다음 글을 보고 번역한 내용입니다.
https://blog.floydhub.com/multiprocessing-vs-threading-in-python-what-every-data-scientist-needs-to-know/
참고
https://dgkim5360.tistory.com/entry/understanding-the-global-interpreter-lock-of-cpython
parallel processing
1) multiprocessing
2) threading
Process
컴퓨터 프로그램이 실행되는 하나의 instance
각 프로세스는 각각의 메모리공간을 가지고 instructions, 데이터를 저장한다.
Threads
- 프로세스의 component
- can run parallely
- 하나의 프로세스에 여러개의 쓰레드가 있을 수 있다
- 같은 메모리 공간을 공유(부모 프로세스의 메모리 공간)
- 이 말인 즉슨, 한 프로그램상에서 실행될 모든 코드와 선언된 변수들은 모든 쓰레드간에 공유하게 된다
예) 크롬 브라우저와 스포티파이는 다른 프로세스이다. 각각은 멀티 프로세싱이나 쓰레드를 통해 parallelism을 실행한다.
크롬브라우저의 서로 다른 탭들은 쓰레드로 처리한다.

Technical details
- 하나의 프로세스의 모든 쓰레드는 같은 메모리 공간에 존재한다. 반면에 프로세스들은 서로 분리된 메모리 공간을 가진다
- 쓰레드는 더 가볍고 적은 오버헤드를 가진다.
- 쓰레드는 같은 메모리공간을 공유하므로, 쓰레드 간에 오브젝트를 공유하는 것이 더 쉽다. 같은 일을 프로세스로 하려면, 특별한 IPC(inter-process communication) 모델을 써야한다
Pitfalls of Parallel Computing
- race condition
- 쓰레드는 메모리 공간을 공유하므로, 공유된 변수에 접근하는 것이 쉽다. race condition 는 멀티 쓰레드가 하나의 변수를 동시에 바꾸려고 할 때 발생한다. Thread scehduler는 쓰레드를 랜덤하게 스왑하기 때문에, 우리는 어떤 순서로 어떤 쓰레드가 데이터를 바꿀 지 모른다. 이를 방지하기 위해 mutual exclusion(mutex) lock 이 변수를 변화시키는 코드에 배치되어, 오직 한번에 하나의 쓰레드가 변수를 변화시키도록 할 수 있다.
- starvation
- starvation 은 특정 리소스에 긴 시간동안 접근이 거부될 때 발생한다. 그 결과, 전체적인 프로그램의 속도가 늦어진다.
- deadlock
- mutex를 너무 많이 사용하는 것 또한 deadlock을 발생시킬 수 있다. deadlock 은 한 쓰레드(2)가 다른 쓰레드(1)가 lock을 풀 때까지 기다릴 때, 또 다른 쓰레드(3)가 다른 쓰레드(2)의 결과물이 필요할 때 발생한다. 이 경우, 두 개의 쓰레드 모두 정지되고 프로그램은 멈추게 된다. deadlock은 starvation의 극단적인 케이스로 볼 수 있다. 이를 피하기 위해서는 interdependent한 lock을 너무 많이 쓰면 안된다.
- livelock
- 쓰레드가 loop안에서 계속 돌아가는데 진전이 안될 때 발생한다. 이 또한 디자인을 잘못했거나, mutex lock을 너무 많이 쓸 때 발생한다.
multiprocessing and threading in python
GIL (Global Interpreter Lock)
파이썬에서 주의할 점이 있다. 쓰레드가 같은 메모리 공간을 공유하기 때문에, 두 쓰레드가 같은 메모리 location에 쓰지 않도록 몇가지 주의점이 필요하다. CPython 인터프리터는 이러한 메카니즘은 GIL이라고 부른다
CPython에서, 실행되는 파이썬 바이트코드의 복수의 쓰레드가 한번에 실행되어서, 파이썬 오브젝트에 접근하는 것을 막기 위해 GIL이라는 mutex를 제공한다. 이 lock은 CPython의 메모리 관리가 thread-safe하지 않기 때문에 필요하다.
