과정
-
입력 데이터를 스플릿이라는 조각으로 나눈다.
스플릿의 크기는 작을 수록 더 많은 수의 컴퓨터로 병렬적으로 처리할 수 있기 때문에 좋다.
하지만 너무 작으면 스플릿 관리와 맵 태스크 생성을 위한 오버헤드 때문에 잡의 실행 시간이 증가한다. 일반적으로 HDFS 블록의 기본 크기인 128MB가 적당하다고 알려져 있다. -
스플릿이 있는 곳에 맵 태스크에 할당한다. (스플릿의 위치에 대한 정보는 HDFS의 NameNode 들이 알고 있다. 주기적으로 DataNode 들이 데이터의 위치에 대한 정보를 NameNode 들에게 보고한다.)
이렇게 하는 이유는 코드의 실행이 실제 데이터가 있는 곳에서 이뤄지게 하기 위해서이다.
계산 노드와 데이터 노드를 같은 곳에 배치하여 데이터 지역성(Data Locality)을 취할 수 있다.
맵 태스크는 자신에게 할당된 스플릿을 읽으면서 새로운 키-값 쌍들을 만든다.
하나로 묶어서 처리해야 할 데이터들은 값이 되고,
그 값을 묶어주는 기준은 키가 된다.
이 과정에서 키-값 리스트를 출력한다.
맵 태스크는 리듀스 수만큼 파티션을 생성하고 출력값을 각 파티션에 분배한다.
한 파티션에 여러 키가 있을 수는 있지만, 하나의 키에 대한 데이터가 여러 파티션에 나뉘어지진 않는다. (생각해보면 당연하다. 다음 과정에서 같은 키대로 리스트를 만들어야 하기 때문) -
셔플 과정에선, 모든 맵에서 나온 키-값 리스트들을 서로 같은 키끼리 모아 http로 전달한다. 같은 키로 뭉쳐진 키-값 리스트들은 리듀스 태스크를 실행하는 컴퓨터로 각각 전달된다.
-
리듀스 태스크에선 <키-값> 리스트를 정렬(그룹화)해서 <키-값 리스트>로 만든다. 왜냐면 같은 키를 가지는 값이 여러개일 수도 있기 때문이다.
