broadcast_to / repeat / repeat_interleave / view / reshape / expand / expand_as / tile / flatten / unsqueeze / squeeze / stack / cat / split / chunk
딥러닝
목록 보기
5/16
broadcast_to(input, shape)
- 복사 x
- shape: list / tuple /torch.Size
.expand(shape)과 같다.
>>> x = torch.tensor([1, 2, 3]) # shape (3,)
>>> torch.broadcast_to(x, (3, 3)) #shape (3, 3)
tensor([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]]).expand(*sizes)
- 복사 x
- 주의
- 확장된 텐서에서는, 한 개 이상의 요소가 같은 메모리 위치를 참조할 수 있습니다.
- 예를 들어, 만약 원본 텐서의 특정 요소가 확장된 텐서에서 여러 위치에 나타난다면, 모든 해당 위치는 동일한 메모리 주소를 참조하게 됩니다.
- 이 상황에서 문제가 발생할 수 있는데, "제자리 연산(in-place operations)"이란 텐서의 값을 변경할 때 새로운 메모리 공간을 할당하는 것이 아니라 원래 텐서의 메모리를 직접 수정하는 연산을 말합니다.
- 만약 이런 연산이 벡터화(vectorized)되어 동시에 여러 요소를 수정한다면, 동일한 메모리 위치를 참조하는 여러 요소들이 예상치 못한 방식으로 변경될 수 있습니다.
- 즉, 한 위치에서의 변경이 다른 위치에도 똑같이 반영되어 버립니다.
- 만약 텐서의 값을 안전하게 변경하고 싶다면, 확장된 텐서를 clone 함수를 사용하여 복제한 후에 작업을 수행해야 합니다.
>>> x = torch.tensor([[1], [2], [3]]) # (3, 1)
>>> x.size()
torch.Size([3, 1])
>>> x.expand(3, 4) # -> (3, 4)
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
>>> x.expand(-1, 4) # -1 means not changing the size of that dimension
# (3, 4)
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])expand_as
- 복사 x
self.expand(other.size())와 같음.
repeat
- 복사 o
- numpy.tile과 유사
>>> x = torch.tensor([1, 2, 3]) # (3,)
>>> x.repeat(4, 2)
tensor([[ 1, 2, 3, 1, 2, 3],
[ 1, 2, 3, 1, 2, 3],
[ 1, 2, 3, 1, 2, 3],
[ 1, 2, 3, 1, 2, 3]])
>>> x.repeat(4, 2, 1).size()
torch.Size([4, 2, 3]) # (4, 2, 3)repeat_interleave(input, repeats, dim=None, *, output_size=None)
- 인자
repeats: The number of repetitions for each element. repeats is broadcasted to fit the shape of the given axis.dim- The dimension along which to repeat values.
- By default, use the flattened input array, and return a flat output array.
output_size- 반드시 keyword argument
- Total output size for the given axis ( e.g. sum of repeats).
- If given, it will avoid stream synchronization needed to calculate output shape of the tensor.
- 좀 더 빠르게 계산할 수 있다는 뜻 같다. (메모리 사용도 줄이고)
- return
Repeated tensor which has the same shape as input, except along the given axis.
- 복사 o
- numpy.repeat과 유사
>>> x = torch.tensor([1, 2, 3])
>>> x.repeat_interleave(repeats=2)
tensor([1, 1, 2, 2, 3, 3])
>>> y = torch.tensor([[1, 2], [3, 4]])
>>> torch.repeat_interleave(y, repeats=2)
tensor([1, 1, 2, 2, 3, 3, 4, 4])
>>> torch.repeat_interleave(y, repeats=3, dim=1)
tensor([[1, 1, 1, 2, 2, 2],
[3, 3, 3, 4, 4, 4]])
>>> torch.repeat_interleave(y, repeats=torch.tensor([1, 2]), dim=0)
tensor([[1, 2],
[3, 4],
[3, 4]])
>>> torch.repeat_interleave(y, repeats=torch.tensor([1, 2]), dim=0, output_size=3)
tensor([[1, 2],
[3, 4],
[3, 4]]).view(*shape)
- 복사 x
원본 텐서의 데이터를 실제로는 변경하지 않으면서, 다른 차원으로 '보이게' 하는 방법입니다.메모리 상에서 데이터의 위치는 그대로 두고, 단지 데이터를 읽는 방법만 바꾸는 것입니다.torch.transpose와torch.view는 다름! (결과 shape이 같더라도)- transpose는 memory의 tensor layout을 바꿈!
- view는 tensor의 layout을 바꾸지 않음!
