
이번 글은 카산드라를 구경할 예정이다. 간단하면서도 내가 중요하다고 판단되는 부분은 상세히 살펴볼 예정이다.
목차
- 카산드라란?
- 카산드라 특징
- 카산드라 장단점
- 카산드라 구조 살펴보기
카산드라란?
카산드라는 분산화 환경에서 빛을 내는 NoSql이다.
- 카산드라는 대용량 데이터를 관리하기 위해서 설계된 시스템이다.
- 단일 장애 점이 존재하지 않는다.
- 임계점을 넘는 대용량 데이터일 경우, MongoDB 보다 높은 성능을 가진다.
카산드라 특징
-
카산드라는 CQL(Cassandra Query Language)를 지원한다. CQL은 SQL과 매우 흡사한 문법구조를 가지고 있다.
-
분할된 키를 지향하는 쿼리를 가지고 있다.
-
유연한 스키마 구조를 구성할 수 있다.
-
링 구조를 가지고 있으며, P2P를 지원한다.
-
카산드라는 선형 확장을 제공한다.
카산드라 Keyword 살펴보기
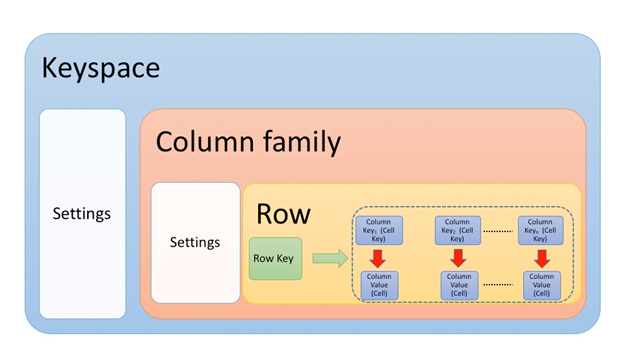
-
Keyspace : 여러가지 Table이 존재할 수 있다. 데이터 세트 구성을 정의하는 것이다.
-
Table : 어떠한 데이터에 대한 스키마이다.
-
Partition : 모든 행에 있어야하는 기본 키의 필수 부분을 정의하는 것이다.
-
Row : 파티션 키 및 클러스터링 키로 구성된 데이터의 모음이다. 기본 키로 식별 된다.
-
Column : 하나의 Row에는 여러가지 Column으로 구성된다. 하나의 데이터라고 생각하면 된다.
카산드라 장단점
카산드라의 장점을 살펴보자.
장점
분산화 및 집중화
- 카산드라는 DB를 분산화하여 여러 인스턴스에서 구동할 수 있다. 사용자는 분산화되어있는 여러가지 DB를 하나의 DB처럼 조작할 수 있다.
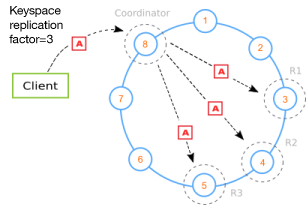
-
카산드라는 기존의 다른 DB처럼 프라이머리-레플리카 형식으로 구성되어있지 않다.
-
각 노드는 모두 프라이머리이다. 각 노드들은 p2p 프로토콜을 통한 동기화 작업을 수행한다.
확장성
위와 같은 구조 덕분에 확장에 있어서 유리하다. 이유는 동기화 및 위치에 따라 고민하지 않아도 되기 때문이다.
고가용성과 결함 허용
한 개의 노드에 장애가 발생하면 클러스터에서 탐지 및 교체 그리고 복원 기능을 가지고 있다.
카산드라 단점
- 어렵다.
- 복잡한 쿼리는 불가능하다.
- 자동화 처리 힘들다.