-
그리고 각 값 리스트를 분석하는 코드를 실행하여 각 키에 해당하는 최종 분석 결과를 출력한다. 리듀스 태스크는 일반적으로 모든 매퍼의 출력 결과를 입력으로 받기 때문에(3. 셔플의 결과), 데이터 지역성의 장점이 없다.
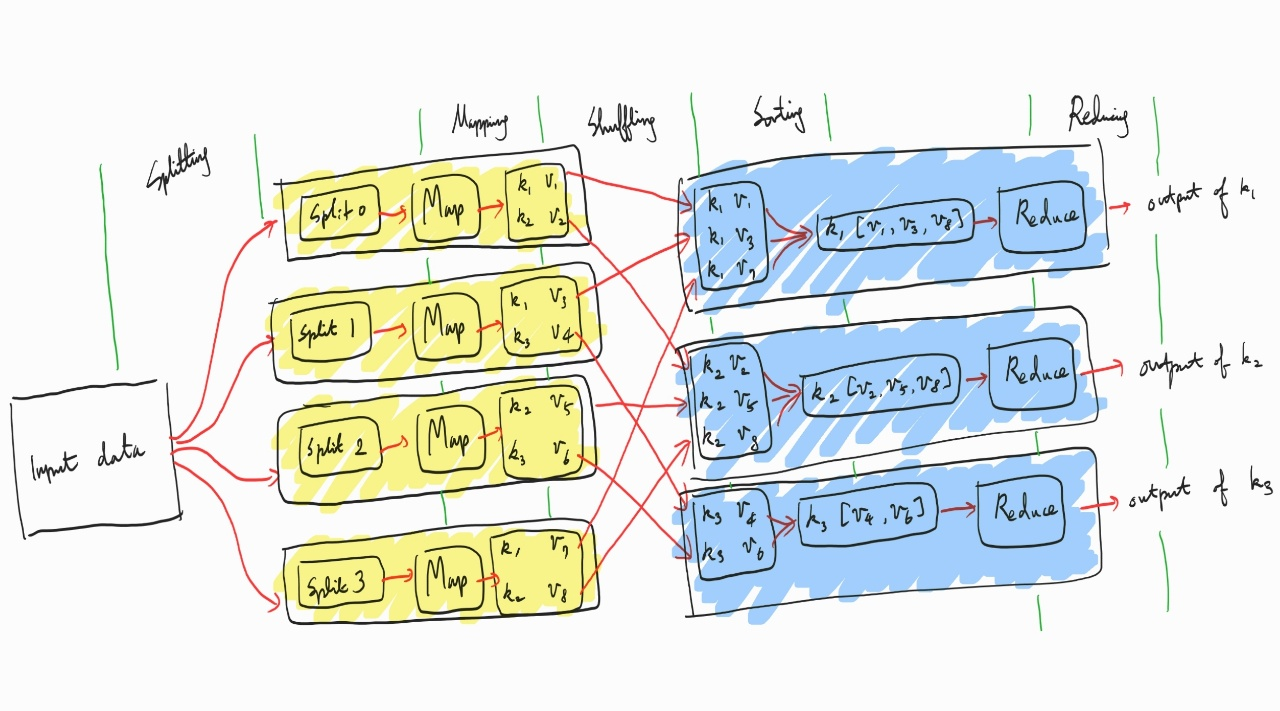
위 사진은 맵리듀스 과정을 설명하고 있다.
위 설명과 같은 순서대로
1. Splitting
2. Mapping
3. Shuffling
4. Sorting
5. Relaxing
이다.
노란색으로 배경이 칠해진 부분은 맵,
파란색으로 칠해진 부분은 리듀서이다.
맵은 데이터의 분석할 대상을 유형(키)별로 분류한다.
이는 분산처리를 쉽게 하기 위함이다.
별개의 키에 대한 데이터(값)는 관련성이 없으므로 병렬로 처리가 된다고 가정할 수 있다.
데이터에 대한 실질적인 분석이 이루어지는 곳은 리듀스 과정이다.
실적용
IntelliJ를 기반으로 한다.
NCDC의 레코드 데이터에서 연도별 최고 기온을 구해본다.
1. 데이터 준비
NCDC (National Climatic Data Center) 의 기상 데이터를 사용한다.
링크에서 1901.gz와 1902.gz 파일을 다운받는다.
링크 주소를 복사해서 wget 명령어로 다운 받을 수 있다.
해당 폴더에 다운로드과 완료됐는지 한 번 더 확인한다.
다운 받기를 완료했으면 gzip 명령어로 압축을 풀어준다.
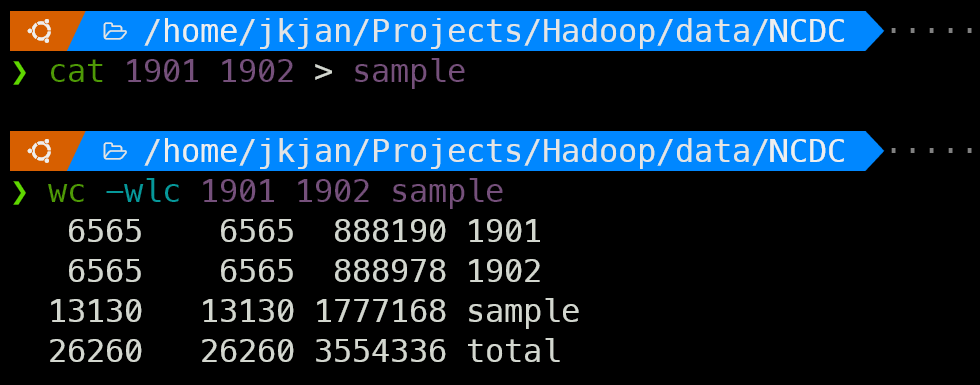
데이터를 합치기 위해 파이프 라인을 이용하여 sample.txt에 복사해준다.
wc 명령어로 확인한 결과 올바르게 합쳐졌음을 알 수 있다.
