로봇의 localization 알고리즘 결과를 초기 정렬의 추정치로 활용
2.1.2.2. 모션 모델 활용:
- 로봇의 모션 모델(예: RK4) 과 제어 입력(v, w)을 사용하여 예상되는 이동을 계산하고, 이를 초기 정렬의 추정치로 사용
- 동적환경에 적합
2.1.2.3. 특징 기반 접근:
- 두 데이터 세트에서 동일하거나 유사한 특징(예: 특정 형태의 코너, 엣지, 또는 기타 구조적 특징)을 식별하고,
- 이러한 특징 간의 관계를 사용하여 초기 정렬을 추정
- 이 방법은 특히
특징이 뚜렷한 환경에서 효과적
2.1.3. 최적화 기법의 적용
- 로버스트 추정 기법:
- 모든 초기 추정치가 완벽할 수는 없으므로, 추후 단계에서 로버스트한 최적화 기법을 적용하여 초기 추정의 오차를 최소화하는 것이 중요
- 멀티 모달 접근법:
- 가능한 여러 초기 추정치를 고려하고, 여러 후보 중 최적을 선택하는 멀티 모달 접근법을 사용할 수도 있음 (AMCL처럼)
2.2. 가장 가까운 점 찾기:
- 한 데이터 세트(source set) 내의 각 점을 다른 데이터 세트(target set)와 비교하여,
각 소스 점에 대응하는 타겟 세트 내의 가장 가까운 점을 식별하는 것 - 이는 보통
k-d 트리, 옥트리, 쿼드 트리와 같은 공간 분할 구조를 사용하여 효율적으로 수행
2.2.1. 공간 분할 구조와 k-d 트리
- 공간 분할 구조의 이용:
- 공간 분할 구조는 고차원 데이터를 효율적으로 처리하기 위해 고안
- 목적: 검색, 쿼리, 최근접 이웃 찾기 등의 연산을 빠르게 수행할 수 있게
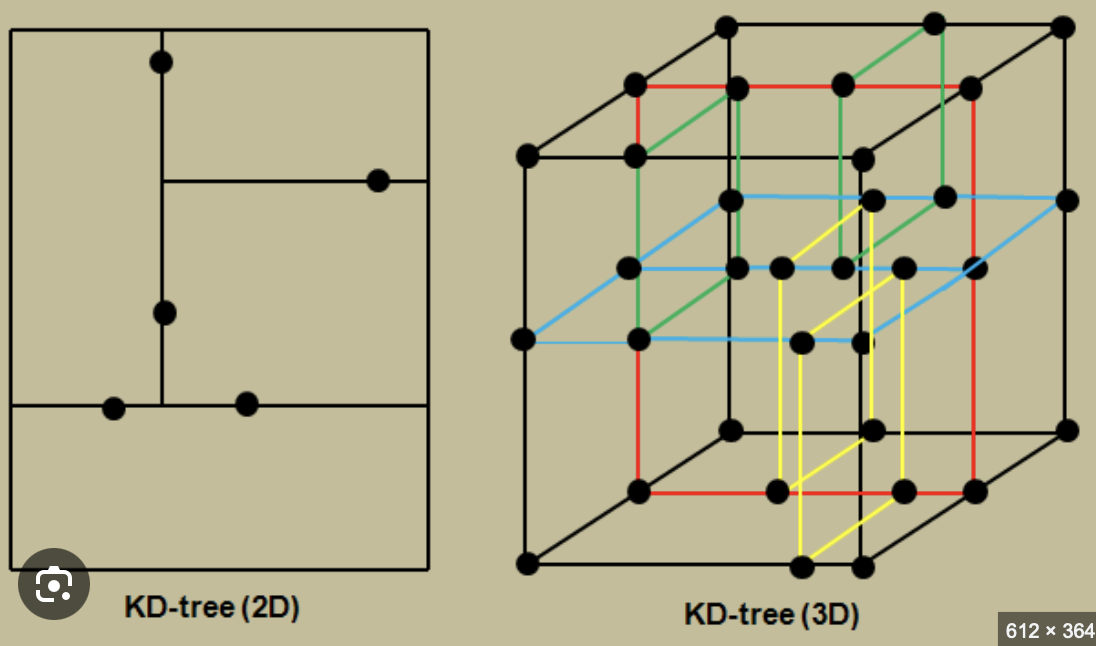
- k-d 트리(K-Dimensional Tree) 공간 분할:
- k차원 공간의 점들을 저장하기 위한
이진 트리 자료구조
- k차원 공간의 점들을 저장하기 위한
- k-d 트리(K-Dimensional Tree) in 2d local map
- 노드 선택:
- 2D 로컬 맵의 모든 점들 중에서 하나의 점을 선택하여, 트리의
루트 노드로 설정- 보통 이는 중앙값(median)이나 평균값을 기준으로 선택
- 처음에는 x축을 기준으로 점을 분할
- 분할 기준 축 선택:
- 2D 공간에서는 x축과 y축이 번갈아가며 분할 기준 축으로 선택
- 첫 번째 분할은 x축에 대해 이루어지고, 다음 분할은 y축에 대해 이루어짐
- 이 패턴은 트리의 각 레벨마다 반복
- 재귀적 분할:
- 선택된 노드(점)를 기준으로, 나머지 점들을 두 서브셋으로 나눔
한 서브셋은 선택된 축에 대해 선택된 점의 값보다 작은 점들로 구성되고, 다른 서브셋은 그보다 큰 점들로 구성- 각 서브셋에 대해 이 과정을 재귀적으로 반복하여,
