출처: https://tv.naver.com/v/11212875
DEVIEW 2019에서 제공한 쿠팡 추천시스템 발표내용 정리입니다.
1. 문제의식:
- 개인화 추천
- 특정 카테고리에서 내가 자주본 제품을 추천해주는 등의 추천
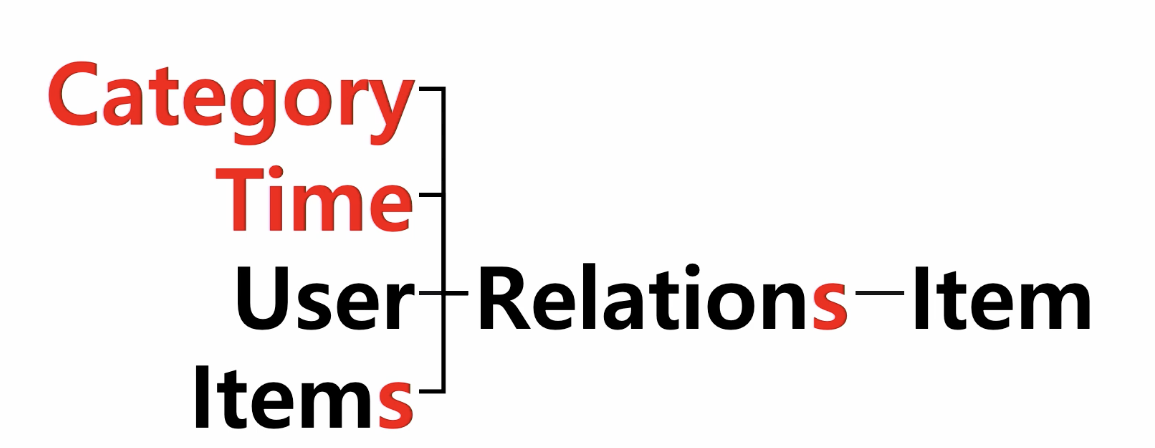
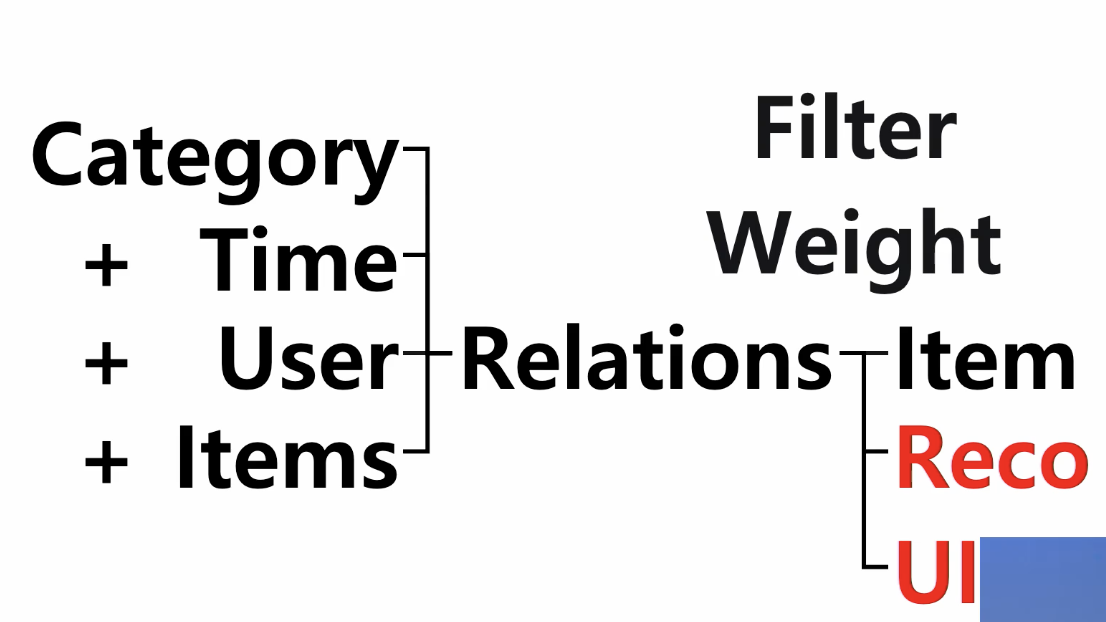
관계에 대한 정의 - multicontext 를 고려한 추천
아이템 뿐만 아니라 UI의 개인화
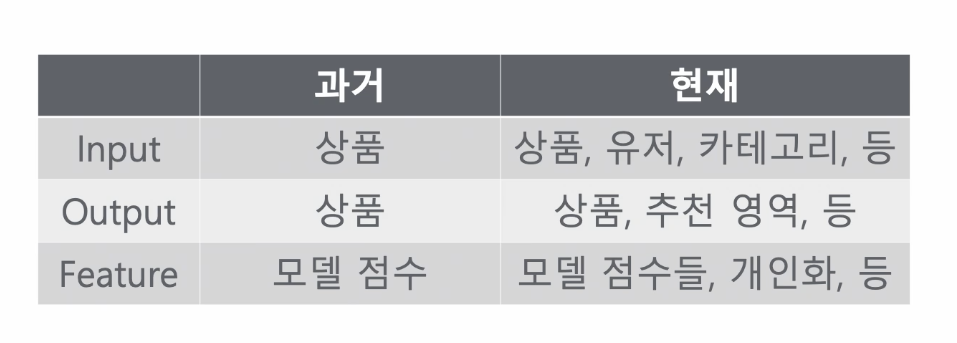
