OpenEQA: Embodied Question Answering in the Era of Foundation Models
foundation model in robotics
목록 보기
12/14
- https://openaccess.thecvf.com/content/CVPR2024/papers/Majumdar_OpenEQA_Embodied_Question_Answering_in_the_Era_of_Foundation_Models_CVPR_2024_paper.pdf
- https://github.com/facebookresearch/open-eqa
1. 개요
- "Embodied Question Answering" (EQA)라는 개념을 다루고 있으며, 이는 환경을 충분히 이해하여 자연어로 질문에 답하는 작업을 의미
- 논문은 OpenEQA라는 첫 번째 개방형 어휘 EQA 벤치마크를 제안하며, 이를 통해 여러 최신 기초 모델들을 평가
- OpenEQA는 에피소드 메모리(Episodic Memory)와 활동적 탐색(Active Exploration)의 두 가지 사용 사례를 지원하며,
- 180개 이상의 실제 환경에서 1600개 이상의 고품질 인간 생성 질문을 포함
- 평가 프로토콜 개발
- LLM을 이용해 (인간이 생성한 정답과의 유사성을 기반으로) 답변의 정확성을 평가하는 자동화된 평가 프로토콜을 제안
- 질문과 정답:
- 먼저,
인간이 만든 질문과그에 대한 정확한 답변(정답)이 있습니다. - 예를 들어, "흰색 플라스틱 저장 용기 아래에 뭐가 있나요?"라는 질문에 대한 정답이 "전자레인지 두 대"라고 가정해봅시다.
- 모델의 답변 생성:
- 인공지능 모델은 이 질문에 대해 답변을 생성합니다. 예를 들어, 모델이 "전자레인지"라고 답변했다고 해봅시다.
- 답변 평가:
- 이제 모델의 답변이 인간이 만든 정답과 얼마나 유사한지를 평가해야 합니다.
- 이때 LLM(대형 언어 모델)을 사용해서, 모델이 생성한 답변이 인간의 정답과 얼마나 비슷한지를 점수로 매깁니다.
- 예를 들어, "전자레인지"라는 답변은 "전자레인지 두 대"라는 정답과 아주 비슷하므로 높은 점수를 받을 수 있습니다.
- 자동화된 평가:
- 이 평가 과정은 LLM을 통해 자동으로 이루어집니다.
- 즉, 인간이 일일이 평가하지 않고도, LLM이 알아서 유사성을 판단하고 점수를 매깁니다.
- 이렇게 하면 많은 양의 데이터를 빠르고 효율적으로 평가할 수 있습니다.
- 인간 평가와의 비교:
- 마지막으로, 이 자동화된 평가 결과가 실제 인간이 평가한 결과와 얼마나 일치하는지를 봅니다.
- 논문에서 이 평가 프로토콜은 인간이 평가한 결과와 높은 상관관계를 보여주었기 때문에, 신뢰할 수 있는 방법으로 간주됩니다.
- 기초 모델 평가:
- 최근 출시된 GPT-4V를 포함한 여러 기초 모델을 평가했으며, 이들 모델은 인간 수준의 성능에 비해 크게 뒤떨어진다는 결론을 내렸습니다.
- 특히, 공간 이해와 관련된 질문에서 어려움을 겪는 것으로 나타났습니다.
1.1. 에피소드 메모리(Episodic Memory, EM-EQA):
- 개념:
- 에피소드 메모리는 에이전트가 과거에 경험한 사건이나 관찰을 기억하여 이를 바탕으로 질문에 답변하는 능력을 의미
- 이 접근 방식은 주로 스마트 안경이나 기타 웨어러블 디바이스에 탑재된 인공지능 에이전트에 사용
- 사용 사례:
- 예를 들어, 사용자가 "내 열쇠를 어디에 두었나요?"라고 질문하면, 에이전트는 사용자가 과거에 집 안에서 이동하면서 시각적으로 기록한 정보(에피소드 메모리)를 활용하여 "부엌 섬 위에 두었습니다."라고 답변할 수 있습니다.
- 이 경우 에이전트는 스스로 환경을 탐색하는 대신, 과거의 기억된 정보를 이용해 답변합니다.
- 장점:
- 사용자가 이미 경험한 환경에 대한 정보만을 사용하기 때문에, 추가적인 탐색이 필요하지 않아 빠른 응답이 가능합니다.
