문제

첫번째 시도
풀이
야근 지수는 각 일의 제곱으로 쌓이기 때문에 각 작업의 작업량을 낮춰야 한다.
그러므로 n이 하나 없앨 때마다(한 시간이 지날 때마다) works에서 가장 큰 수에서 1을 뺀다.
그 후에 남은 works들의 각각의 값의 제곱을 더한 값을 반환한다.
코드
import java.util.*;
import java.util.stream.*;
class Solution {
public long solution(int n, int[] works) {
long answer = 0;
for (int i = 0; i < n; i ++) {
// max 값 찾기
int idx = findMaxIndex(works);
if (works[idx] <= 0) {
break;
}
works[idx] --;
}
for (int i = 0; i < works.length; i ++) {
answer += works[i] * works[i];
}
return answer;
}
private int findMaxIndex (int[] works) {
return IntStream.range(0, works.length)
.reduce((i, j) -> works[i] > works[j] ? i : j)
.orElse(-1);
}
}결과
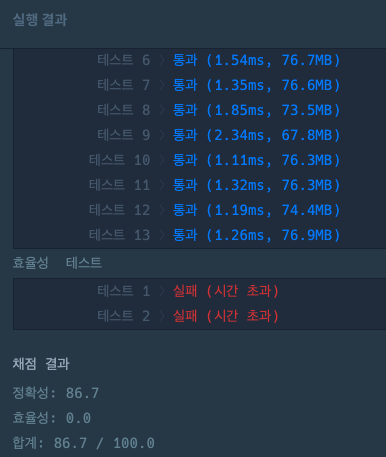
문제는 모두 맞았으나 효율성에서 모두 시간 초과가 떴다.
두번째 시도
풀이
배열을 정렬한다.
그렇게 하면 마지막 수가 무조건 가장 큰 수이므로 마지막 수를 1만큼 뺀다.
n이 0이 될 때까지 위를 반복한다.
n이 0이 되면 남은 수들을 각각 제곱해서 더한다.
코드
import java.util.*;
class Solution {
public long solution(int n, int[] works) {
long answer = 0;
int len = works.length;
for (int i = 0; i < n; i ++) {
Arrays.sort(works);
if (works[len-1] <= 0) {
return 0;
}
works[len-1] --;
}
for (int i = 0; i < len; i ++) {
answer += works[i] * works[i];
}
return answer;
}
}결과
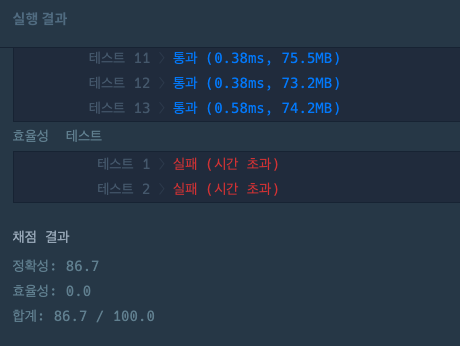
두 번째 시도 또한 문제는 모두 맞았으나 효율성에서 모두 시간 초과가 떴다.
세번째 시도
풀이
위와 같은 방식으로 안되어서 여러 가지를 찾아보다가 우선순위 큐에 대해서 알게 되었다.
우선순위 큐를 이용하면 자동으로 내림차순으로 정렬이 되어 시간이 훨씬 줄어든다.
위와 같은 방식이지만 정렬을 뺀 방식으로 코드를 구현했다.
코드
import java.util.*;
class Solution {
public long solution(int n, int[] works) {
long answer = 0;
PriorityQueue<Integer> pq = new PriorityQueue<>(Collections.reverseOrder());
for (int work : works) {
pq.offer(work);
}
for (int i = 0; i < n; i++) {
int maxWork = pq.poll();
if (maxWork <= 0) {
break;
}
pq.offer(maxWork - 1);
}
while (!pq.isEmpty()) {
int work = pq.poll();
answer += (long) work * work;
}
return answer;
}
}결과
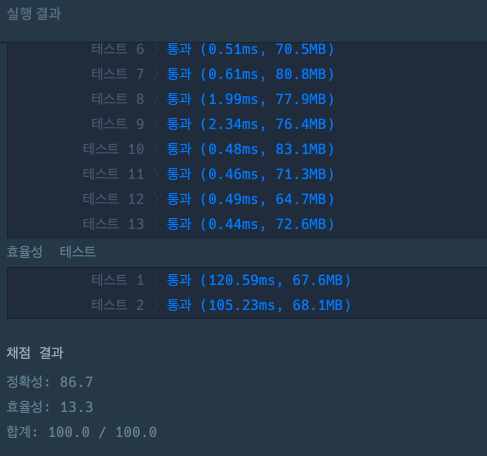
느낀 점
시간 초과를 넘기지 않는 방법은 점점 더 어려워지고 있고 이에 따라서 정말 다양한 자료구조와 알고리즘에 대해 배우고 알게 되는 것 같다.

돈 많은 백수가 꿈인 백엔드 개발자 지망생