2. 과거의 추천시스템: 추천 모델 중심의 추천(아이템과 아이템간의 관계가 중요)
<모델 아키텍처>
<서버 아키텍처>
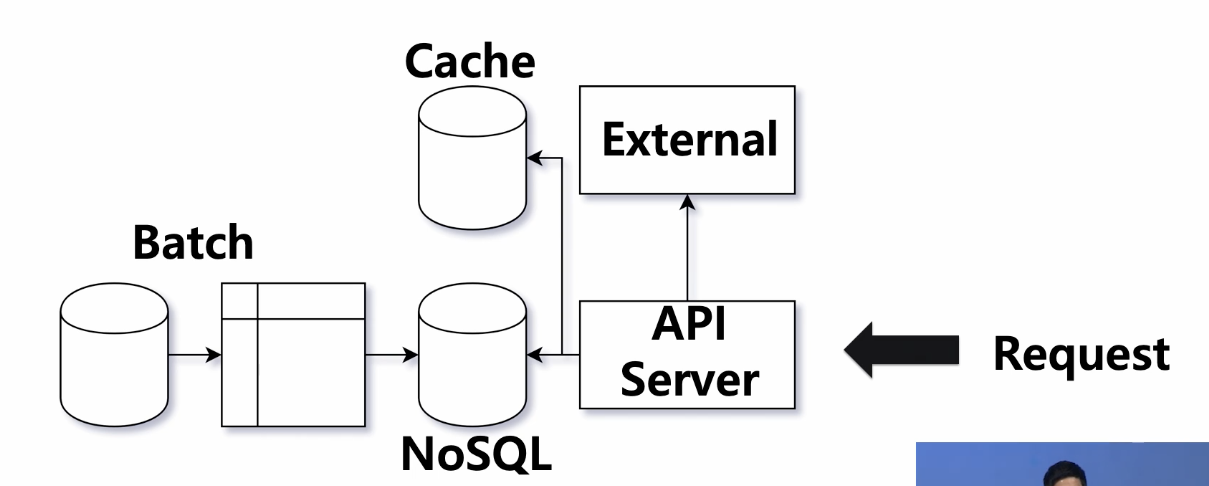
- 모델 아키텍처가 굉장히 복잡했던 반면, 서버 쪽 아키텍처는 매우 단순함
- 모델 파이프라인의 결과 테이블이 추천 서비스 전체를 결정했기 때문에, 서버는 어떤 product id에 대해, 다른 product id를 점수 순서대로 돌려주는 key-value storage를 lookup하는 것으로 충분했음.
