
글 내용 영상 출처: https://www.youtube.com/watch?v=x58W9A2lnQc
1000배 faster에 대해서 이번에는 numba관련 영상 클립도 유튜브가 추천해줬다.
가장 간단하게는 다음과 같은 방식으로 numba를 이용할 수 있다
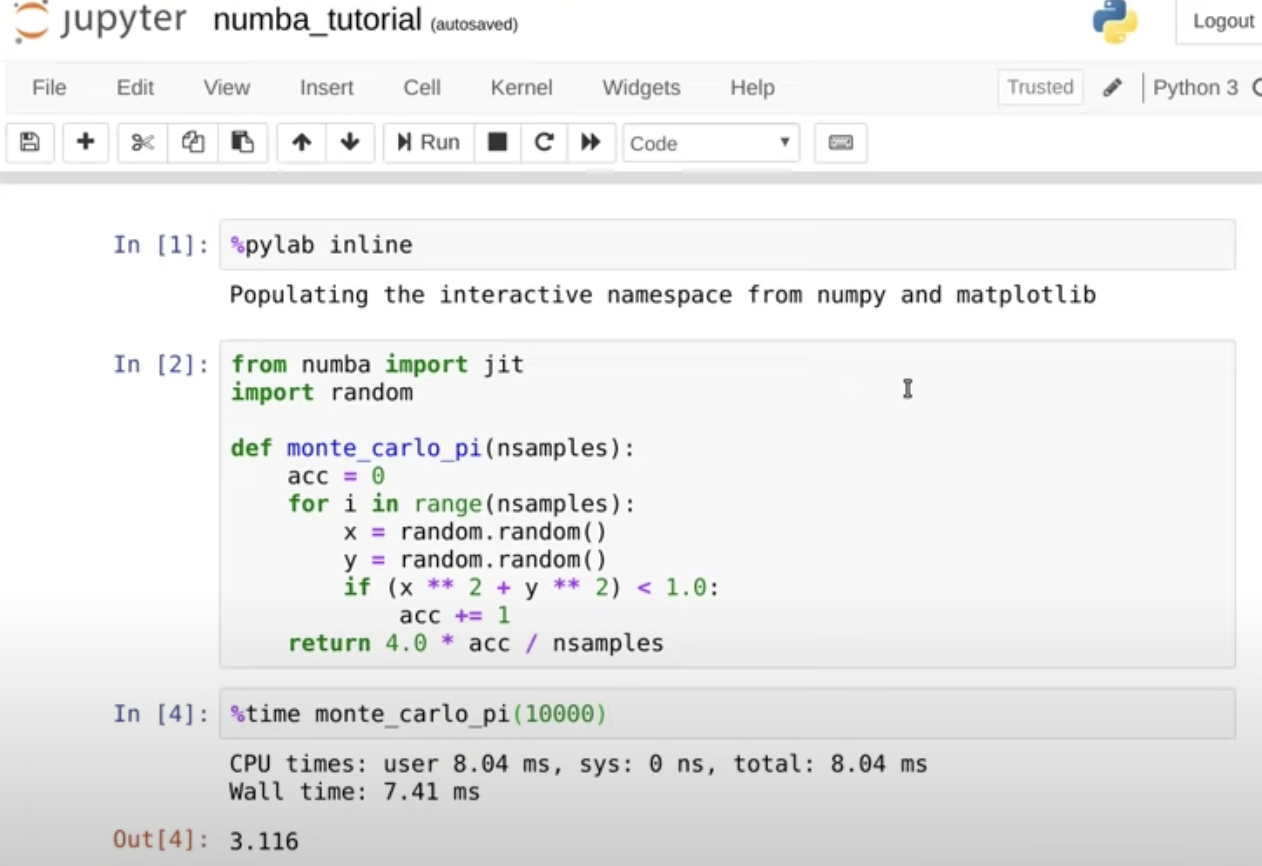
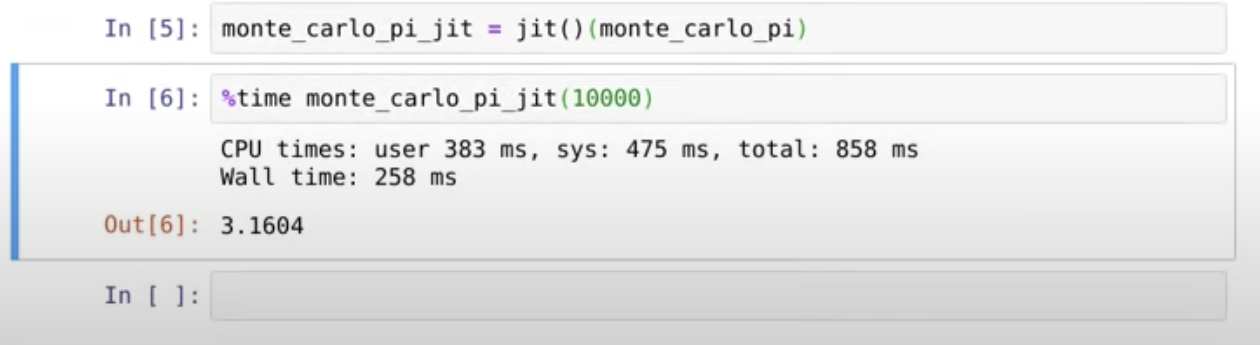 wall time을 보면 numba를 사용하기 전보다 더 길어져서 이게 뭥미?!할 수 있지만 이거는 numba패키지를 컴파일하는데 걸리는 시간이 합쳐져서 그런거고, 다시한번 이 셀을 실행시켜보면 훨씬 빨라진 것을 볼 수 있다