1.2. 활동적 탐색(Active Exploration, A-EQA):
- 개념:
- 활동적 탐색은 에이전트가 실시간으로 환경을 탐색하면서 필요한 정보를 수집하고, 이를 바탕으로 질문에 답변하는 능력을 의미합니다.
- 이 접근 방식은 주로 자율 이동 로봇과 같은 기기에 사용됩니다.
- 사용 사례:
- 예를 들어, "집에 케이엔 페퍼가 남아 있나요?"라는 질문에 대해, 로봇은 집 안을 탐색하여 "팬트리에서 케이엔 페퍼 병을 찾았습니다."라고 답변할 수 있습니다.
- 이 경우 로봇은 질문에 답변하기 위해 직접 환경을 탐색하고 필요한 정보를 수집합니다.
- 장점:
- 에이전트가 질문에 답변하기 위해 실시간으로 환경을 탐색하여, 새로운 정보를 수집할 수 있음
- 이는 사용자가 과거에 경험하지 않은 상황에서도 정확한 답변을 제공할 수 있는 능력을 의미
2. 그림들
2.1. Fig 4.
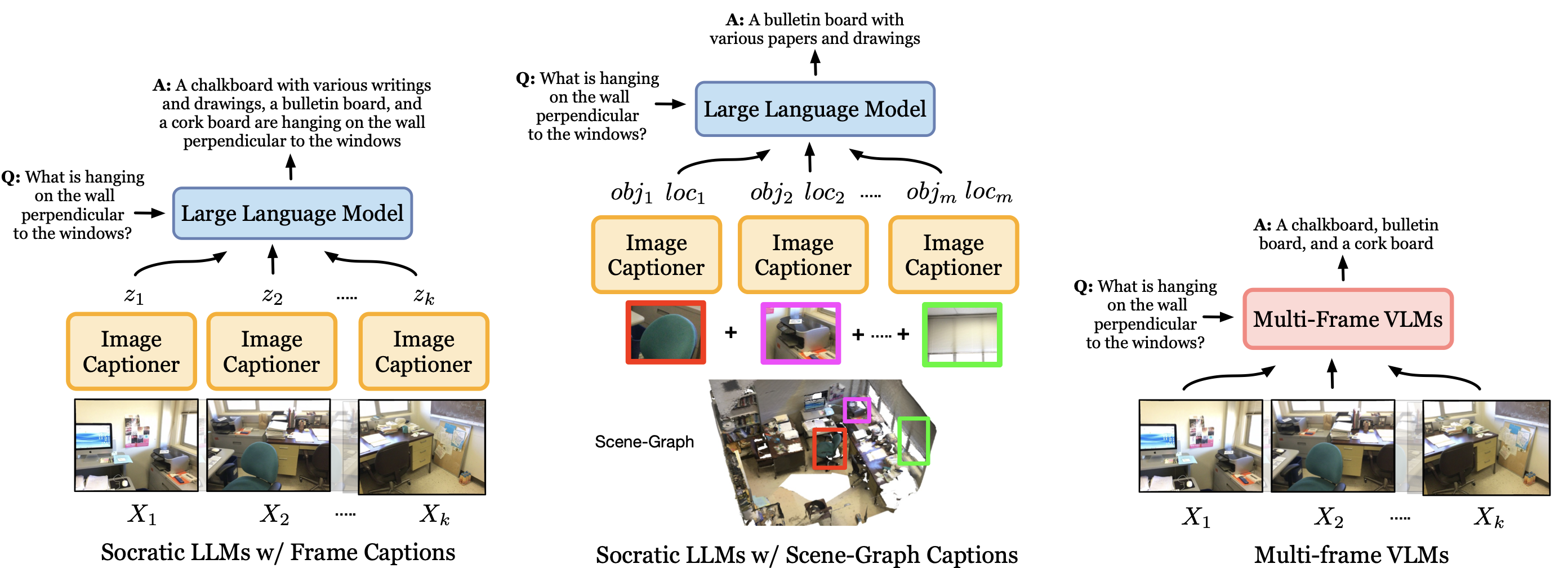
- EQA 에이전트들:
- (왼쪽) 이미지 캡션이 포함된 소크라틱 LLMs는
- 에피소드 메모리에서 프레임을 추출하여 그에 대한 캡션을 생성하고,
- 이를 LLM에 컨텍스트로 제공하여 답변을 생성합니다.
