배열 커서로 연결 리스트 만들기
이전에서는 정리한 포인터를 이용한 연결리스트는 노드의 삽입, 삭제를 데이터 이동 없이 수행한다라는 장점이 있지만 삽입, 삭제를 수행할때마다 노드용 객체를 위한 메모리 영역을 확보하고 해제하는 과정이 필요합니다.
그러므로, 프로그램 실행 중에 데이터 수가 크게 바뀌지 않는 경우, 또는 데이터 수의 최댓값을 미리 알 수 있는 경우에는 배열을 사용해 연결리스트를 효율적으로 이용할 수 있습니다.
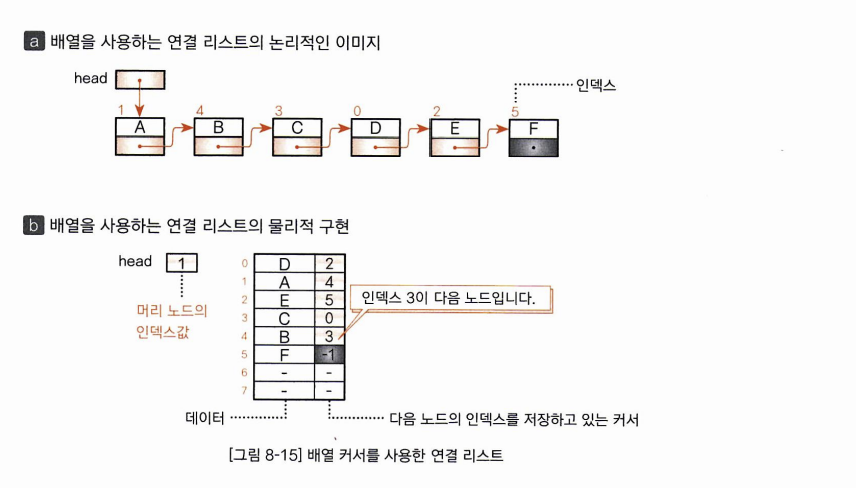
여기서 다음 노드를 가리키는 뒤쪽 포인터는 다음 노드에 대한 포인터가 아니라 다음 노드가 들어있는 배열 요소의 인덱스입니다. 이 인덱스 포인터를 커서라고 합니다.
꼬리 노드의 커서는 배열의 인덱스가 될 수 없는 값인 -1로 합니다. 머리 노드를 나타내는 head도 커서이기 때문에 머리 노드 A가 들어있는 곳인 인덱스 1이 head값이 됩니다.
배열의 비어 있는 요소 처리하기
위에서 정리한 연결 리스트에서 삭제한 노드 관리에 대해서 살펴보도록 하겠습니다.
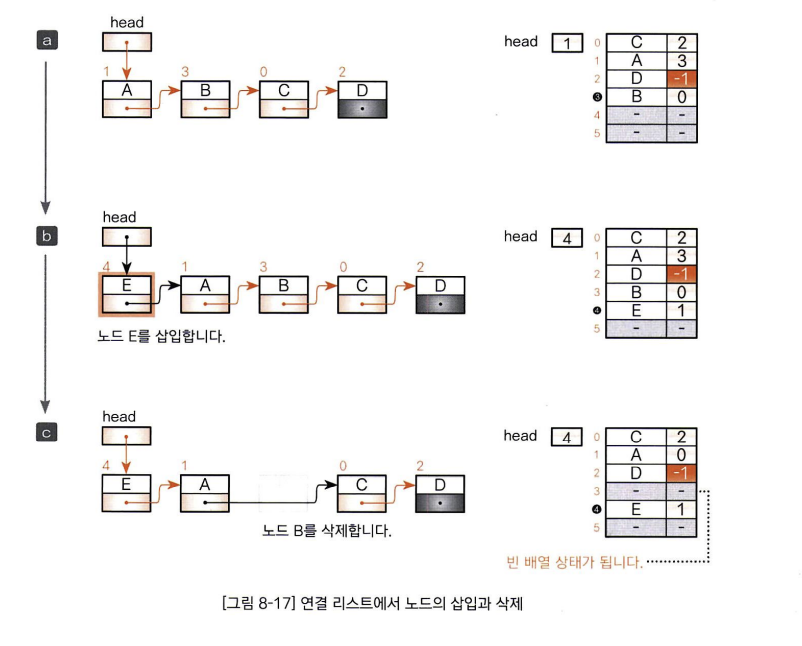
- 연결 리스트에 4개의 노드가 A -> B -> C -> D 순서로 나열되어 있습니다.