wall time을 보면 numba를 사용하기 전보다 더 길어져서 이게 뭥미?!할 수 있지만 이거는 numba패키지를 컴파일하는데 걸리는 시간이 합쳐져서 그런거고, 다시한번 이 셀을 실행시켜보면 훨씬 빨라진 것을 볼 수 있다
다음과 같은 함수가 있다. 7번쨰 라인에 1이 아닌 '1'을 append한 것에 주의하고 다음으로 넘어가보자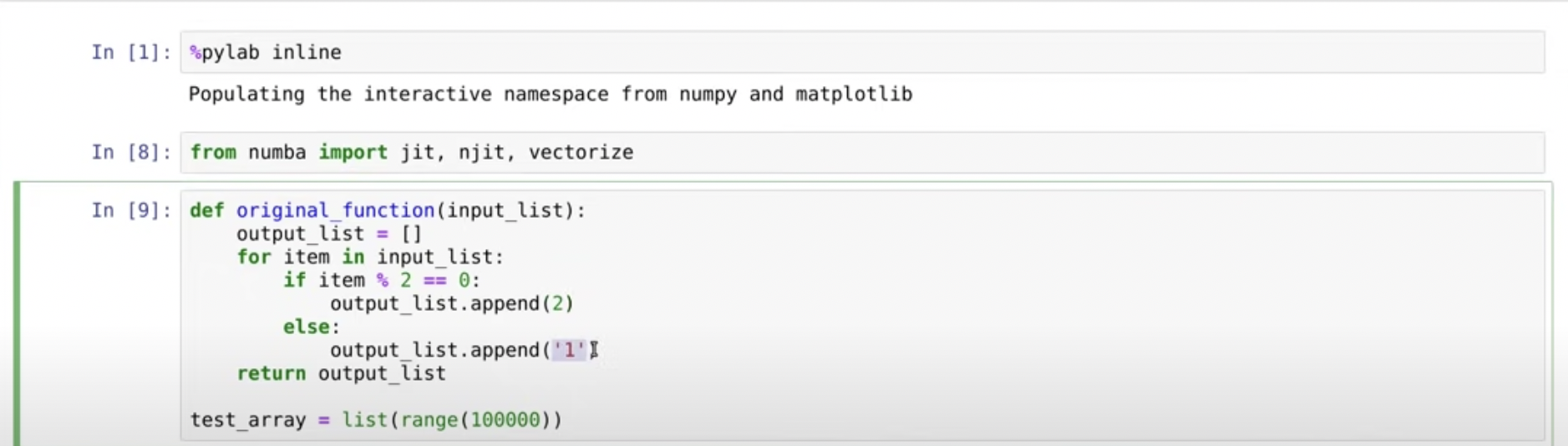
그냥 함수를 적용했을 때 17.5 ms가 걸린다. 이제 numba를 적용해보자. 함수 앞에 jit()를 써주면 간단하게 적용가능하다.