- 모양을 바꾸려는 새로운 텐서는 원본 텐서의 'stride'와 호환 가능해야 합니다.
stride라는 것은각 차원에 대해 텐서 안에서 다음 원소까지 건너뛰어야 하는 메모리 상의 거리입니다.
- 쉽게 말하면, 새로운 모양의 각 차원은 원본 텐서의 차원과 메모리 상에서 이어져 있어야 합니다. 만약 새로운 차원이 메모리 상에서 연속적이지 않으면, view를 사용할 수 없습니다.
그렇지 않으면 새로운 텐서를 만들기 위해 데이터를 실제로 복사해야 합니다(예를 들어 reshape 사용).이러한 복사 과정은 추가적인 메모리를 사용하고, 계산 비용이 듭니다.
>>> x = torch.randn(4, 4)
>>> x.size()
torch.Size([4, 4])
>>> y = x.view(16)
>>> y.size()
torch.Size([16])
>>> z = x.view(-1, 8) # the size -1 is inferred from other dimensions
>>> z.size()
torch.Size([2, 8])
>>> a = torch.randn(1, 2, 3, 4)
>>> a.size()
torch.Size([1, 2, 3, 4])
-----------------------------
>>> b = a.transpose(1, 2) # Swaps 2nd and 3rd dimension
>>> b.size()
torch.Size([1, 3, 2, 4])
-----------------------------
>>> c = a.view(1, 3, 2, 4) # Does not change tensor layout in memory
>>> c.size()
torch.Size([1, 3, 2, 4])
>>> torch.equal(b, c)
Falsereshape(input, shape)
- 복사 세모
Contiguous inputs and inputs with compatible stridescan be reshaped without copying, but you should not depend on the copying vs. viewing behavior.Contiguous라는 단어는 텐서가 메모리 상에서 연속적으로 배열되어 있다는 것을 의미- 즉, 텐서의 원소들이 메모리 상에서 서로 붙어 있어 순차적으로 나열되어 있다는 뜻이죠.
- 형태가 호환되면
view를 반환하고, 그렇지 않으면 복사본을 만듭니다(contiguous()를 호출하는 것과 같습니다).- inputs with compatible strides:
- 입력 텐서가 연속적이지 않더라도, stride 패턴이 새로운 모양과 호환된다면 복사 과정 없이 재구성할 수 있습니다.
- 이는 메모리 상에서 원소 간의 거리가 새로운 모양에서도 동일한 패턴을 유지한다는 뜻입니다.
- 예를 들어, 3x4 텐서에서 각 행의 원소가 메모리 상에서 10개의 공간을 뛰어넘어 배치되어 있다면,
- 이를 2x6 모양으로 변경하려면 새로운 모양의 각 행도 10개의 공간을 뛰어넘는 패턴을 유지해야만 복사 없이 재구성이 가능합니다.
- inputs with compatible strides:
- 중요:
명시적으로 텐서가 연속적이게 만들기 위해 contiguous()를 호출하는 습관필요
>>> a = torch.arange(4.)
>>> torch.reshape(a, (2, 2))
tensor([[ 0., 1.],
[ 2., 3.]])
>>> b = torch.tensor([[0, 1], [2, 3]])
>>> torch.reshape(b, (-1,))
tensor([ 0, 1, 2, 3])contiguous(memory_format=torch.contiguous_format)
Contiguous라는 단어는 텐서가 메모리 상에서 연속적으로 배열되어 있다는 것을 의미
- 명시적으로 텐서가 연속적이게 만들어줍니다.
- 메모리 순서를 재정렬하기 위해:
- PyTorch에서 연산을 수행할 때, 텐서의 레이아웃(layout)이 예상한 메모리 순서와 다를 경우, 연산의 효율성을 높이기 위해 내부적으로 텐서를 연속적인 형태로 만들어야 할 때가 있습니다.
- 예를 들어,
텐서의 일부를 슬라이싱하거나 전치(transpose) 연산을 수행하면,결과 텐서는 원본 텐서와 메모리를 공유하지만, 원소들이 메모리 상에서 더 이상 연속적이지 않을 수 있습니다. - 이 경우 contiguous()를 호출하여 메모리 상에서 원소들이 연속적인 배열을 갖도록 재정렬합니다.
- 텐서 뷰(view) 연산을 위해
- 텐서를 .view()나 .reshape()와 같은 메소드로 새로운 모양으로 변환하려 할 때, 해당 텐서가 이미 연속적인 메모리 레이아웃을 갖고 있지 않다면, 이러한 변환은 실패할 수 있습니다. contiguous() 메소드를 사용하여 텐서를 먼저 연속적인 메모리 레이아웃으로 변환함으로써 이 문제를 해결할 수 있습니다.
