Kafka ISR 설정 이슈 - NotEnoughReplicasException, NotLeaderOrFollowerException, OutOfOrderSequenceException
이슈 해결
개요
평화롭던 어느 날 오후, 에러 알람방에 아래와 같은 에러가 발생했다.
org.apache.kafka.common.errors.NotEnoughReplicasException:
Messages are rejected since there are fewer in-sync replicas than required.org.apache.kafka.common.errors.NotLeaderOrFollowerException:
For requests intended only for the leader, this error indicates that the broker is not the current leader. For requests intended for any replica, this error indicates that the broker is not a replica of the topic partition.org.apache.kafka.common.errors.OutOfOrderSequenceException:
The broker received an out of order sequence number.NotEnoughReplicasException
> ISR 수가 min.insync.replicas보다 적을 때 브로커가 쓰기를 거부
NotLeaderOrFollowerException
> 리더 재선출 과도기에 구버전 메타데이터로 잘못된 브로커에 요청
OutOfOrderSequenceException
> 리더 교체 후 새 리더가 기존 sequence를 모르는 상태에서 이어서 전송
원인
토픽 설정 (가장 큰 원인)
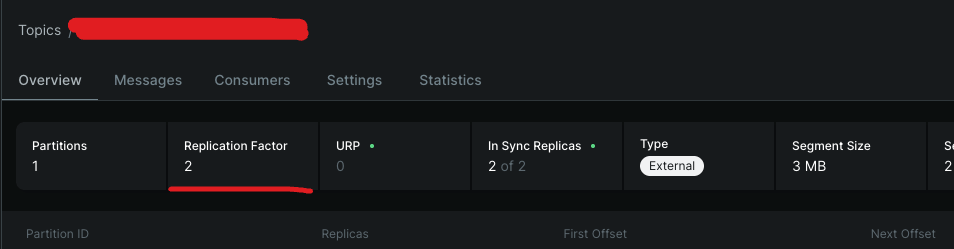
일반적으로 운영환경에서는 고갸용성 (HA, High Availability) 를 위해
Replication Factor = 3, min.insync.replicas = 2 로 설정한다.
이렇게 설정함으로써 1대의 브로커가 맛탱이 가더라도, 최소 ISR (2) 를 만족하며 자동으로 장애 복구를 기대할 수 있다.
하지만! 우리의 설정을 보니 Replication Factor = 2, min.insync.replicas = 2 로 설정되어 있었다. 그래서 브로커 1대가 맛탱이 갔을 때, 최소 ISR (2) 를 만족하지 못해 에러가 발생했다.