2. 의존성 추가
의존성 관리를 위해 maven 으로 프로젝트를 생성한다.
pom.xml의 <dependencies> 안에 다음을 추가한다.
버전은 현재 기준 최신인 3.3.1으로 하였다.
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.3.1</version>
</dependency>3. 하둡 설치
하둡을 설치한다.
하둡은 이곳에서 찾을 수 있다.
다운 받고 싶은 버전을 찾아 폴더를 선택한 뒤 (이 글은 3.3.1이 기준)
하위 폴더에서 hadoop-x.y.z.tar.gz 파일을 찾고, 우클릭해서 링크를 저장한다.
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz 명령어로 다운을 받고 나서 tar로 압축을 풀어준다.
간단하게 tar -x hadoop-3.3.1.tar.gz로 해당 디렉토리에 바로 풀 수도 있고 (해당 폴더에 .gz 파일이 하나 뿐이라면 간단하게 *.gz을 해도 된다.)
tar -xf hadoop-3.3.1.tar.gz --directory {목적지 디렉토리}로 다른 디렉토리에 압축을 풀 수도 있다.
4. 환경변수 설정
두 가지 경로를 따로 복사해둔다.
첫째로 하둡이 설치된 디렉토리에서 pwd 명령어를 입력해서 나오는 경로(~~~/hadoop-3.3.1)를 복사한다.
둘째로 그 디렉토리 밑의 bin 디렉토리의 절대 경로를 복사한다.
sudo vim /etc/profile 혹은 sudo vim ~/.bashrc로 들어간다.
여러 사람이 사용하는 환경에서 다른 사람의 하둡 사용을 막으려면 후자로 들어간다.
전자는 시스템을 사용하는 모든 사용자에게 적용된다.
리눅스 실행 시 배시가 실행되는 순서는 일반적으로 다음과 같다.
/etc/profile
로그인 된 경우
~/.bash_profile or ~/.bash_login or ~/.profile
안 된 경우 (로그인 쉘이 아닌)
~/.bashrc
보통 환경변수 설정은 etc/를 수정한다.
여기에서도 /etc/profile을 수정하여 다음과 같이 하둡과 하둡홈의 경로를 설정해준다.

이후 source etc/profile을 이용해서 적용한다.
적용 후 hadoop version을 통해 정상적으로 명령어가 작동하는지 확인한다.

5. 로그 설정
org.apache.hadoop.hadoop-common에는 자동으로 log4j가 들어있다.
단, 터미널 환경이 아닌 IntelliJ의 실행창에 로그를 찍으려면 log4j.properties로 로그 설정이 필요하다.
src 디렉토리에 log4j.properties 파일을 생성하고 로그 설정을 작성해준다.