- (가운데) scene-graph 캡션이 포함된 소크라틱 LLMs는
- 에피소드 메모리의 객체 중심 장면-그래프 표현을 활용하며,
- 여기에는
객체 중심 크롭 이미지의 캡션과해당 객체들의 3D 위치 정보가 포함
- (오른쪽) 다중 프레임 VLM은
- 에피소드 메모리의 시각적 프레임들을 직접 처리하여 질문에 답변
2.2. Fig 2.
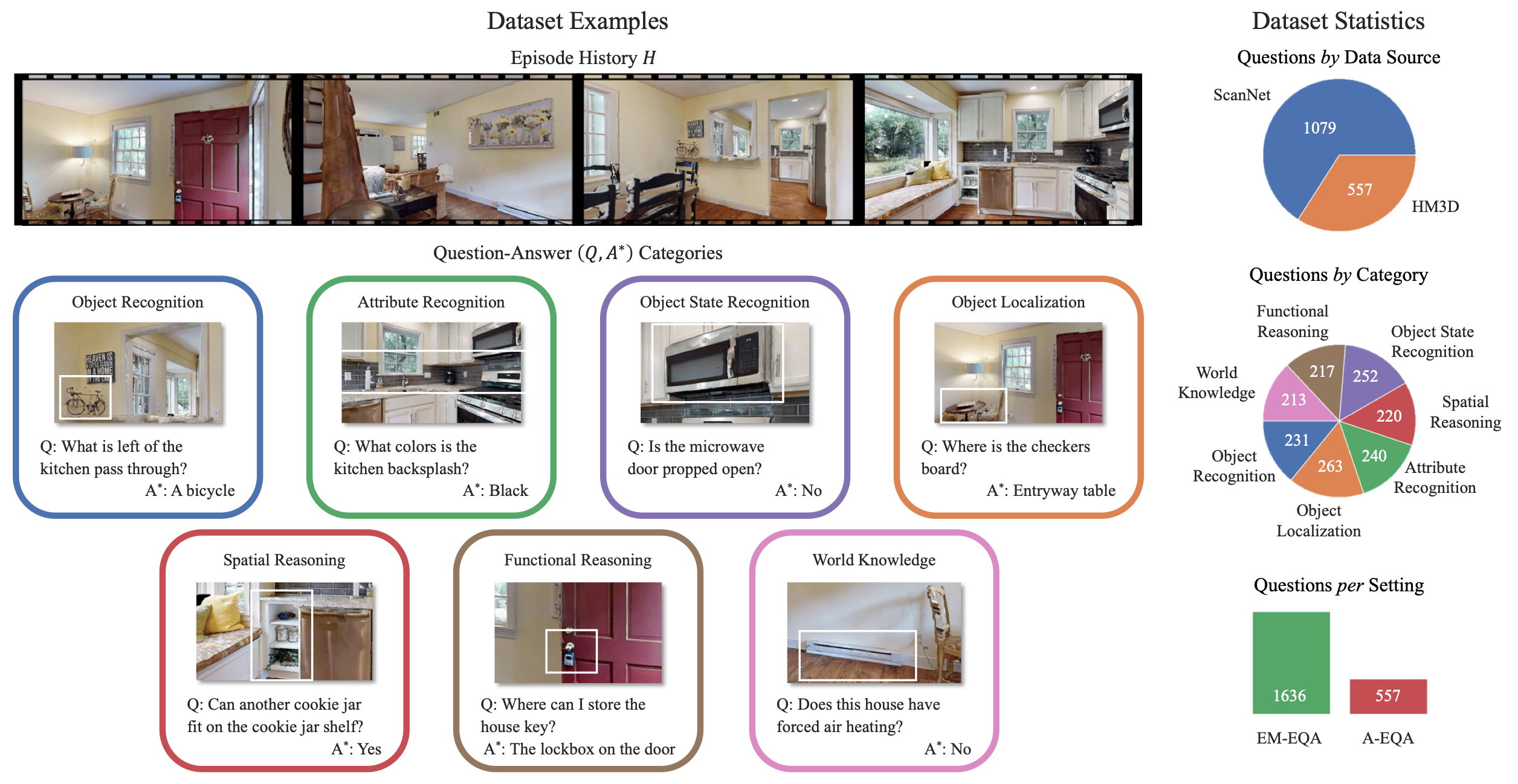
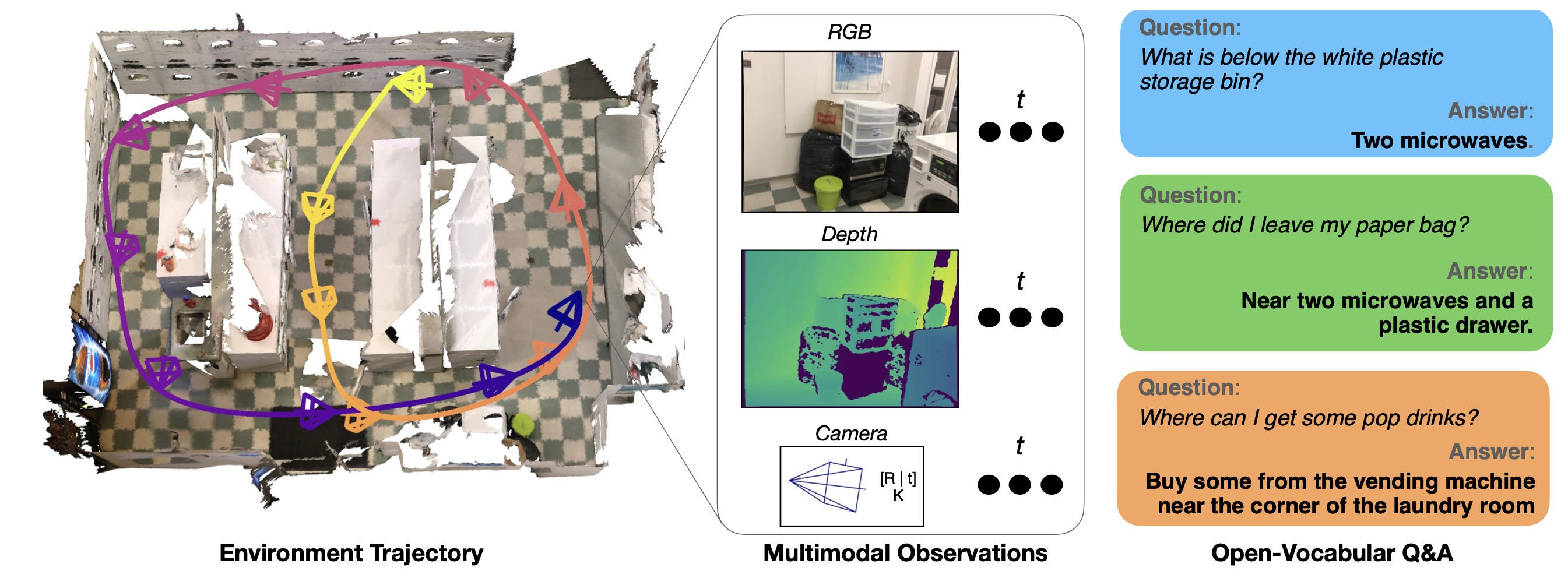
- OpenEQA의 예시 질문과 데이터셋 통계를 보여줍니다.
- 에피소드 히스토리 H는 집 내부를 사람처럼 둘러보는 과정을 제공합니다.
- EQA 에이전트는 7가지 EQA 카테고리에서 인간이 생성한 다양한 질문 Q에 답변해야 하며, 이를 통해 정답 A∗ 와 일치하도록 노력합니다.
- 이러한 투어는 집과 사무실 위치를 포함한 다양한 환경에서 수집되었습니다(그림에는 나타나지 않음). 추가적인 데이터셋 예시는 부록 O에 있습니다.
- 데이터셋 통계(오른쪽)는 비디오 출처(상단), 질문 카테고리(중간), 그리고 에피소드 메모리와 활동적 설정에 따른 질문 분포를 보여줍니다.
- 설계상, HM3D 질문은 EM-EQA와 A-EQA 설정 모두에서 공유된다는 점에 유의하십시오.
3. 결론
- 우리는 OpenEQA를 사용하여 최신 기초 모델들과 그 조합을 벤치마킹했습니다.
- 여기에는 이미지 캡션 활용, scene-graph 구축, GPT-4V와 같은 다중 프레임 VLM(Visual Language Model) 접근법이 포함
- 궁극적으로 우리는 최고의 모델(GPT-4V의 49.6%)과 인간 수준의 성능(86.8%) 사이에 큰 격차가 있음을 발견했습니다.
- 특히 공간적 이해가 필요한 질문에 대해, 앞서 언급된 에이전트들은 시각 정보 없이 동작하는 LLM과 유사한 성능을 보여,
- EQA 에이전트가 실제 도메인에 대비하기 위해서는 지각과 의미적 기초 작업에 대한 추가 개선이 필요함을 시사

새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.