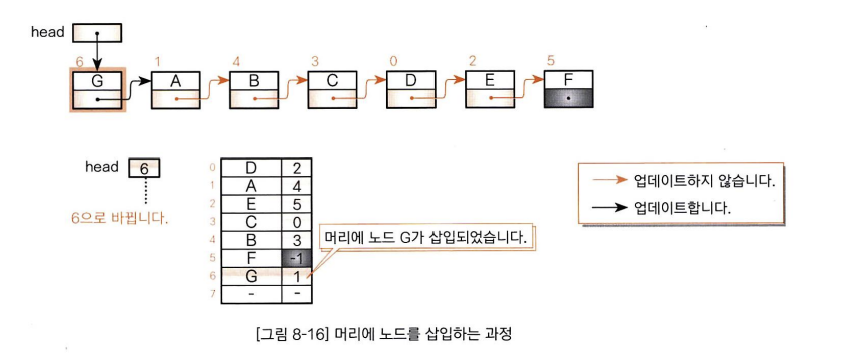
- 연결 리스트의 머리에 노드 E를 삽입한 다음에 인덱스가 4인 위치에 노드 E가 들어있습니다. 삽입한 노드에 배열 안에서 가장 고리 쪽에 있는 인덱스 위치에 들어가 있지만 연결리스트의 꼬리에 추가한 것은 아닙니다.(배열 안에서의 물리적인 위치 관계와 연결 리스트의 논리적인 순서 관계가 같은 것은 아님)
- 머리부터 3번째 노드 B를 삭제하면 3번째 레코드는 비어있는 상태가 됩니다.
그런데 삭제를 여러 번 반복하면 배열 안은 빈 레코드투성이가 됩니다. 삭제한 레코드가 하나라면 그 인덱스를 어떤 변수를 넣어두고 관리함으로써 그 레코드를 쉽게 재사용할 수 있습니다. 그러나 실제로는 여러 레코드를 삭제하는 경우가 많으므로 단순히 해결이 되지는 않습니다.
프리 리스트 살펴보기
삭제한 여러 레코드를 관리하기 위해 그 순서를 넣어두는 연결 리스트인 프리리스트를 사용합니다.