브로커 네트워크 순단
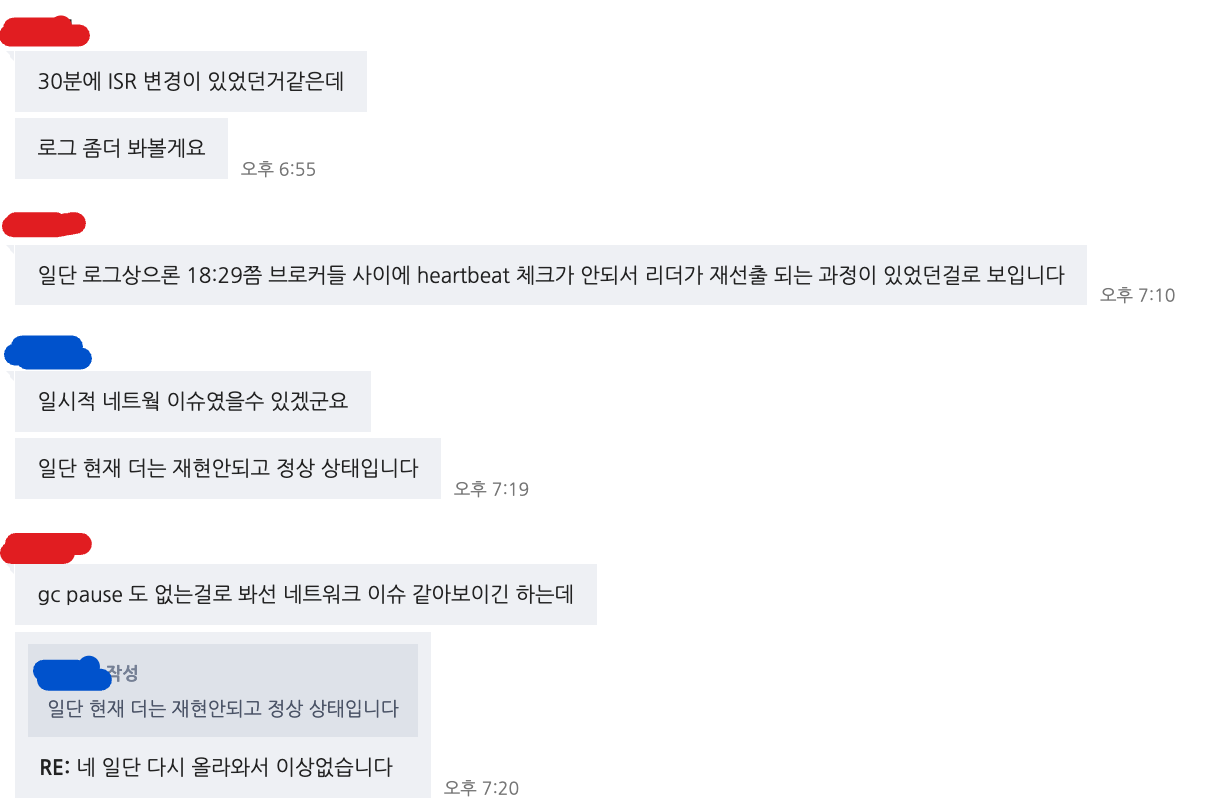
사실 실제로 브로커가 맛탱이 간거는 아니었고, 데봅스의 분석 결과 브로커의 일시적인 네트워크 순단이었다고 한다.
그러더라도, Replication Factor = 3 설정이 되어있었다면 이런 에러가 발생하진 않았을텐데..
조금 더 상세한 원인
NotEnoughReplicasException
ISR 구조
replication.factor = 2 (이번 케이스)
min.insync.replicas = 2 (이번 케이스)
파티션 0
├── 브로커 1 (리더) ← ISR
└── 브로커 2 (팔로워) ← ISR
ISR = [브로커1, 브로커2] → ISR 수(2) >= min.insync.replicas(2) → 정상발생 흐름
정상 상태
ISR = [브로커1, 브로커2]
↓
네트워크 순단 발생
↓
브로커2가 브로커1과 동기화 못함
↓
브로커2가 ISR에서 이탈
↓
ISR = [브로커1]
↓
ISR 수(1) < min.insync.replicas(2)
↓
브로커1(리더): "ISR 수가 부족해서 쓰기 거부할게"
↓
NotEnoughReplicasException
↓
네트워크 복구 → 브로커2 ISR 재합류
↓
ISR = [브로커1, 브로커2]
↓
재시도 성공Retry 가 가능한 이유
브로커가 쓰기를 거부한 것뿐
메시지 자체는 아직 안 보내진 상태
↓
delivery.timeout.ms 안에 ISR 회복되면
↓
재시도 성공 → 유실 없음단, 이번 케이스처럼 replication.factor=2, min.insync.replicas=2 이면 브로커 1대만 순단나도 즉시 에러가 나서 재시도 성공 가능성이 낮다.
NotLeaderOrFollowerException
프로듀서는 브로커에 메시지를 보내기 전에 메타데이터를 캐싱한다.
메타데이터 구조
프로듀서 내부 메타데이터 캐시
└── {Kafka Topic}
├── partition 0 → 브로커 1 (리더)
├── partition 1 → 브로커 2 (리더)
└── partition 2 → 브로커 3 (리더)발생 흐름
정상 상태
프로듀서: "partition 0 리더는 브로커 1이네" (캐시 기준)
↓
네트워크 순단 발생
↓
브로커 1이 ISR 이탈 → 브로커 2가 새 리더로 선출
↓
근데 프로듀서 캐시는 아직 갱신 안 됨
↓
프로듀서: "브로커 1한테 보내면 되지" (구버전 캐시 기준)
↓
브로커 1: "나 지금 리더 아닌데 왜 나한테 보내?"