 돌려보니 pink warning이 뜬다. 저어기 output_list에서 문제가 발생한 듯 하다. 처음에 지적한대로 '1'을 append했기 때문에 warning이 뜬 것이다.
돌려보니 pink warning이 뜬다. 저어기 output_list에서 문제가 발생한 듯 하다. 처음에 지적한대로 '1'을 append했기 때문에 warning이 뜬 것이다.
이 함수의 결과를 예상해보면, [2,'1',2,'1',...] 이렇게 될 것이다. 잠깐, 여기서 뭔가 이상이상 할 수 있다. 한 컨테이너안의 원소의 타입이 다를 수 있나?.. 2은 integer이고, '1'은 string인데?...
파이썬은 이렇게 복합적인 타입을 하나의 컨테이너안에 넣을 수 있다!
그러면 왜 warning이 떴느냐? numba안에서는 numpy를 쓰지 못하고 python의 자료구조를 사용할 수 밖에 없으니 numba의 빠른 성능을 exploit할 수 없다는 경고를 준 것이다(이렇게 python을 numba안에서 돌아가게 하는 편의성은 사실 numba를 사용하지 않는 것과 같으니, 추후에 deprecated될 것이라고 한다) 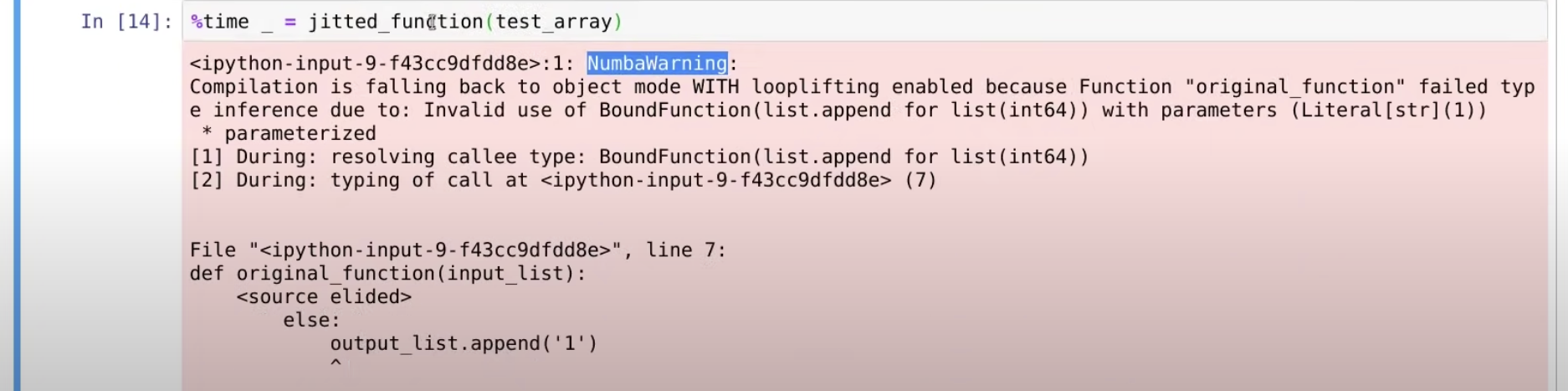
 numba안에서 파이썬을 사용하지 않도록하기위해 다음과 같은 두가지 방식을 쓸 수 있다.
numba안에서 파이썬을 사용하지 않도록하기위해 다음과 같은 두가지 방식을 쓸 수 있다.
