병합정렬
병합정렬은 배열을 앞부분과 뒷부분 둘로 나누어 각각 정렬한 다음 병합하는 작업을 반복하여 정렬하는 알고리즘입니다.
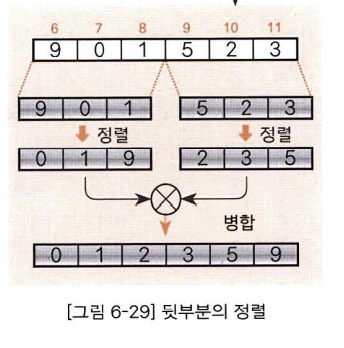
정렬을 마친 두 배열의 병합 살펴보기
우선 정렬을 마친 배열 A와 배열 B를 병합하여 배열 C에 저장하는 과정입니다.
- 우선 배열 A에서 선택한 요소와 배열 B에서 선택한 요소를 비교하여 작은 쪽 값을 C배열에 저장합니다. 그 후 배열 작은요소가 들어있던 배열과 배열 C의 커서를 한 칸씩 나가는 작업을 반복합니다.
- 그 후 배열 A에 남아있는 요소들을 C에 이동시킵니다.
- 마지막으로 배열 B에 남아있는 요소들을 C로 이동시킵니다.
병합 정렬 구현하기
정렬을 마친 배열의 병합을 응용하여 분할 정복법에 따라 정렬하는 알고리즘을 병합정렬이라고 합니다.
배열을 앞부분과 뒷부분으로 나누어서 정렬을 합니다.

이 때 앞부분과 뒷부분의 요소를 바로 정렬하지 않고 병합정렬을 다시 적용합니다.
힙 정렬
힙 정렬은 힙을 사용하여 정렬하는 알고리즘입니다. 여기서 힙은 '부모의 값이 자식값보다 항상 크다' 라는 조건을 만족하는 완전 이진트리를 말합니다.
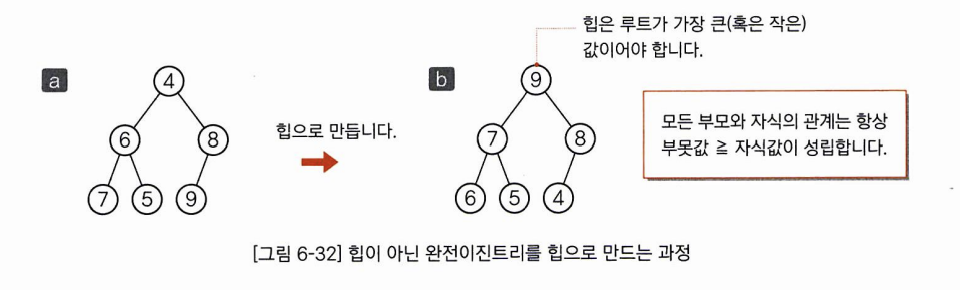
그림 처럼 a를 힙으로 만들게 되면 b와같은 상태가 됩니다. b에서 부모와 자식 관계는 항상 부모>= 자식 입니다. 따라서 힙의 가장 ㅜ이쪽에 있는 루트가 가증 큰 값입니다.
힙 정렬 알아보기
힙 정렬은 가장 큰 값이 루트에 위치하는 특성을 이용하는 정렬 알고리즘입니다. 구체적으로 살펴보면 아래와 같은 작업을 반복합니다.
- 힙에서 가장 큰 값인 루트를 꺼냅니다.
- 루트 이외의 부분을 힙으로 만듭니다.
위와 같은 과정에서 꺼낸 값을 늘어놓으면 배열은 정렬을 마치게 됩니다. 즉, 힙 정렬은 선택 정렬을 응용한 알고리즘으로, 힙에서 가장 큰 값인 루트를 꺼낸 뒤 남은 요소에서 다시 가장 큰 값을 구해야합니다.
루트를 없애고 힙 상태를 유지하기

힙에서 루트인 10을 꺼낸 후 비어있는 루트 위치로 힙의 마지막 요소인 1을 옯깁니다. 이때 방금 옮긴 1 이외에는 힙상태를 유지하고 있습니다.
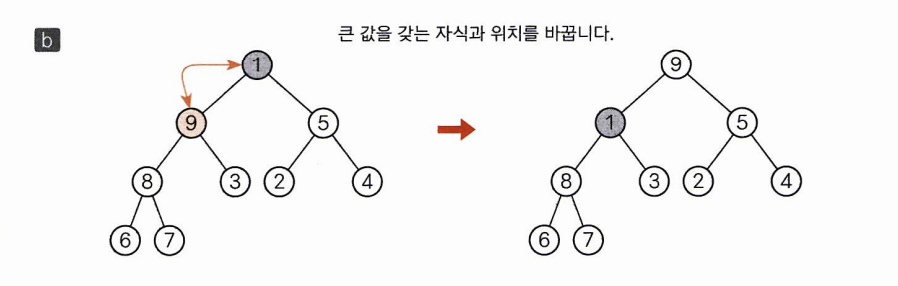
1을 다시 알맞은 위치로 보내기 위해서 자식의 9와 5 중 더 큰 값과 비교해서 자리를 바꿉니다.