GIL은 작업을 완료하지만, 비용이 든다. GIL은 효율적으로 instructions을 인터프리터 레벨에서 직렬화(serealize) 한다. 오직 한번에 하나의 쓰레드가 lock을 할 수 있다. 즉, 인터프리터는 instruction 을 sereailly 실행한다.
직렬화
이 디자인은 메모리 관리를 thread-safe하게 하지만, 그 결과 multiple CPU core를 사용할 수 없게 한다. CPYthon을 개발할 당시 염두에 두었던 싱글 코어 CPU에서는 별로 큰 문제가 아니었지만, 멀티코어 CPU환경에서는 이 global lock이 bottleneck이 되어버린 것이다.
만약 우리의 프로그램이 다른 곳에서 더 심한 bottleneck(network, I/O, UI...)이 있을 경우 이러한 bottleneck은 별로 문제가 되지 않는다. 이러한 경우에는 쓰레딩이 완전히 효율적인 parallelization 방법이 된다. 그러나. CPU bound 프로그램의 경우, 이러한 bottleneck은 속도를 저하시킨다.
Use Cases for Threading
1) GUI 프로그램
-
예1: text editing program에서는
- 하나의 쓰레드가 유저 인풋을 기록하고, 다른 쓰레드가 텍스트를 디스플레이하고, 또 다른 쓰레드가 맞춤법 체크를 해줄 수 있다.
- 여기서는 프로그램은 유저가 입력을 할 때까지 기다려야 된다 -> 큰 bottleneck이 된다. -> 멀티 프로세싱은 여기서 속도향상에 영향을 주지 못한다.
-
예2: web scraper와 같은 IO bound/ network bound 프로그램에서는