각 서브셋에 대해 새로운 노드를 선택하고 서브트리를 생성
- 종료 조건:
점이 하나도 없거나, 지정된 최소 노드 크기에 도달하면 재귀를 종료이때 각 노드는 트리 내에서 하나의 점 또는 최종적인 점 집합을 대표
- k-d 트리 구축 후, 이 트리를 이용해 가장 가까운 점을 찾거나 범위 검색을 수행할 수 있음
- 재귀적 탐색:
- 소스 세트의 각 점에 대해, k-d 트리를 재귀적으로 탐색하여 가장 가까운 타겟 점을 찾습니다.
- 이는 탐색 과정에서 트리의 노드를 순회하며, 각 단계에서 현재 노드의 점과 소스 점 사이의 거리를 계산
- 백트래킹과 최소 거리 업데이트:
- 탐색 도중, 이미 발견된 가장 가까운 점과의 거리보다 더 큰 거리에 있는 노드는 탐색에서 제외
- 이는 백트래킹을 통해 불필요한 탐색을 줄이며 계산 효율성을 높입니다.
- 최종 최근접 점의 결정:
- 모든 소스 점에 대해 이 과정을 반복하며, 각 소스 점에 대응하는 가장 가까운 타겟 점을 결정
2.3. 최적 변환 계산:
가장 가까운 점 쌍 사이의 거리를 최소화하는 변환(회전 및 이동)을 계산- 이는 보통
SVD(특이값 분해)나 다른 최적화 기법(선형 대수학의 방법)을 사용하여 수행
2.3.1. 변환 계산의 기본 원리
- 변환 정의:
- 변환은 일반적으로 회전(R)과 이동(t)의 조합으로 정의
- 2D 공간에서 회전은 하나의 각도로, 이동은 2차원 벡터로 표현
- 목적 함수 설정:
가장 가까운 점 쌍 간의 거리의 제곱 합(Squared Distance Sum)을 최소화하는 R과 t를 찾는 것을 목적
2.3.2. SVD(특이값 분해)를 활용한 계산 방법
2.3.2.1. **중심화(Centering)**:
- 소스 데이터 세트와 타겟 데이터 세트 모두에 대해 중심(평균 위치)을 계산
- 목적은 두 세트를 각각의 중심(즉, 평균 위치)으로 이동시켜, 회전 및 이동 계산 시 기준점을 일치시키는 것
- 중심화의 중요성
- 회전 계산의 정확성 향상:
- 중심화는 회전 변환 계산 시 발생할 수 있는 오류를 최소화
- 두 데이터 세트가 동일한 기준점을 공유하므로, 회전 변환은 이 기준점을 중심으로 정확하게 계산될 수 있음
- 이동 변환의 간소화:
- 중심화 이후, 이동 변환은 단순히 소스 데이터 세트의 중심에서 타겟 데이터 세트의 중심으로의 이동으로 계산될 수 있음
- 이는 전체 변환 계산 과정을 보다 효율적으로 만듦
- 회전 계산의 정확성 향상:
- 평균 위치 계산:
- 이는 각 점의 좌표값을 각 축별로 평균내어 계산할 수 있음
- 2D 맵의 경우, (x)와 (y) 좌표에 대한 평균값을 계산합니다.