1. njit()을 쓴다


2. jit(nopython=True)()를 쓴다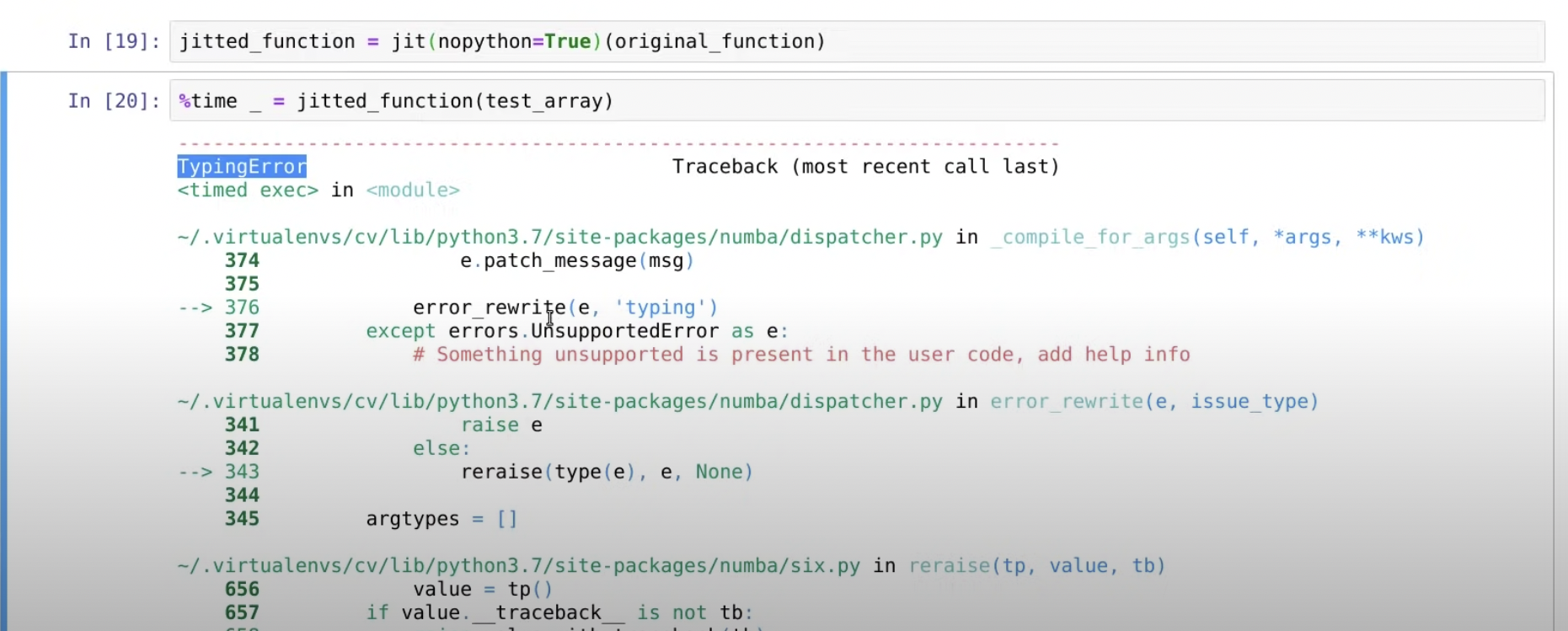
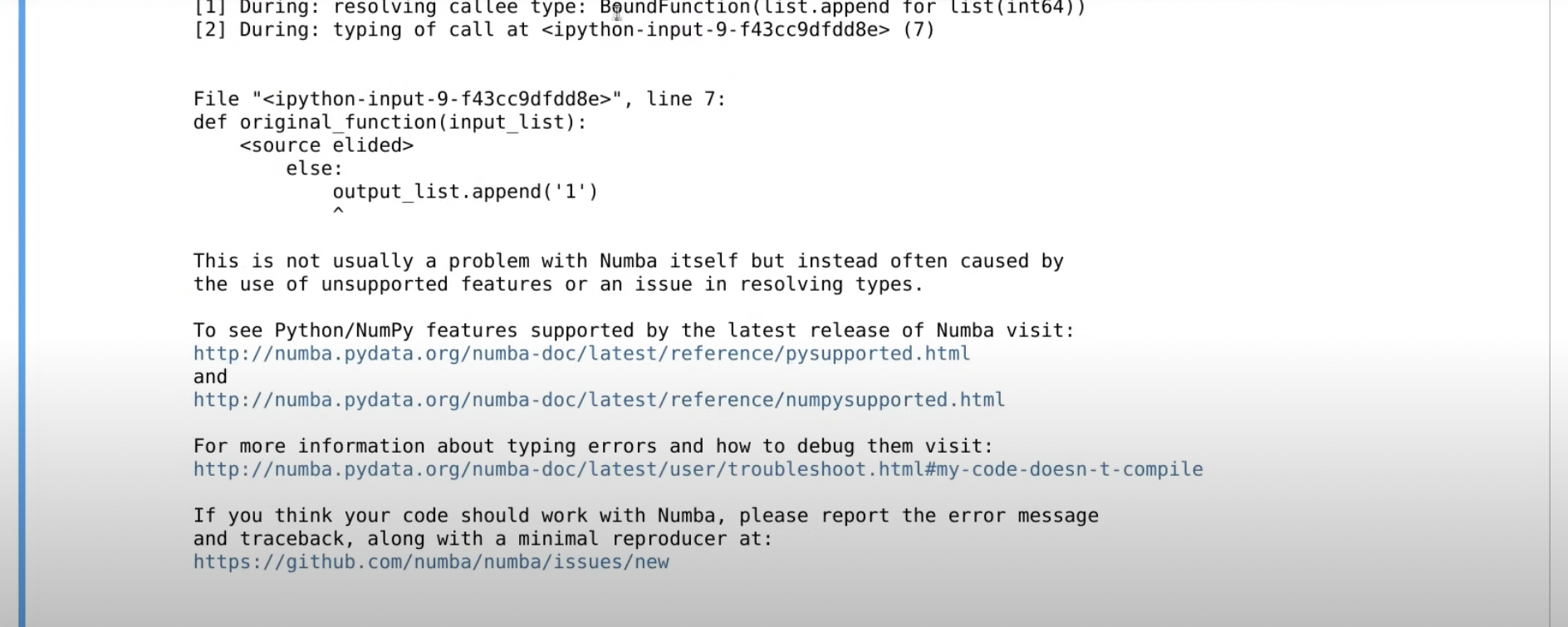
결과를 보면, 당연히 numba안에서 파이썬을 못쓰게 했으니, warning -> error가 뜬다.