6. 데이터 형식
먼저 데이터에서 첫 5줄의 형태에 대해서 아래 코드로 분석해보면,
import sys
ncdc = open(sys.argv[1], "rt")
lines = ncdc.read().splitlines()[:5]
for l in lines:
print("year:", l[15:19])
print("temp:", int(l[87:92]))
print("quality:", l[92:93])
print()
ncdc.close()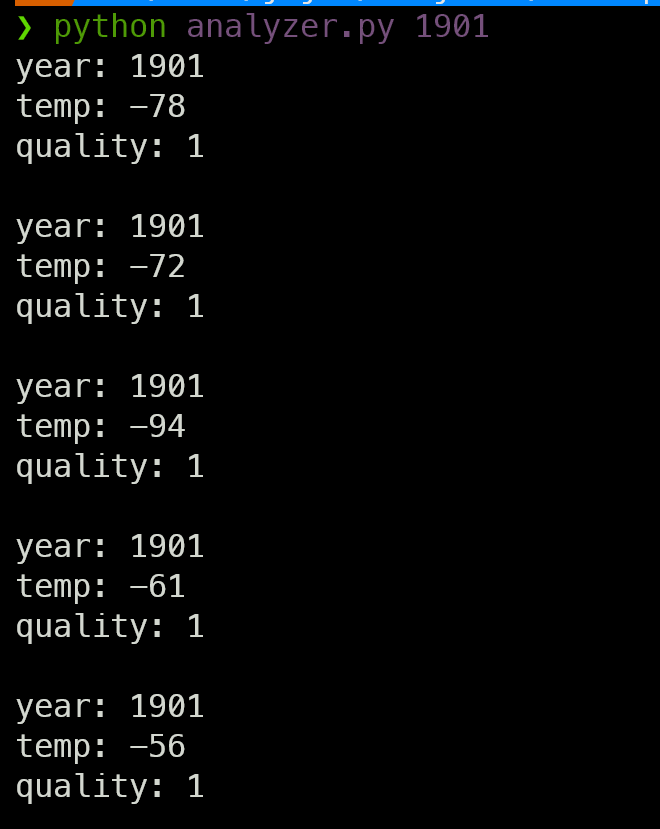
이렇게 연도와 온도, 특성 코드(quality)가 나오는 것을 확인할 수 있다.
온도는 소수점을 제외한 온도로, 10을 나누면 실제 온도가 나온다. (-56은 -5.6도이다)
특성 코드는 0, 1, 4, 5, 9일 때 데이터가 유효하다고 한다.
또한 온도가 9999이라면 누락된 값을 의미한다.
7. 문제 정의
먼저 맵 태스크와 리듀스 태스크에서 어떠한 일을 할 것인지를 정한다.
예제의 분석은 기상 데이터에서 연도별 최고 기온을 출력하는 것이다.
연도별 최고 기온이므로, 연도가 키가 되고 기온이 값이 될 수 있다.
따라서 맵 태스크는 데이터에서 연도-기온 쌍을 뽑아내는 작업이 되고
리듀스 태스크는 연도별 기온들에서 최대값을 뽑아내는 작업이 된다.
8. 맵 태스크
세분화
연도-기온 쌍을 데이터에서 어떻게 뽑아낼 것인지 정한다.
연도는 15~19번째 글자 (0부터 세므로 실제로는 1을 더해줘야 할 것이다)
온도는 88~92번째 글자,
특성 코드는 93번째 글자이다.
특성 코드가 올바르다면 이는 신뢰할 수 있는 데이터이다.
최종적으로 맵 태스크에서 작성할 코드는
연도, 온도, 특성 코드를 추출하고
온도가 유효하다면, 연도-온도의 쌍을 출력하는 코드이다.
코드 작성
맵 태스크를 작성하기 위해 맵 클래스를 생성한다.
클래스의 이름은 프로젝트의 이름인 MaxTemperature를 따라 MaxTemperatrueMapper로 지었다.
맵 클래스는 Mapper<LongWritable, Text, Text, IntWritable> 클래스를 상속받는다.
Mapper 클래스의 타입 매개변수는 <KEYIN, VALUEIN, KEYOUT, VALUEOUT>이다.
맵 태스크는 키-값을 출력하지만 입력을 받을 때도 키-값으로 받는다.
이때의 키는 파일의 행의 오프셋, 값은 한 행의 내용이다.
따라서 KEYIN은 long, VALUEIN은 Text가 된다.
우리가 맵 태스크에서 출력할 것은 연도와 그 당시의 온도이다.