- 멀티 쓰레드는 여러 웹페이지에서 스크래핑하는 것을 병렬적으로 할 수 있다.
- 이 쓰레드들은 인터넷에서 웹페이지를 다운받아야 하는데, 이게 가장 큰 bottleneck이다. 그래서 쓰레딩이 제일 좋은 해결책이다.
- 웹서버와 같은 network bound 프로그램도 같은 방식으로 작동한다.
- 텐서플로우에서도, 쓰레드 풀을 사용해서 데이터를 병렬적으로 변환한다.
Use Cases for Multiprocessing
멀티 프로세싱이 쓰레딩보다 우위를 갖게 되는 경우는 프로그램이 CPU intensive일 경우, IO, UI와 관련이 없을 경우이다.
예를 들어, 숫자를 가지고 지지고 볶는 어떤 프로그램이던 멀티 프로세싱을 쓰면 속도가 향상된다.
예를 들어 Pytorch Dataloader는 여러개의 subprocess를 사용해서 GPU에 로드한다.
Benchmarks
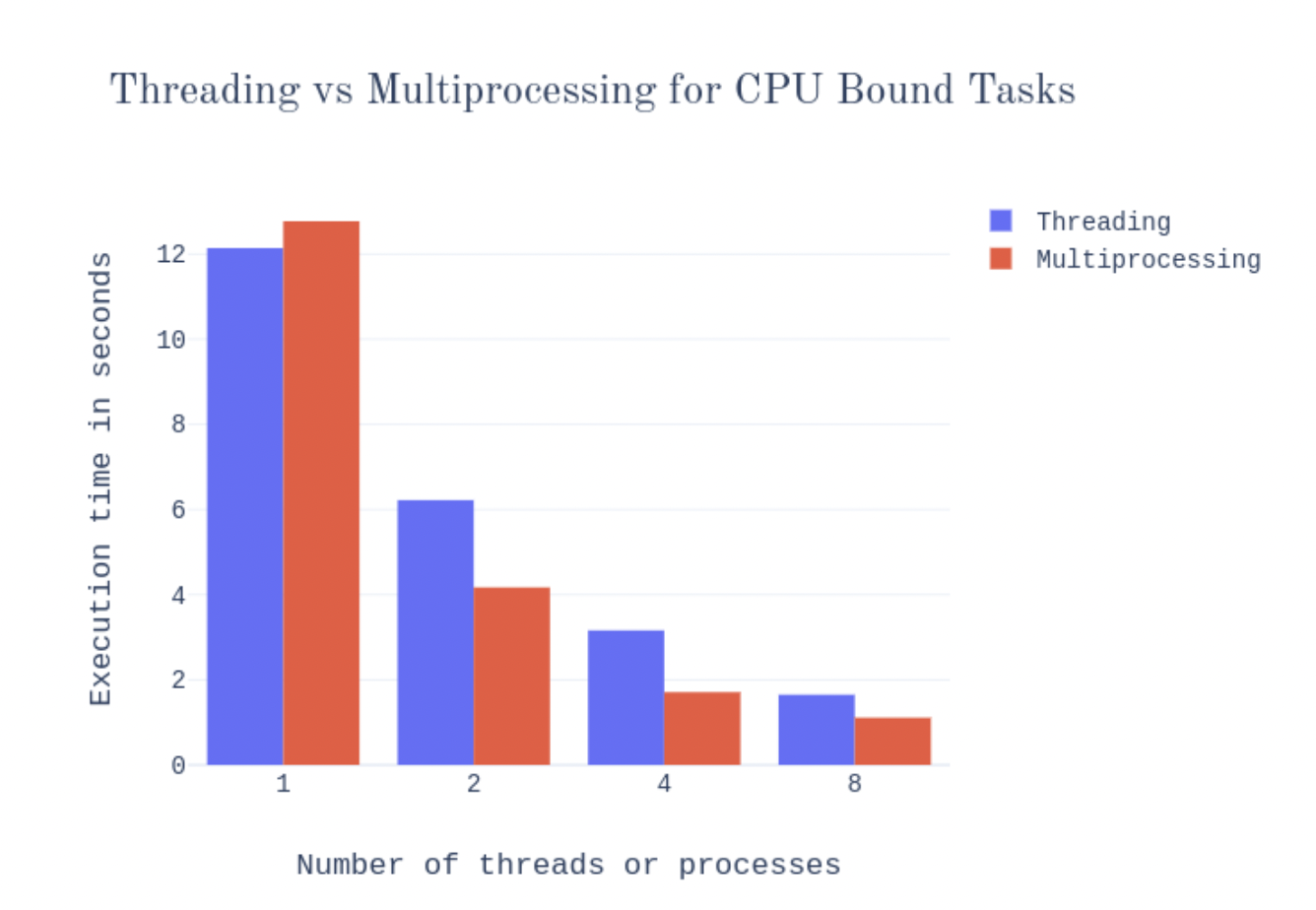
- 위에서 살펴봤 듯, CPU bound task에는 쓰레딩이 좋은 방법이 아니다.
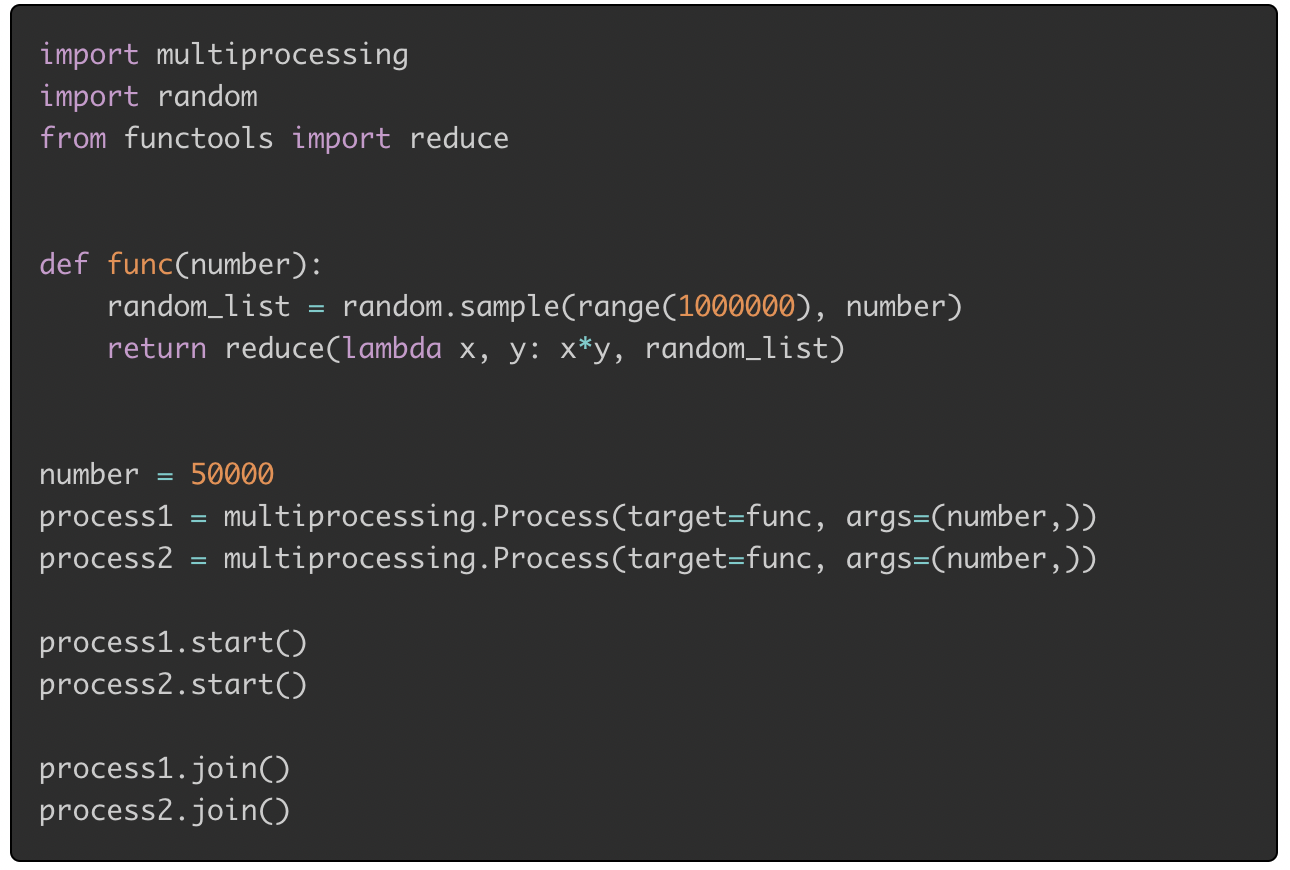
1) CPU bound task
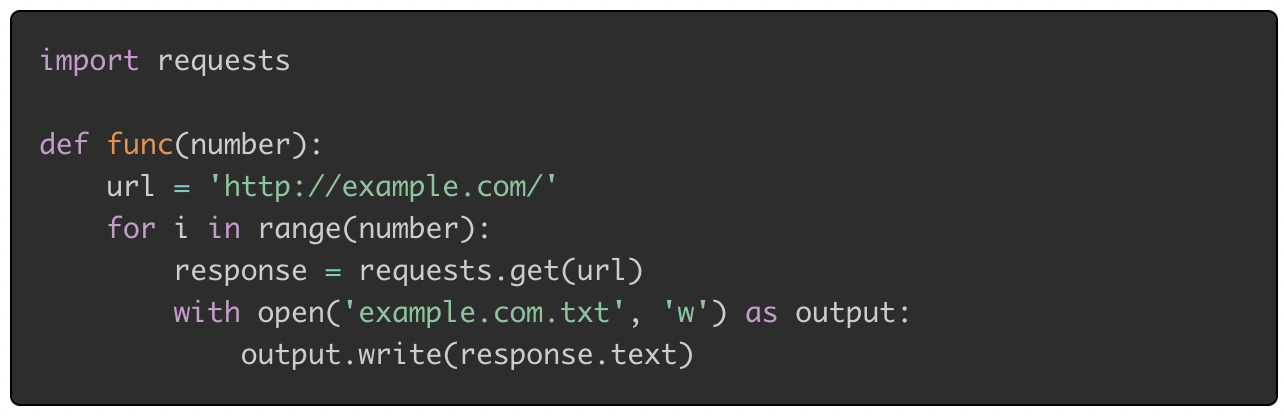
2) I/O bound task
결론
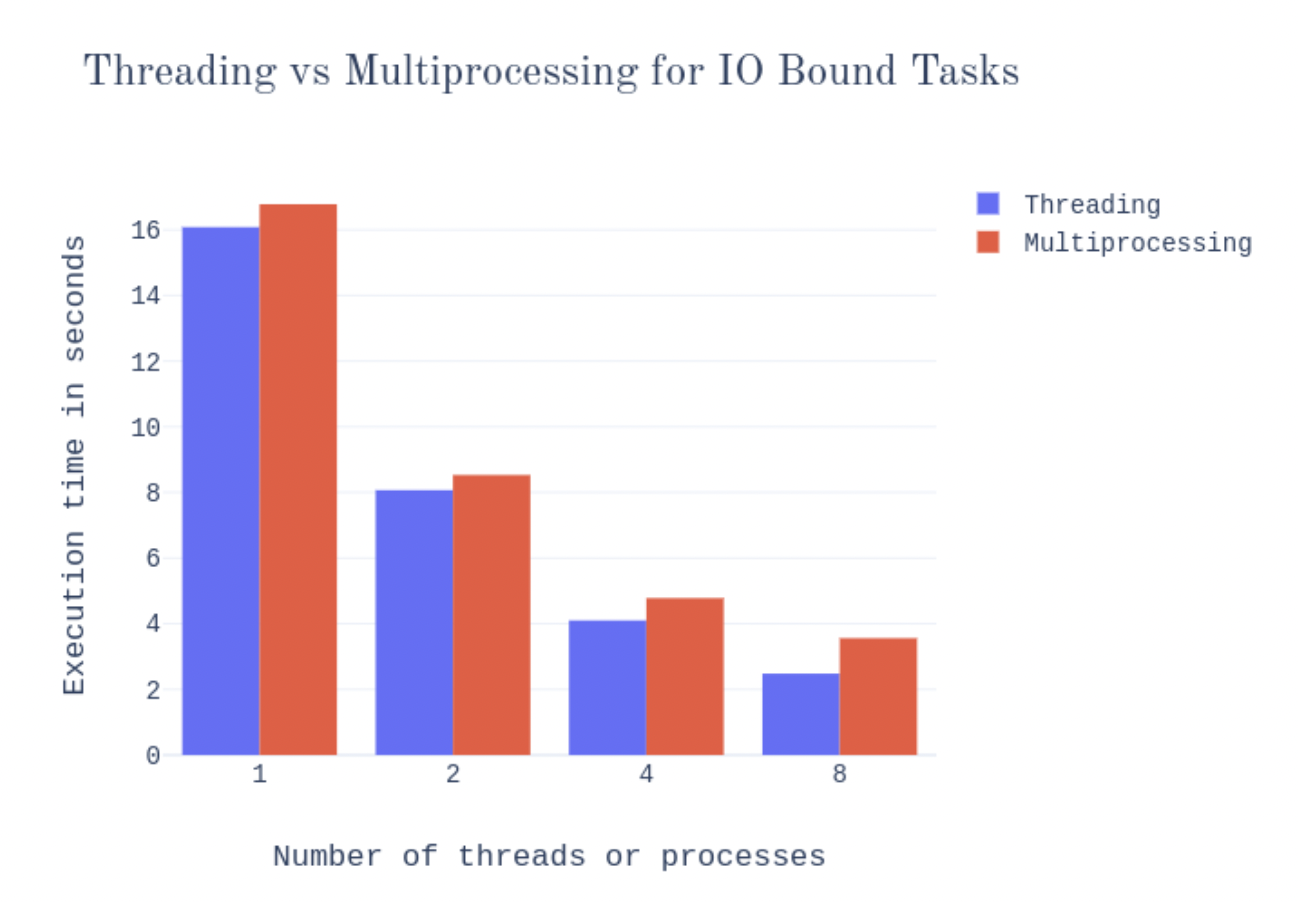
- 두 가지경우 모두, 싱글 프로세스가 싱글 쓰레드보다 실행시간이 더 오래 걸렸다. 명백하게, 여러개의 프로세스가 여러개의 쓰레드보다 오버헤드가 더 크다.