그러면 이제 코드를 디버깅해보자
output_list.append('1') -> output_list.append(1)로 리스트 원소들의 타입을 일치시켜주었다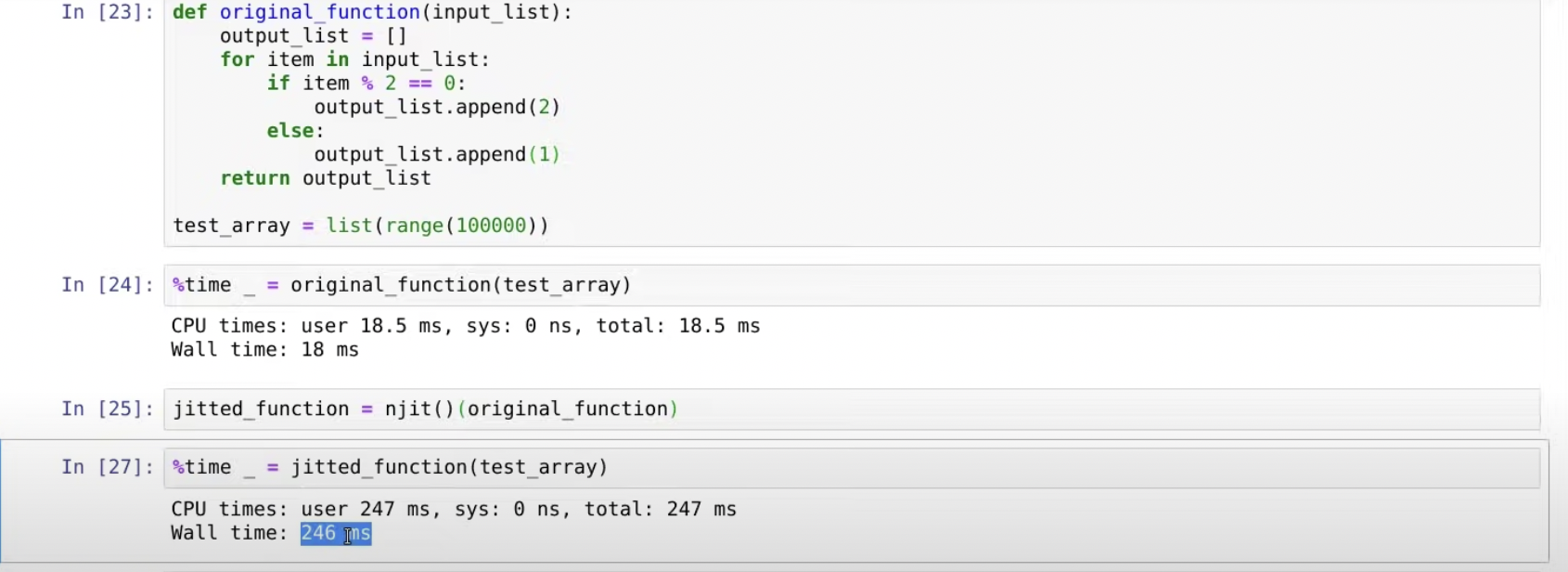
그런데도 왜 시간이 줄어들지 않지?..