연도는 정수지만 여기서 굳이 문자열로 읽어들인 것을 정수로 바꿀 필요는 없다.
온도는 최대값을 구해야 하기 때문에 정수로 바꿔 주어야 한다.
그래서 KEYOUT과 VALUEOUT은 각각 Text와 Int가 된다.
Mapper 클래스를 상속 받으면 map(keyin, valuein, context)를 오버라이딩 하고,
context에는 (keyout, valueout)을 써야 한다.
이때 위의 Mapper로 전달했던 타입과 형식이 다르면 안 된다.
KEYOUT, VALUEOUT이 Text와 Int였으므로 context에도 이와 같은 형식으로 써주어야 한다.
이후 하둡이 context을 통해 맵의 출력을 통제하고 파티션을 생성하는 등의 일을 한다.
이때의 맵의 출력은 임시적인 것으로, 하나의 맵 리듀스 잡이 끝나면 특별한 설정이 없는 이상 삭제된다.
이러한 작업들로 만들어진 코드는 다음과 같다.
public class MaxTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature = Integer.parseInt(line.substring(87, 92));
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}9. 리듀스 태스크
세분화
맵의 출력을 같은 키대로 모아 리듀서 작업을 실행할 파티션으로 전달하는 '셔플'과
전달받은 데이터를 키와 리스트 형식으로 정리하는 '소트' 단계는 하둡의 맵리듀스가 알아서 해주므로 우리는 리듀서 단계에서 리듀스 태스크에 집중할 수 있다.
리듀스 태스크에선 앞서 정의했듯이 연도별 기온들에서 최대값을 뽑아내야 한다.
그리고 맵에서 이를 Text와 Int의 형태로 준다.
연도(Text)에 해당하는 온도들(Int)의 최대값을 구하면 된다.
온도들은 iterable 한 형식으로 주어지므로 일반적인 리스트에서 최대값을 구하는 코드를 작성하여, 그의 결과를 출력하면 된다.
코드 작성
Reducer는 <KEYIN, VALUEIN, KEYOUT, VALUEOUT>의 형식을 전달인자로 받는다.
여기서 KEYIN과 VALUEIN은 맵에서 주는 형식과 같아야 한다. 맵의 출력 키 형식과 동일하게 Text와 Int가 될 것이다.
KEYOUT과 VALUEOUT은 맵과 같을 필요는 없는데, 일단 하는 일이 연도별 최고 기온이기 때문에 이것도 Text와 Int로 해준다.
이러한 작업들로 만들어진 코드는 다음과 같다.
public class MaxTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value: values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
리듀서에서 리듀스 함수의 입력값은 이미 sort된 채로 들어온다.
그래서 한 연도에 해당하는 모든 온도값을 받아볼 수 있다.
10. 메인 함수
맵과 리듀스를 이용할 수 있는 메인 함수를 작성해야 한다.
메인 함수는 [입력 데이터 경로] [출력 데이터 경로]로 실행할 수 있다.
여기서 할 일은 다음과 같다.
- 분석할 파일 경로와 출력 경로 얻기
- 로그 활성화
- 잡 기본 정보 등록
- 파일 입출력 형식 설정
- 맵, 리듀서 클래스 등록
- 출력 키, 값 클래스 등록
- 종료
이를 구현한 코드는 다음과 같다.
주의할 점은 6번에서의 출력할 키와 값 클래스는 리듀스의 그것과 같아야 한다.
public class MaxTemperature {
public static void main(String[] args) throws Exception {
// 1. 분석할 파일 경로와 출력 경로 얻기
if (args.length != 2) {
System.err.println("Usage: MaxTemperature <input path> <output path>");
System.exit(-1);
}
// 2. 로그 활성화
BasicConfigurator.configure();
// 3. 잡 기본 정보 등록
Job job = Job.getInstance();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max Temperature");
// 4. 파일 입출력 형식 설정
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 5. 맵, 리듀서 클래스 등록
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
// 6. 출력 키, 값 클래스 등록
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 7. 종료
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}이후 실행할 때는 자바를 컴파일 해서 jar로 묶어준 다음
hadoop jar {jar 파일 경로} {입력 데이터 경로} {출력 데이터 경로}로 실행할 수 있다.