위와 같은 과정을 반복해서 이번에는 8과 위치를 바꿉니다.
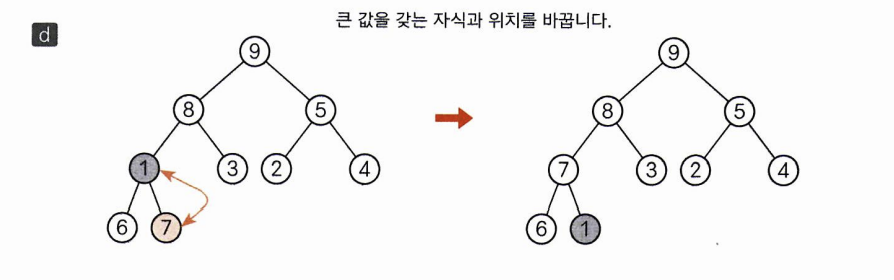
마지막으로 자식값과 비교해서 큰 값인 7과 자리를 바꾸게 됩니다.
이렇게 만든 트리는 힙상태를 유지하게 됩니다.
- 루트를 꺼낸다.
- 마지막 요소를 루트로 옮긴다.
- 자기보다 큰 값을 갖는 자식 요소와 자리를 바꾸며 아래로 내려가는 작업을 반복한다.
(이때 자식값이 작거나 잎에 다다르게되면 작업을 종료)

이를 정리하게 되면 위와 같은 과정을 거쳐서 정렬이 이루어지게 됩니다.
도수 정렬
요소의 대소관계를 판단하지 않고 빠르게 정렬할 수 있는 알고리즘입니다.
도수 정렬 알아보기
- 도수분포표 만들기
- 누적도수분포표 만들기
- 목표 배열 만들기
- 배열 복사하기
위와 같은 4단계로 이루어집니다.
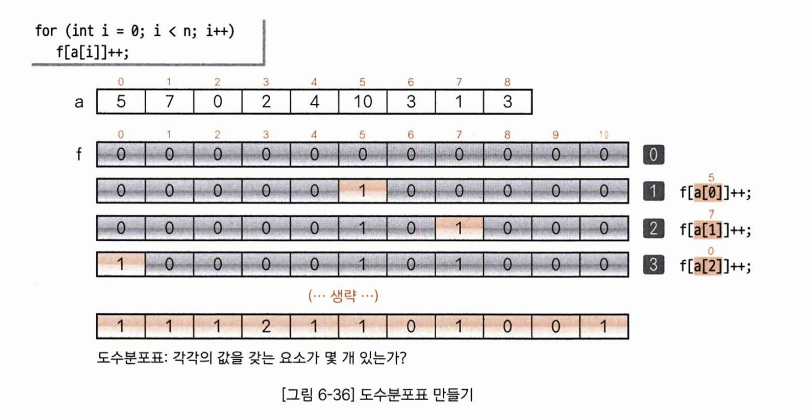
1. 도수분포표 만들기
배열을 바탕으로 각 점수에 해당하는 요소가 몇개인지를 나타내는 도수분포표를 작성합니다.