reflection problem 때문이란다. 파이썬 코드로 돌아가지않도록 해주었지만, numba안에서는 이 리스트안의 원소들의 타입이 correct한지 코드가 돌아가면서 확인하기 때문이다.
여기서 명심할 것!
numba를 사용할 때는 python list가 아닌 numpy array를 사용하자!!
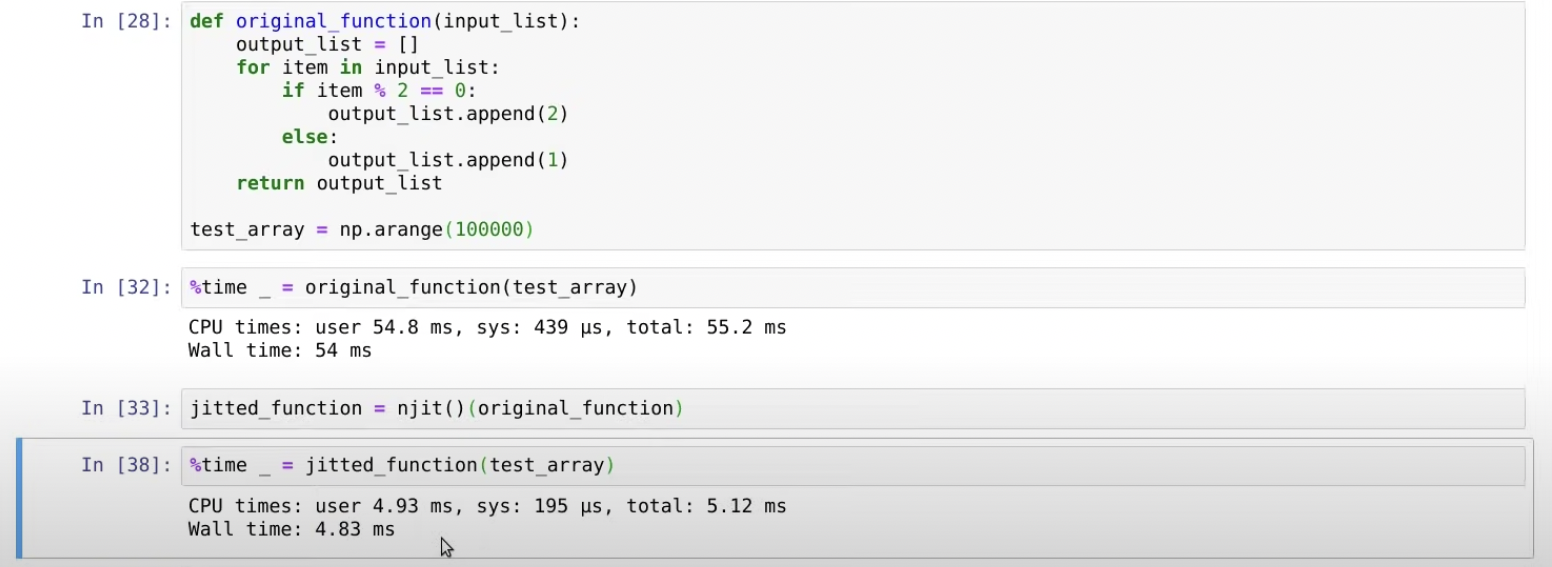
test_array를 np.array로 바꿔주니, 원래의 파이썬 코드로 돌아가는 32번째 라인은 이전보다 더 오래걸렸지만, numba로 돌아가는 38번째 라인은 더 빨라졌다!!
numba를 다르게 활용할 수 있는 방법은 vectorize decorator를 사용하는 것이다.