- key: product id (유저나 카테고리등의 multicontext를 고려x)
상품이 linear하게 증가했기 때문에 별 무리가 없이 캐시를 이용해서 낮은 latency 유지가 가능했음
<단점>
1. 모델에 따라 길어지는 파이프 라인
2. 추가 요청사항 처리가 어려움
3. 완성전까지 결과를 알 수 없음
4. 개발에 시간이 오래걸림
- 상품, 유저 정보는 데이터가 생성될 때만 접근이 가능했기에, api 서버에서 서빙시, 다른 context들(상품, 유저정보)을 이용하는 것이 불가능
- 점진적인 개선이 어렵다
- 모델 재활용이 어렵다
하나의 context가 추가될 때마다 모델을 새로 짜야함
<목표>
1. 추천 모델과 서비스의 분리
2. 상품, 유저 정보를 서빙타임에 접근가능해야함
3. 필터, 부스팅등의 변경이 쉽고 빨라야 함
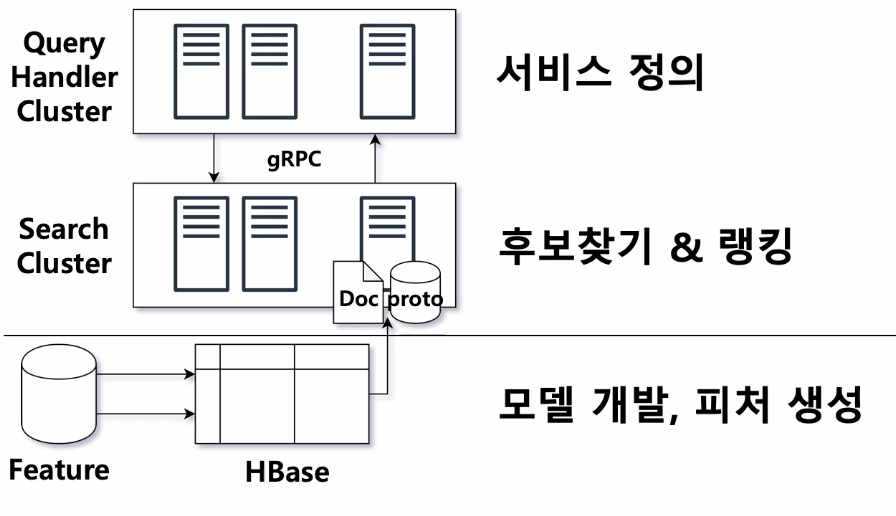
3. 현재의 추천 시스템
- 추천시스템과 서비스의 분리
- 추천 모델에 검색엔진을 사용

<최종 플랫폼>
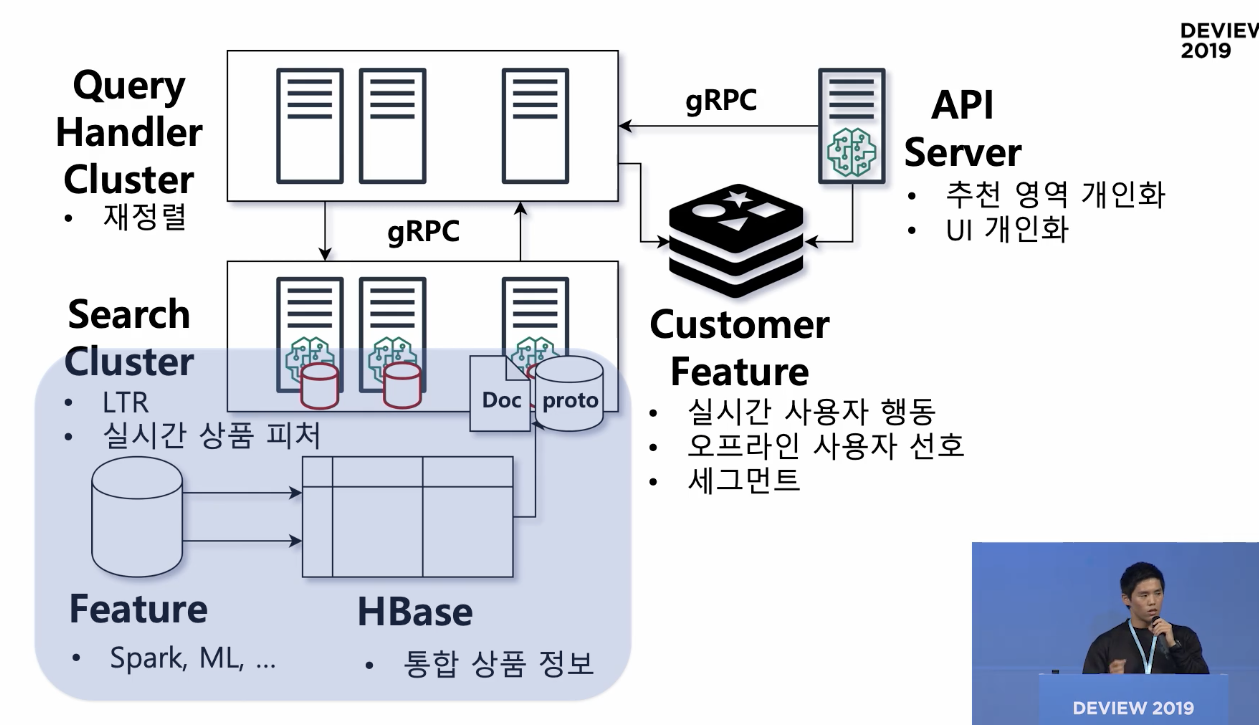
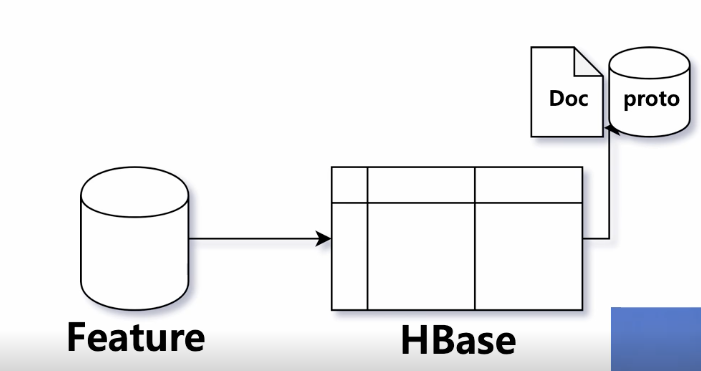
1. Feature-HBASE -> Indexing
- 추천 모델들로 상품간의 연관성(feature)를 생성-> indexing
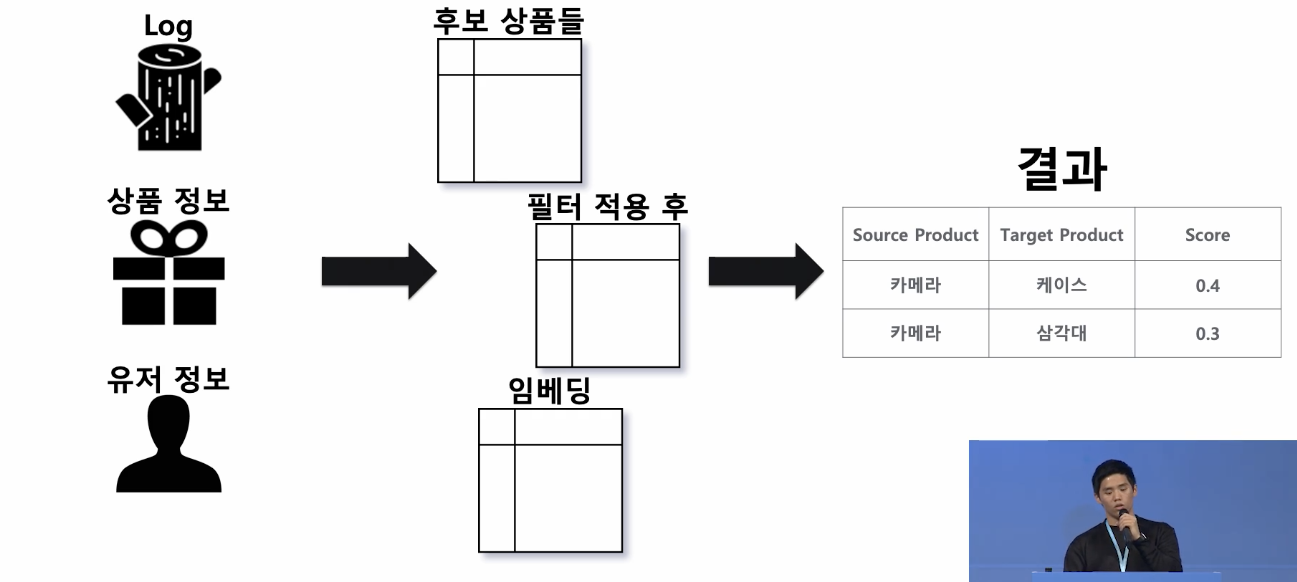
상품의 모든 정보를 한 곳에 모음
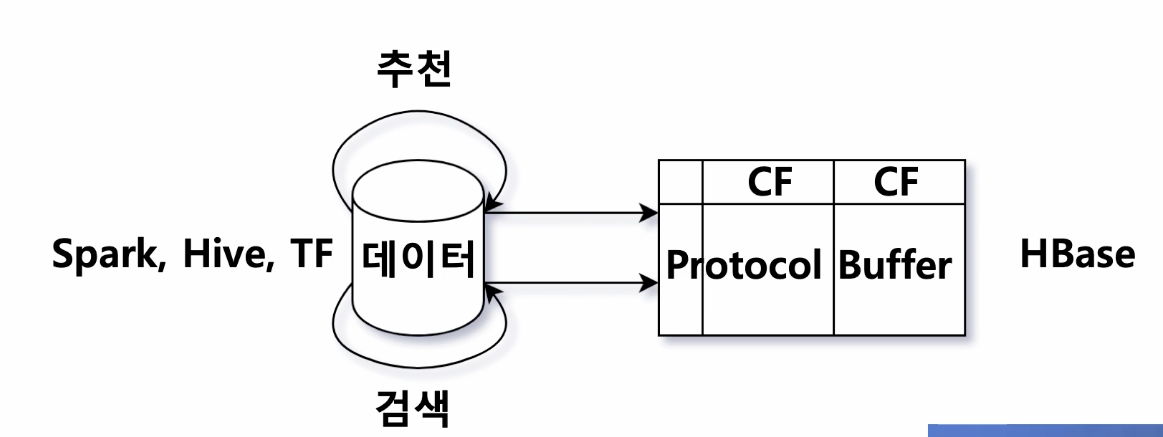
검색도 상품에 대한 정보를 잘 가지고 있어야 쿼리가 들어왔을 때 해당 상품을 잘 보여줄 수 있겠죠? - 상품에 대한 정보를 잘 나타낼 수 있는 feature로 만들기!