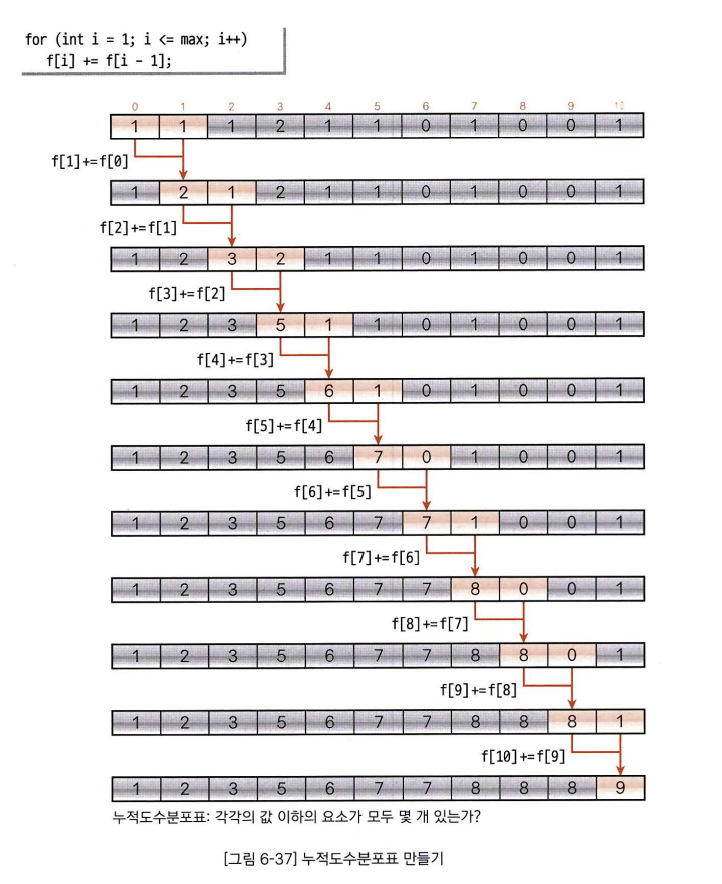
2. 누적도수분포표 만들기
이제 이 도수분포표를 바탕으로 누적한 값을 나타내는 누적도수분포표를 만들어야 합니다.
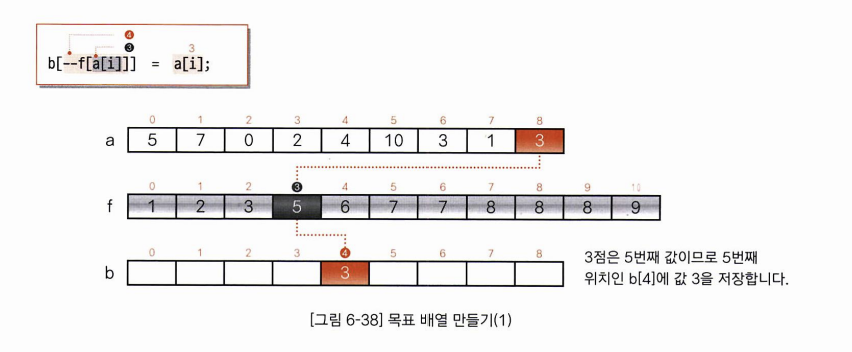
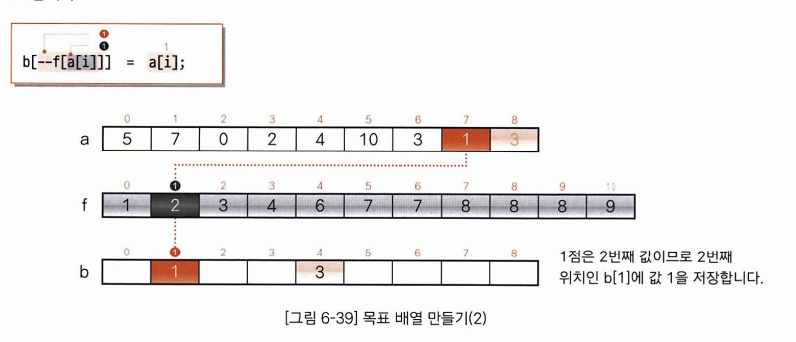
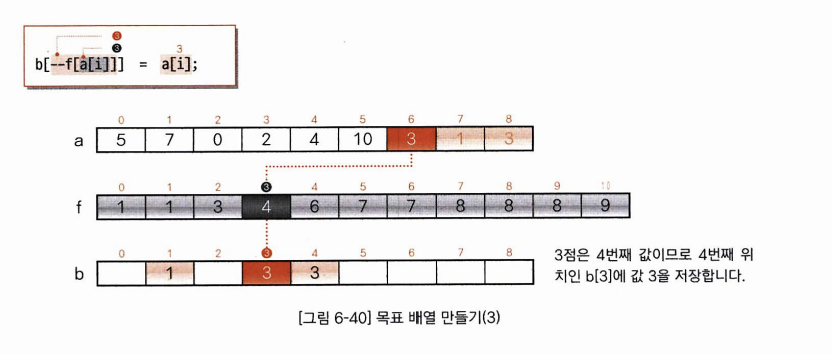
3. 목표 배열 만들기
각각의 요소들에서 이 요소들의 요소값과 누적도수분포표를 대조하여 정렬을 마친 배열을 만드는 일입니다.
4. 배열 복사하기
정렬을 끝났지만 정렬결과를 저장한 곳은 배열 b이기 때문에 이를 a로 복사해야합니다.
도수 정렬 알고리즘은 데이터를 비교, 교환하는 작업이 필요 없어 매우 빠르며 효율적인 알고리즘이지만, 도수분포표가 필요하기 때문에 데이터의 최소값과 최대값을 알아야 사용이 가능합니다.