위의 original funciton을 decorator를 적용한 scalar computation 함수로 바꿔보았다.
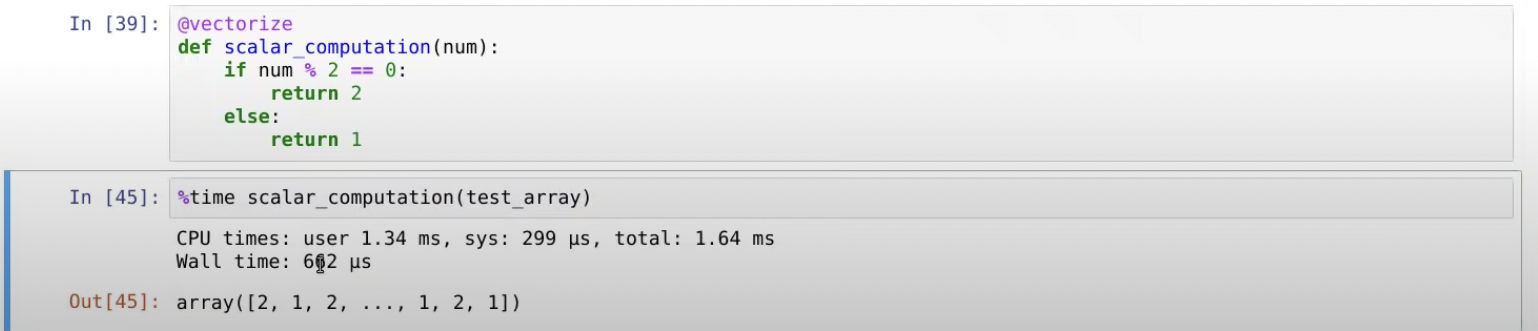
미친.. 개빨라졌다...? 왜지?
original function에서는 처음에 output_list를 빈 리스트로 정하고 값들을 채워넣게 하였다. 즉, 최종 output_list의 사이즈를 모르기 때문에 preallocation이 불가능했던 것이다. 값이 생성될 때마다 동적으로 메모리를 할당해주었기 때문에 시간이 오래걸렸는데, 밑의 함수에서는 output_list를 정해주지 않고, 연산의 결과만 뽑아내서 vector화 하였기 때문에, 더 빨라졌던 것이다.
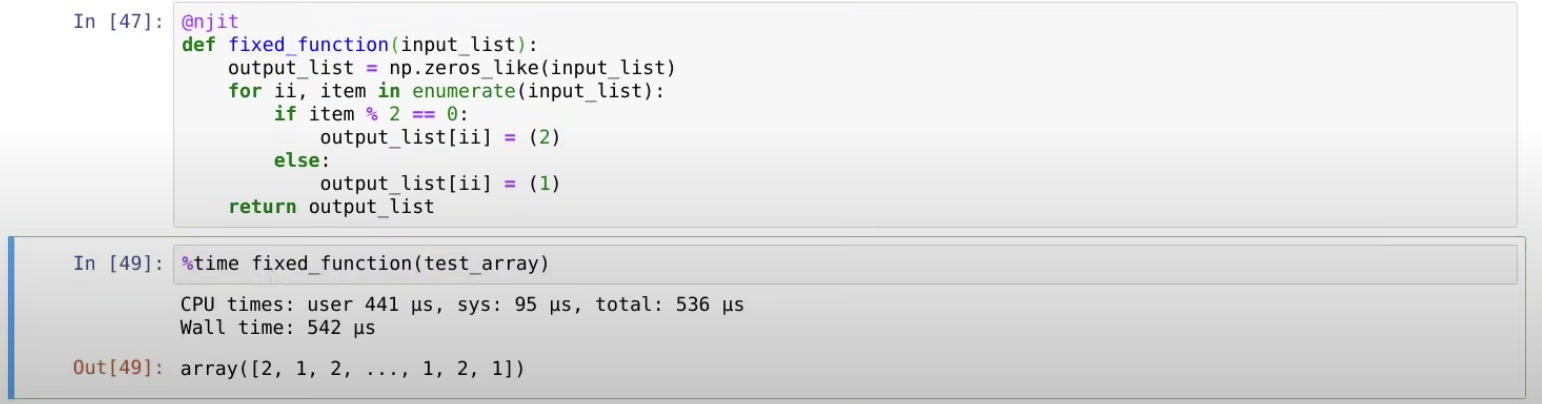
이 원리를 이용해서, original function -> fixed function으로 고쳐주자. output_list의 크기를 미리 정해주었더니, 이전의 소요시간과 같은 시간이 걸렸다.