카산드라 구조 살펴보기
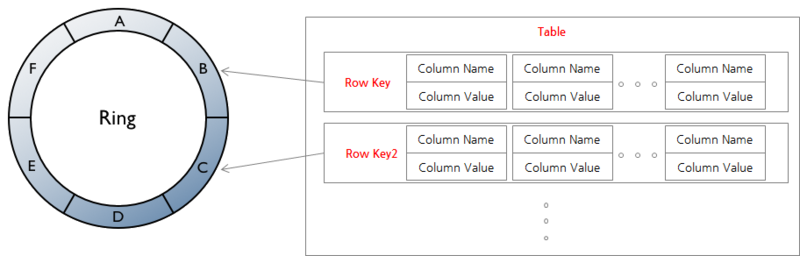
카산드라는 위와 같이 링구조를 가지고 있다. A, B, C, D, E .. 는 노드를 가리킨다. 데이터는 각 노드에 분산화되어 저장된다.
데이터에 접근을 하기 위해서는 파티션 키를 이용한 일련의 작업(hash)을 통해서 노드를 발견하고 접근한다.
노드가 링에 참여하면 카산드라 conf/cassandra.yaml의 설정을 통해서 각 노드마다 고유 해시 범위를 부여받는다.
데이터가 새롭게 들어오면, 해당 데이터의 파티션 키를 해시 값을 구하여 알맞는 노드에 데이터를 저장한다. 이 때에 계산된 해시 값을 "Token"이라고 부른다.
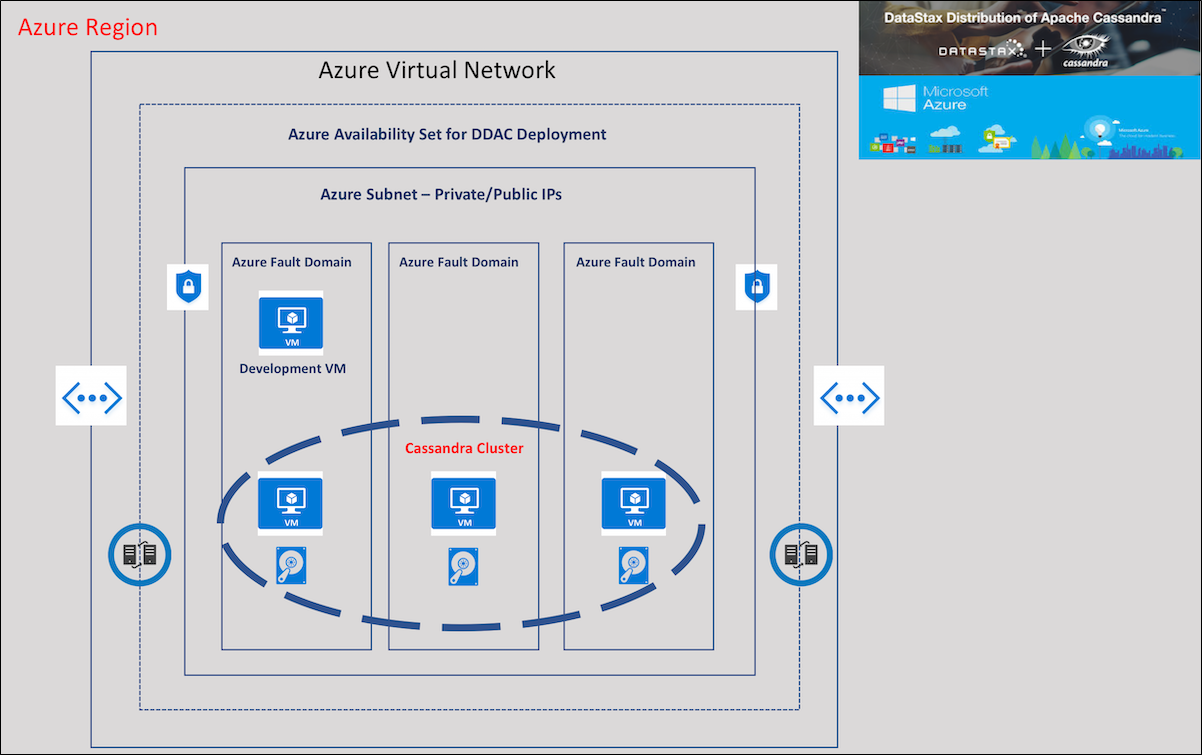
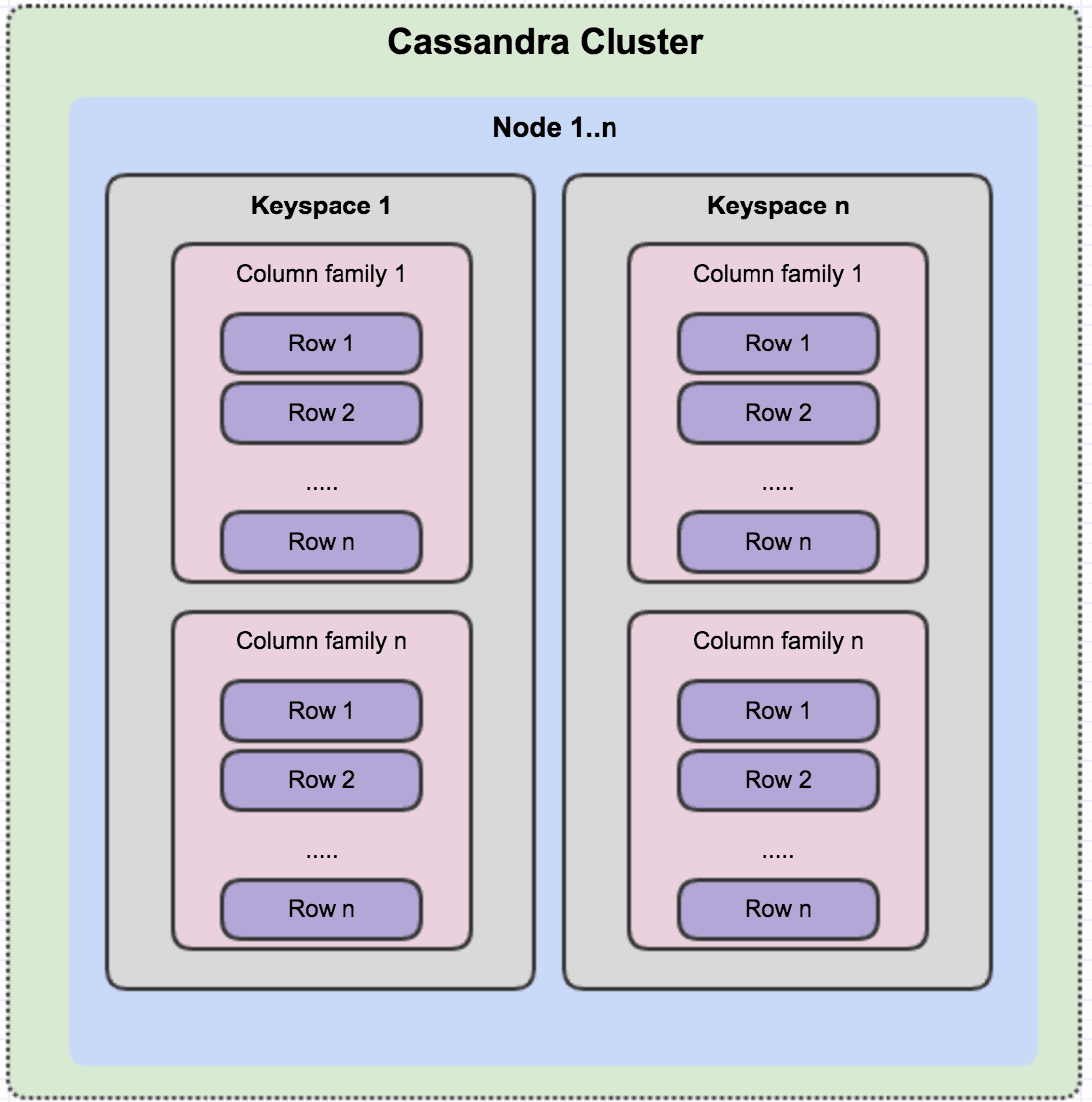
위와 같은 기능과 장점 덕분에 위의 그림처럼 Cassandra Cluster를 구성할 수 있다.
참고