TORCH.TENSOR.IS_CONTIGUOUS
Contiguous라는 단어는 텐서가 메모리 상에서 연속적으로 배열되어 있다는 것을 의미
- Contiguous면 True를 반환합니다.
tile(input, dims)
- 복사 o
- np.tile과 비슷함.
- input의 차원 수 > dim의 차원 수
if input has shape (8, 6, 4, 2) and dims is (2, 2), then dims is treated as (1, 1, 2, 2).
- input의 차원 수 < dim의 차원 수
For example, if input has shape (4, 2) and dims is (3, 3, 2, 2), then input is treated as if it had the shape (1, 1, 4, 2).
- 복사 o
>>> x = torch.tensor([1, 2, 3])
>>> x.tile((2,))
tensor([1, 2, 3, 1, 2, 3])
>>> y = torch.tensor([[1, 2], [3, 4]])
>>> torch.tile(y, (2, 2))
tensor([[1, 2, 1, 2],
[3, 4, 3, 4],
[1, 2, 1, 2],
[3, 4, 3, 4]])flatten(input, start_dim=0, end_dim=-1)
- 복사 세모
- 뷰(view) 반환:
- 입력 텐서가 이미 메모리상에서 연속적이고 평탄화된 형태로 뷰를 만들 수 있다면, 새로운 데이터 복사 없이 원본 데이터를 참조하는 뷰를 반환합니다.
- 뷰는 원본 데이터에 대한 다른 차원의 표현이며, 원본 데이터를 공유합니다.
- 따라서, 원본 데이터나 뷰를 수정하면 서로에게 영향을 미칩니다.
- 복사본 반환:
- 입력 텐서가 평탄화된 형태로 뷰를 만들 수 없는 경우 (예를 들어, 메모리상에서 불연속적인 경우),
- torch.flatten은 입력 데이터의 복사본을 만들고,
- 그 복사본을 평탄화하여 반환합니다.
- 이는 원본 데이터와는 독립적인 새로운 메모리 할당을 의미합니다.
- 입력 텐서가 평탄화된 형태로 뷰를 만들 수 없는 경우 (예를 들어, 메모리상에서 불연속적인 경우),
- 뷰(view) 반환:
- np.flatten은 항상 copy가 이루어지지만, torch.flatten은 다르다.
>>> t = torch.tensor([[[1, 2],
... [3, 4]],
... [[5, 6],
... [7, 8]]]) # (2, 2, 2)
>>> torch.flatten(t) # (8)
tensor([1, 2, 3, 4, 5, 6, 7, 8])
>>> torch.flatten(t, start_dim=1)
tensor([[1, 2, 3, 4], # (2, 4)
[5, 6, 7, 8]])unsqueeze(input, dim)
- 복사 x
>>> x = torch.tensor([1, 2, 3, 4]) # (4,)
>>> torch.unsqueeze(x, 0) # (1, 4)
tensor([[ 1, 2, 3, 4]])
>>> torch.unsqueeze(x, 1) # (4, 1)
tensor([[ 1],
[ 2],
[ 3],
[ 4]])squeeze(input, dim=None)
- 복사 x
- dim
- 지정 안하면, 1 size인 모든 차원 제거.
- 지정하면, 해당 지정 차원이 1 size이면 제거.
>>> x = torch.zeros(2, 1, 2, 1, 2)
>>> x.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x)
>>> y.size()
torch.Size([2, 2, 2])
>>> y = torch.squeeze(x, 0)
>>> y.size()
torch.Size([2, 1, 2, 1, 2])
>>> y = torch.squeeze(x, 1)
>>> y.size()
torch.Size([2, 2, 1, 2])
>>> y = torch.squeeze(x, (1, 2, 3))
torch.Size([2, 2, 2])stack(tensors, dim=0, *, out=None)
- 복사 o
지정하는 차원에 새로운 차원이 생긴다=차원의 갯수가 증가한다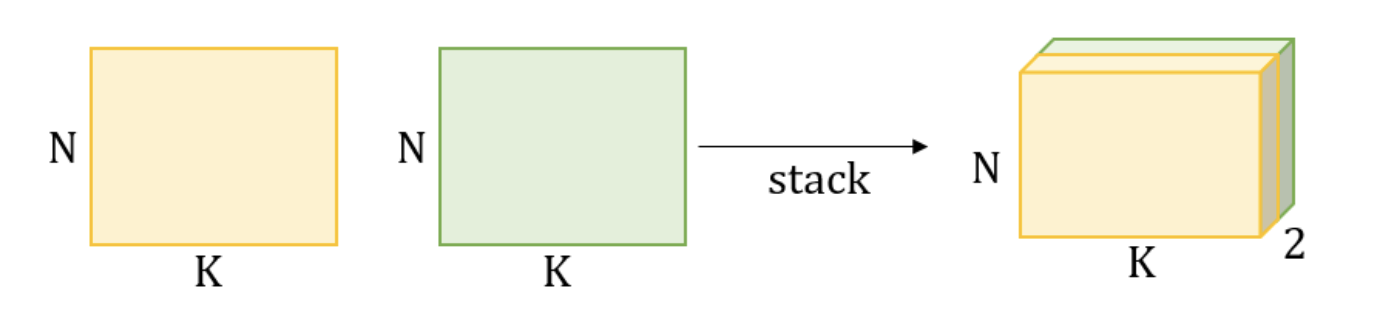
cat(tensors, dim=0, *, out=None)
- torch.cat() can be seen as an inverse operation for
torch.split()andtorch.chunk(). - dim에는 int만 올 수 있고, dim을 제외한 tensor들의 차원은 같아야 한다.