- CPU bound task의 경우, 멀티 프로세싱 > 멀티 쓰레딩 (better) 그러나, 이 차이는 8x parallelization이 될 때 매우 좁혀진다. 내 노트북의 processor가 쿼드코어이기 때문에, 4개의 프로세스까지는 멀티 코어를 효율적으로 잘 활용할 수 있었던 것이다. 더 많은 프로세스가 더 scale이 잘되는 것은 아니다. 그러나 여전히 쓰레딩보다는 더 좋은 성능을 보인다. 왜냐면 멀티 쓰레딩은 여러개의 코어를 아예 사용못하기 때문이다.
- I/O bound task의 경우, bottleneck은 CPU가 아니다. 그러므로 보통의 한계는 GIL가 적용되지 않기 때문이다. 그리고 멀티 프로세싱이 전혀 이득이 되지 않는다. 또한, 쓰레드에서의 약간의 오버헤드가 멀티프로세싱보다 빠르게 만든다.
Differences, Merits and Drawbacks
- 쓰레드는 같은 메모리 공간에서 동작한다. 프로세스는 분리된 메모리를 가진다.
- 쓰레드간에 오브젝트를 공유하는 것이 더 쉽지만, 관점을 바꾸면, object synchronization에 더 큰 신경을 써야된다는 것을 의미한다. 두개의 쓰레드가 하나의 오브젝트에 동시에 쓰는 race condition이 발생하지 않도록 유의하자
- object synchronization으로 인해 추가된 프로그래밍 오버헤드로 인해, 멀티 쓰레드 프로그래밍은 버그가 생기기 쉽다. 반면에 멀티 프로세싱은 버그를 고치기 쉽다.
- 쓰레드는 프로세스보다 낮은 오버헤드를 가진다. 프로세스를 마니마니 쓰는 것은 더 많은 시간이 걸린다.
- Python의 GIL 때문에, 멀티쓰레딩는 여러개의 CPU 코어를 쓰는 진정한 parallelism 를 성취할 수 없다. 멀티 프로세싱은 이러한 제약이 없다.
- process scheduling은 os에 의해 핸들되는 반면, thread scheduling은 파이썬 인터프리터에 의해 핸들링된다.
- 자식 프로세스들은 interrupt가 가능하고, 죽일 수 있지만, 자식 쓰레드는 불가능하다. 쓰레드를 terminate or join하기 위해서는 기다려야한다.
- 쓰레딩은 IO, UI 프로그램에서 사용하고, 멀티프로세싱은 CPU bound computation intensive 프로그램에서 사용해야한다.
From the Perspective of a Data Scientist
대부분의 데이터 처리 파이프라인은 다음과 같은 스텝으로 구성된다.
- raw data를 읽어서, 메인 메모리나 GPU안에 저장한다
- CPU, GPU를 이용해서 연산을 수행한다
- 캐낸 정보를 DB or disk에 저장한다.
스텝1은 디스크에서 데이터를 읽어와야하므로 disk I/O 문제가 bottleneck이 될 것이다. 이때에는 쓰레딩을 사용해야한다. 같은 논리로 스텝 3도 쓰레딩을 사용한다.
그러나 스텝2는 CPU, GPU를 이용하여 연산을 수행해야하므로 멀티 프로세싱을 해야한다.
당신의 데이터 파이프라인에서 parallelization을 이용하기 위해 고려할 사항은 다음과 같다
- 당신의 태스크가 IO 의 형태인지
- IO가 당신의 프로그램에 bottleneck이 되는지
- 당신의 태스크가 CPU에 의한 대량 연산에 의존하는지