↓
NotLeaderOrFollowerException
↓
프로듀서가 메타데이터 강제 갱신
↓
"아 브로커 2가 새 리더구나"
↓
브로커 2로 재시도 → 성공메타데이터 갱신 관련 설정
# 주기적으로 메타데이터 갱신하는 주기 (기본 5분)
metadata.max.age.ms=300000
# 에러 발생 시 메타데이터 갱신 후 재시도 대기 시간 (기본 100ms)
retry.backoff.ms=100metadata.max.age.ms 가 길수록 리더가 바뀐 걸 늦게 알아채서 이 에러가 더 자주 발생할 수 있다.
Retry 가 가능한 이유
브로커가 "나 리더 아니야" 라고 알려줌
↓
프로듀서가 메타데이터 갱신
↓
올바른 리더 브로커로 재시도
↓
정상 처리OutOfOrderSequenceException
Idempotence 구조
프로듀서
├── producerId: 226060 (브로커가 발급)
├── epoch: 0
└── sequence: 0, 1, 2, 3 ... (메시지마다 1씩 증가)
브로커(리더)
└── producerId 226060의 마지막 sequence 추적 중
"지금까지 8893까지 받았으니 다음은 8894 와야 해"발생 흐름
정상 상태
브로커1(리더): producerId=226060, lastSequence=8893
↓
네트워크 순단 → NotEnoughReplicasException 발생
↓
브로커1이 ISR 이탈 → 브로커2가 새 리더로 선출
↓
브로커2는 팔로워였을 때 sequence 8893까지 동기화가
완료됐는지 보장 못함 (순단 중에 동기화가 끊겼으니까)
↓
프로듀서: "다음 sequence 8894 보낼게" (이어서 전송)
↓
브로커2(새 리더): "producerId 226060?
lastSequence가 뭔지 모르겠는데
8894가 맞는 번호인지 확인 불가"
↓
OutOfOrderSequenceException
↓
fatal 에러 → 프로듀서 인스턴스 종료
↓
Spring Kafka가 새 프로듀서 인스턴스 재생성
(새 producerId, epoch, sequence=0 부터 시작)
↓
그 사이 전송 못한 메시지 유실Retry 가 불가능한 이유
재시도를 해도 브로커는 여전히
"이 sequence가 맞는지 모르겠어" 상태
↓
몇 번을 재시도해도 동일한 에러
↓
프로듀서 재생성만이 해결책멱등성 관련 설정
enable.idempotence=true 설정일 때에만 발생하지만, 우리는 Kafka3.8 을 사용하기에 기본값이 true이다. (kafka 3.0 이후부터는 true가 기본값. 아래는 false 가 기본값)
후속 조치
누락된 토픽 재처리
NotEnoughReplicasException
Retries 설정을 통해 재처리 가능
NotLeaderOrFollowerException
Retries 설정을 통해 재처리 가능
OutOfOrderSequenceException
해당 에러는 Fatal 에러로, 자체 재처리되지 못한다.
enable.idempotence=true 상태에서 seq가 어긋났다는 건 데이터 정합성 자체가 깨진 상황이기 때문.
재시도를 하더라도 브로커가 seq를 맞출 수 없기 때문에 kafka-clients가 "이 프로듀서는 더 이상 신뢰할 수 없다" 고 판단하고 에러를 던진다.
따라서, 새 프로듀서 인스턴스를 재생성하여 PID (Producer ID), epoch 를 재발급해서 처리해야하지만, 그 사이에 토픽이 유실될 수 있다.
> Spring Kafka는 이걸 자동으로 해주긴 한다. (물론 토픽 유실 가능성 있음)
복구 이후 자체적으로 토픽을 재전송 하든가, 별도의 아웃박스 패턴을 통한 재처리가 필요하다.