- 복사 o
차원의 갯수는 유지되고 해당 차원이 늘어난다.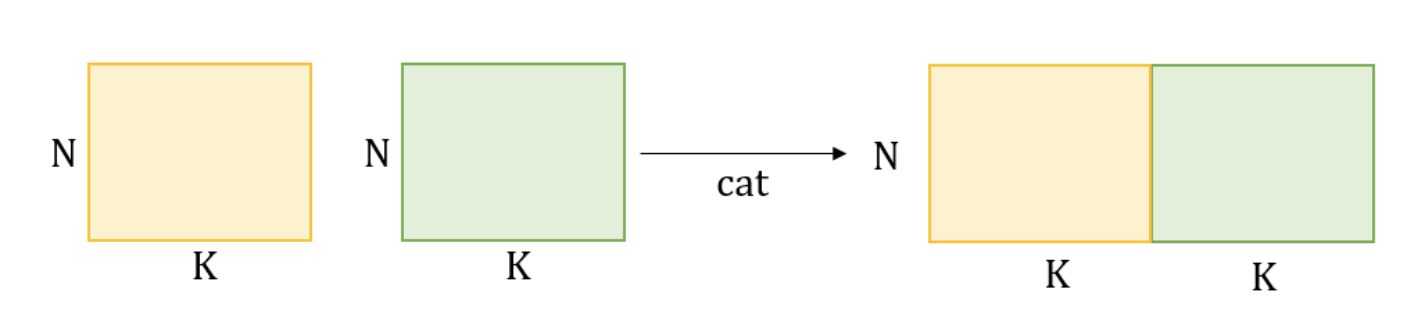
>>> x = torch.randn(2, 3) # (2, 3)
>>> x
tensor([[ 0.6580, -1.0969, -0.4614],
[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), dim=0) # (6, 3)
>>> torch.cat((x, x, x), dim=1) # (2, 9)split(tensor, split_size_or_sections, dim=0)
- 복사 x
- Splits the tensor into chunks. Each chunk is a view of the original tensor.
- 인자
- split_size_or_sections:
intorlist[int]- integer 인 경우
- split into equally sized chunks (if possible).
- Last chunk will be smaller if the tensor size along the given dimension dim is not divisible by split_size.
- list인 경우
- then tensor will be split into len(split_size_or_sections) chunks with sizes in dim according to split_size_or_sections.
- integer 인 경우
- dim (int) = 0
- dimension along which to split the tensor.
- 기본값이 0.
- split_size_or_sections:
>>> a = torch.arange(10).reshape(5, 2)
>>> a
tensor([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> torch.split(a, 2)
(tensor([[0, 1],
[2, 3]]),
tensor([[4, 5],
[6, 7]]),
tensor([[8, 9]]))
>>> torch.split(a, [1, 4])
(tensor([[0, 1]]),
tensor([[2, 3],
[4, 5],
[6, 7],
[8, 9]]))chunk(input, chunks, dim=0)
- 복사 x
>>> torch.arange(11).chunk(6)
(tensor([0, 1]),
tensor([2, 3]),
tensor([4, 5]),
tensor([6, 7]),
tensor([8, 9]),
tensor([10]))
>>> torch.arange(12).chunk(6)
(tensor([0, 1]),
tensor([2, 3]),
tensor([4, 5]),
tensor([6, 7]),
tensor([8, 9]),
tensor([10, 11]))
>>> torch.arange(13).chunk(6)
(tensor([0, 1, 2]),
tensor([3, 4, 5]),
tensor([6, 7, 8]),
tensor([ 9, 10, 11]),
tensor([12]))
새로운 것이 들어오면 이미 있는 것과 충돌을 시도하라.