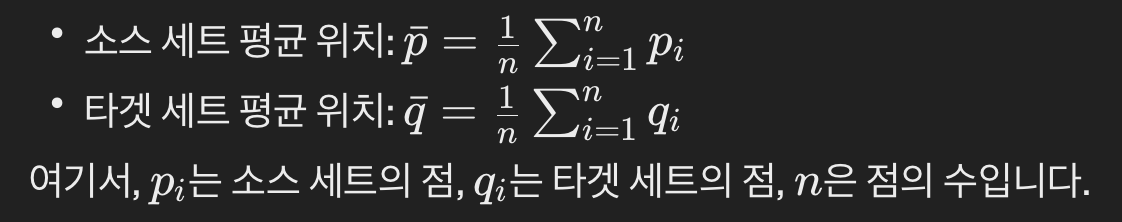
- 중심 이동:
- 각 데이터 세트의 모든 점에서 해당 세트의 평균 위치를 빼줌으로써, 데이터 세트를 중심(원점)으로 이동

2.3.2.2. 상관 행렬 계산
상관 행렬: 소스 세트의 점들과 그에 해당하는 타겟 세트의 가장 가까운 점들 사이의 관계를 수학적으로 모델링상관 행렬생성 목적: 두 세트 간의 공간적 관계를 나타내는 회전 방향을 추정
2.3.2.2.1. 상관 행렬의 정의
- 상관 행렬은 소스 세트와 타겟 세트 간의 점들의 외적의 합
- 각 쌍의 외적:
소스 점과 타겟 점 간의 상대적인 위치 관계를 나타냄
- 각 쌍의 외적:

2.3.2.2.2. 상관 행렬의 역할
- 회전 방향 추정:
상관 행렬 \(H\)는 이후 SVD(특이값 분해) 과정에서 회전 행렬 \(R\)을 계산하는 데 사용SVD는 \(H\)를 분해하여 소스 세트를 타겟 세트에 최적으로 맞추는 회전을 도출
- 공간적 관계 모델링:
- 상관 행렬은 두 데이터 세트 간의 공간적 관계를 종합적으로 모델링
- 이는 소스 세트를 타겟 세트에 최적으로 정렬하는 과정에서 기준
2.3.2.3. **SVD 수행**:
- 상관 행렬에 대해 SVD를 수행하여, 회전 행렬(R)과 이동 벡터(t)를 도출
- SVD는 행렬을 세 행렬의 곱(U, Σ, V^T)으로 분해하는 과정이며, 회전 행렬은 U와 V^T의 곱으로 얻어짐
2.3.2.4. 회전 및 이동 계산:
- 계산된 회전 행렬과 이동 벡터를 이용해 소스 데이터 세트를 타겟 데이터 세트에 정렬
2.4. 변환 적용 및 반복
- 계산된 최적 변환을 한 데이터 세트에 적용하고, 이 과정을 반복
- 변환된 데이터 세트가 다른 데이터 세트와 충분히 잘 정렬될 때까지 이 과정을 반복
2.5. 수렴 조건 검사
- 오차가 특정 임계값 이하로 떨어지거나 지정된 반복 횟수에 도달하면 알고리즘을 종료
3. ICP 알고리즘의 장단점
3.1. 장점:
- 로봇 위치 추정과 지도 생성에서
높은 정확도
3.2. 단점:
초기 추정치에 크게 의존하며, 잘못된 초기 추정치는 지역 최소값으로 수렴할 위험을 증가시킴계산 비용이 높을 수 있으며, 특히 데이터 포인트의 수가 많은 경우 이 문제가 심화
4. 계산 비용 최적화 전략
- 다운샘플링:
- 데이터 포인트의 수를 줄이는 것은 계산 비용을 줄이는 가장 직접적인 방법
- 유니폼 샘플링, 랜덤 샘플링, 복셀 그리드 필터 등 다양한 다운샘플링 기법을 사용할 수 있음
- 이는 처리해야 할 데이터의 양을 줄이면서도 주요 구조를 유지하도록 도와줌
- 효율적인 가장 가까운 점 검색:
k-d 트리나 옥트리와 같은 공간 분할 구조를 사용하여 가장 가까운 점 검색의 속도를 향상시킬 수 있음- 이러한 자료 구조는 대규모 데이터 세트에 대한 검색을 빠르게 수행할 수 있도록 해줌
- 병렬 처리:
- ICP 알고리즘의 여러 단계, 특히 가장 가까운 점 검색과 최적 변환 계산 과정은 병렬 처리에 적합
GPU를 활용한 병렬 처리를 통해 이러한 계산의 속도를 대폭 향상시킬 수 있음
5. 적절한 초기 추정치 설정 전략
- global 위치 추정 알고리즘과의 결합:
- ICP 알고리즘을 전역 위치 추정 알고리즘(예: Monte Carlo Localization, SLAM 알고리즘 등)과 결합하여 사용함으로써, 보다 정확한 초기 추정치를 제공할 수 있음
- 이는 ICP가 지역 최소값에 빠지는 위험을 줄이고 수렴 속도를 향상시키는 데 도움이 됨
코드
registration_generalized_icp
registration_generalized_icp함수는 Open3D 라이브러리의 일반화된반복 최근접점 (Generalized Iterative Closest Point, GICP)알고리즘을 구현한 함수
- GICP는 기존의 ICP (Iterative Closest Point) 알고리즘을 확장한 것으로, 더 정밀하게 포인트 클라우드 간의 정합을 수행
ICP와 GICP의 기본 개념
- ICP 알고리즘은 두 포인트 클라우드 간의 최적의 변환을 찾기 위해 반복적으로 다음 두 단계를 수행
- 최근접 점 찾기:
소스 포인트 클라우드의 각 점에 대해, 타겟 포인트 클라우드 내에서 가장 가까운 점을 찾음
- 최근접 점 찾기:
- 최소 제곱 변환 추정: 이 최근접 점 쌍을 사용하여 소스 포인트 클라우드를 타겟 포인트 클라우드에 최적으로 맞추는 변환(회전과 이동)을 추정
- GICP 알고리즘:
- 각 점이 가지고 있는 위치 뿐만 아니라 점 주변의 지역적 구조 정보를 활용
- 이 정보는 점들의 공분산을 통해 표현되며, 포인트 클라우드의 특정 방향에 대한 정보를 포함하여 보다 정밀한 정합이 가능하게 함
GICP의 수학적 설명

결론
registration_generalized_icp는 두 포인트 클라우드 간의 정밀한 정합을 위해 공분산을 고려하는 확장된 ICP 방법을 제공- 이 방법은 특히 기하학적 구조가 복잡하거나 노이즈가 많은 환경에서 기존의 ICP보다 뛰어난 성능을 보여줍니다.
- 더 나은 정합 정확도를 제공하며, 로보틱스, 3D 재구성, 환경 모니터링 등 다양한 분야에서 유용하게 사용될 수 있습니다.

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.