이때 주의할 점은, 출력 데이터 경로가 존재하지 않아야 한다는 것이다.
리듀스 결과를 파일로 출력하기 전에 입력된 출력 데이터 경로의 디렉토리를 생성하기 때문이다.
부주의하게 분석을 시행해서 결과가 덮어씌워지는 것을 막는 장치다.
혹은 IntelliJ에서 Run/Debug Configuration 을 설정해서
argument들을 직접 넣어준 다음에 (입/출력 데이터 경로) 실행할 수 있다.
IntelliJ에서 JAR 파일을 만드는 방법은 다음과 같다.
- File -> Project Structure (혹은 Ctrl + Alt + Shift + S)
- 왼쪽 Project Settings의 Artifacts
- 추가(+) 버튼을 눌러 JAR -> From modules with dependencies...
- Main Class를 지정해주고 OK
- Output Directory 를 지정해주고 Apply & OK
- 상단 Build -> Build Artifacts -> 생성할 jar 선택 -> Build
- 5에서 설정한 Output Directory에서 jar 파일 확인
11. 컴바이너
클러스터에서 맵리듀스 잡이 사용하는 네트워크 대역폭은 한계가 있기 때문에 맵과 리듀스 태스크 사이의 데이터 전송을 최소화할 필요가 있다.
컴바이너는 맵의 출력에서 실행되는 함수이다.
맵의 출력에서 리듀스 작업을 한 번 거친 다음(컴바이너) 리듀스로 보낼 수 있다.
리듀스 작업은 기본적으로 데이터의 양을 줄이기 때문에 (n개의 데이터에서 m개의 결과를 추출, 이때 m은 n보다 작다)
맵에서 한 번 거치고 가면 리듀스로 보내지는 데이터의 양을 줄일 수 있다.
또한 맵(데이터가 있는 곳)에서 연산을 하기 때문에 데이터 지역성 챙길 수 있다.
이 예에서 컴바이너는 적용하면 다음과 같다.
각 맵에서 1901: 100, 1901: -104, 1901: 241과
1901: 234, 1901: 133, 1901: 215를 출력한다고 치자.
이때 리듀스로 들어가는 입력은 1901: [100, -104, 241, 234, ...] 이다.
하지만 각 맵에서 리듀스를 한 번 돌리고 나면 출력값은 1901: 241과 1901: 234가 되고
결과적으로 리듀스로 전송되는 데이터는 1901: [241, 234]가 된다.
즉 정수 6개 짜리 데이터가 전송되던 것이
컴바이너 함수를 돌리고 나니 정수 2개만 전송해도 되는 것이다.
다만 이는 제약이 있는데, 이는 결합법칙이 성립을 해야 한다.
최대값은 결합법칙이 성립한다.
max(a, b, c, ... z)를 하든 max(max(a, b), max(c, d), ...)를 하든 결과는 똑같다.
하지만 평균의 경우는 다르다.
mean(0, 20, 10, 25, 15) = 14지만
mean(mean(0, 20, 10), mean(25, 15)) = mean(10, 20) = 15 이기 때문이다.
컴바이너 함수는 리듀스로 가는 데이터의 양을 줄일 수 있다.
따라서 맵리듀스 잡에 컴바이너의 적용 여부를 검토하는 것은 충분한 가치가 있다.
컴바이너 함수는 Reducer 클래스를 사용해서 정의한다.
즉 동일한 구현체를 사용하면 된다.
그저 리듀서 클래스를 등록하기 이전에 해당 클래스와 똑같은 클래스를 컴바이너 클래스로 등록해주면 된다.
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);