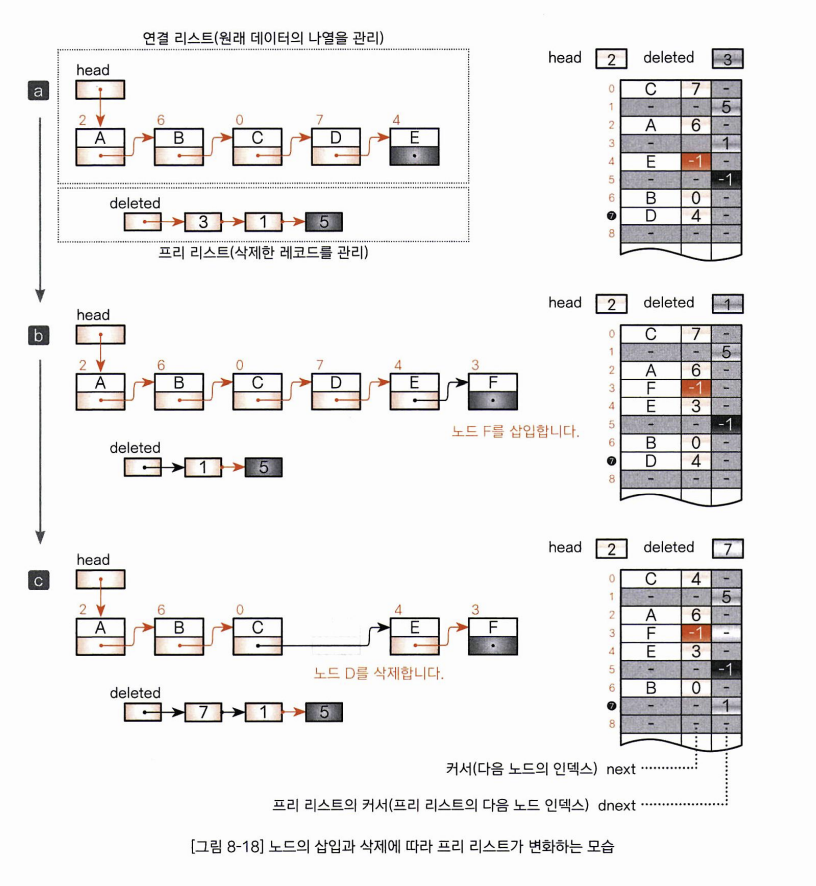
- 연결 리스트에 노드가 저장되어 있습니다. max값은 7이며 8이후의 레코드는 사용하지 않았습니다. 그리고 레코드 1,3,5는 빈 레코드이고 프리 리스트는 3->1->5 입니다. 데이터를 저장한느 연결 리스트 외에 프리 리스트를 위한 공간을 추가하여 삭제한 레코드까지 관리하는 연결 리스트를 나타내고 있습니다.
- 연결 리스트 꼬리에 노드 F를 삽입한 이후의 상태로 노드의 삽입하는 위치는 삽입하기 전 프리 리스트의 모리 노드인 인덱스 3입니다. 노드 F를 3번째 레코드에 저장하고 프리리스트에서 머리노드 3을 삭제하여 1-> 5의 상태로 만듭니다. 이처럼 프리 리스트에 빈 레코드가 등록되어 있는 한 새 레코드를 얻기 위해 max 값을 증가시킨 다음 그 레코드에 데이터를 저장하는 일은하지 않습니다. 그러므로 max값은 7입니다.
- 노드 D를 삭제한 다음상태로 삭제한 노드 D의 배열인덱스가 7이므로 프리리스트의 머리로 등록합니다 그 결과 프리리스트는 7->1->5가 됩니다.
원형 이중 연결 리스트 만들기
꼬리 노드가 머리 노드를 가리키는 연결 리스트를 원형 리스트라고 합니다. 원형 리스트는 고리모양으로 나열된 데이터를 정리할 때 알맞은 자료구조입니다.
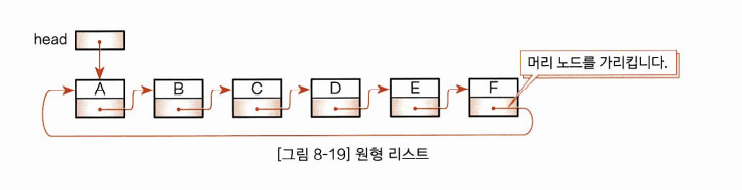
보통의 연결 리스트와 다른 점은 꼬리 노드의 다음 노드를 가리키는 포인터가 NULL이 아니라 머리 노드의 포인트라는 점입니다.
이중 연결 리스트 살펴보기
연결 리스트의 가장 큰 단점은 다음 노드는 찾기 쉽지만 앞쪽 노드는 찾기 어렵다는 점입니다. 이런 단점을 개선한 자료구조가 이중 연결 리스트입니다.
각 노드에는 다음 노드에 대한 포인터와 앞쪽 노드에 대한 포인터가 주어집니다.