토픽 설정
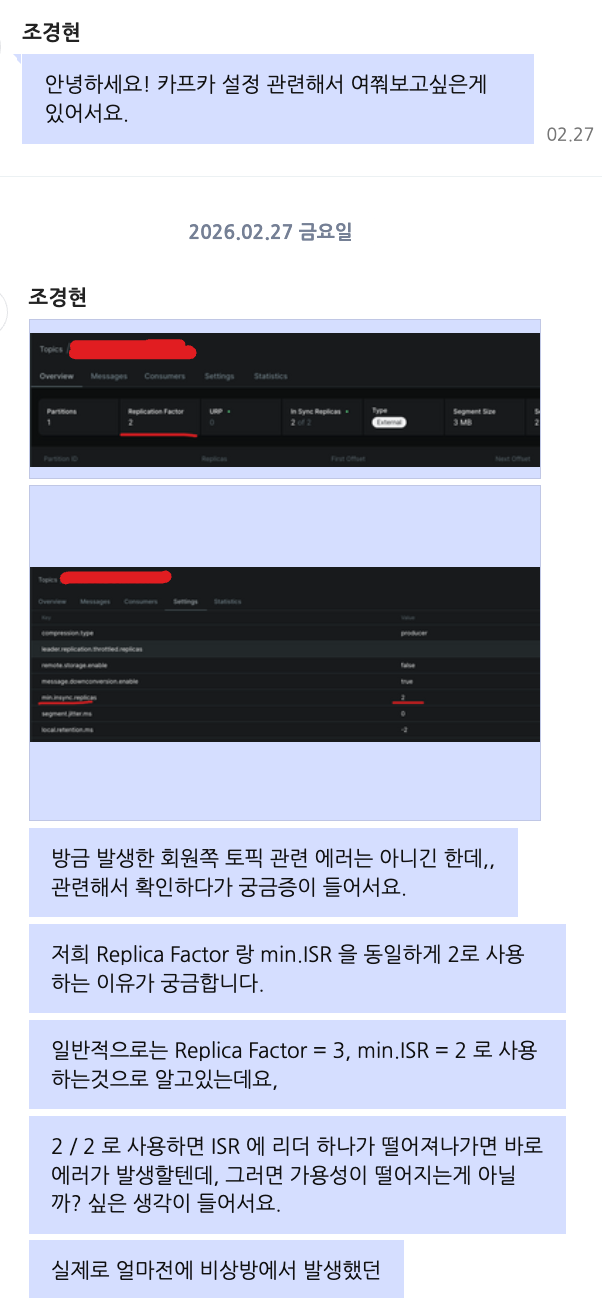
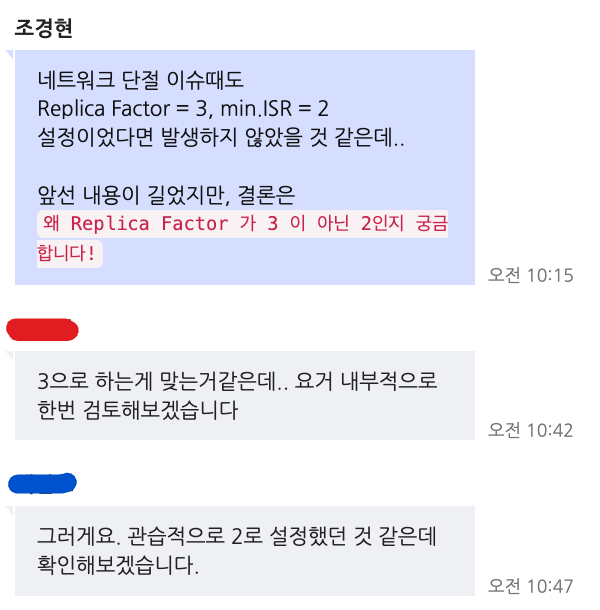
데봅스 팀에 요청해서 Replication Factor 를 3으로 변경했다.