마지막으로,
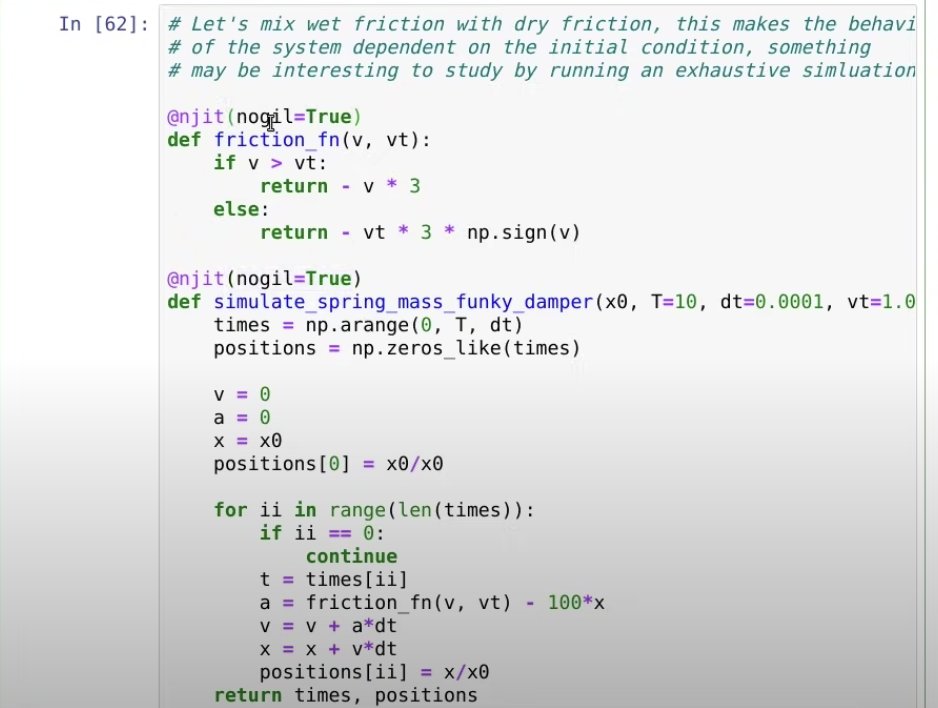
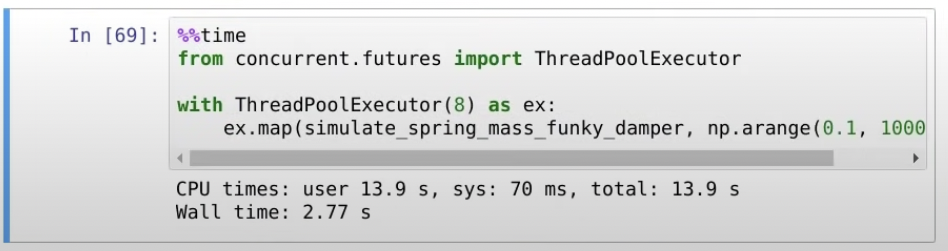
로 ThreadPoolExecutor를 이용할 수 있다!
고 하지만 여기는 잘 모르겠고...
정리
1. numba를 쓸 때는 njit + numpy array를 쓰자
2. @vectorize
3. preallocation을 가능하게 output의 사이즈를 미리 정해주고 연산하자
4. 속도 향상을 위한 영상에서 계속 threading, processing에 대한 이야기가 계속 나와서 이 부분을 꼭 공부하고 넘어가야겠다