-> 이렇게 만든 feature를 주기적으로 업데이트해서 HBASE에 저장
검색팀과 추천팀은 각각의 column family를 두고 protocol buffer로 각자 관리하는 데이터를 저장함 - protocol buffer

- 상품 그 자체가 갖고 있는 feature(image, price, category,n_review)
- 다른 어떤 상품에 몇 점의 점수로 추천이 나갈 수 있는지에 대한 것도 반복필드로 두고있음

- 인덱싱
위의 정보들을 HBASE에서 꺼내서 인덱싱을 하게 됨
현재 document(상품)에 대해서 어떤 상품에 검색이 되어야 하는지를 페이로드로 reverse indexing함
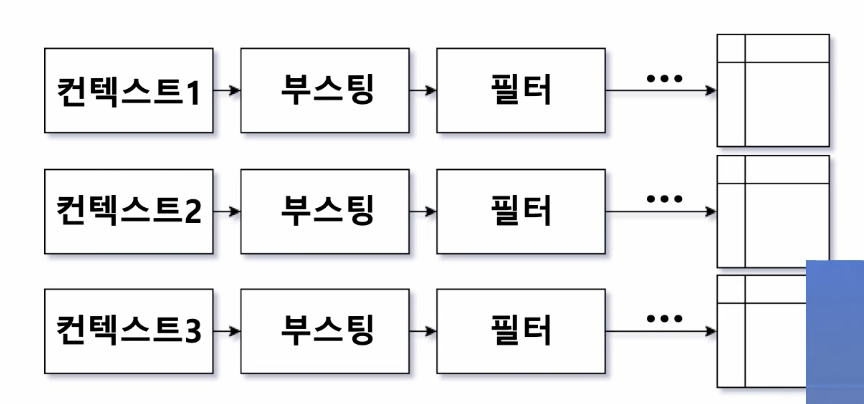
2. Search cluster
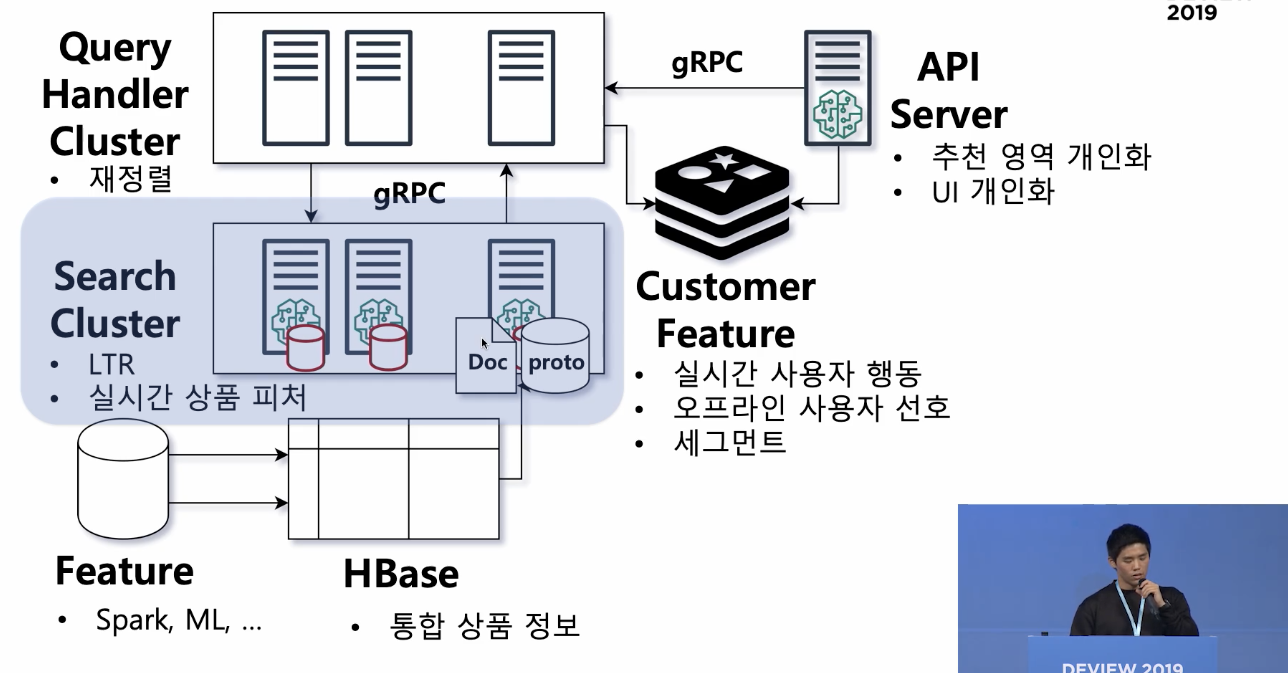
- 컨텍스트와 관련된 상품을 찾고 -> 조건에 따라 필터 -> 점수에 따라 정렬
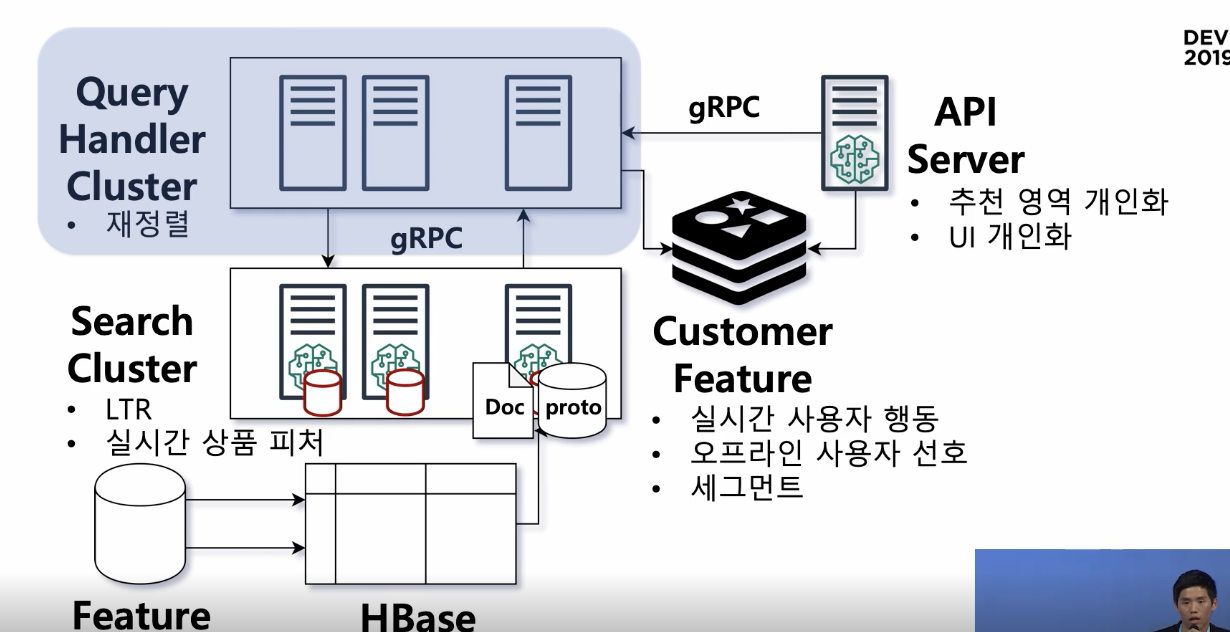
- 컨텍스트는 query handler cluster라는 별도의 클러스터가 컨텍스트를 정의함
(서치 클러스터의 일종의 레퍼, 검색 서비스의 api server라고 생각할 수 있음)
3. Query Handler Cluster
- 컨텍스트 정의(=서비스 정의)
예. 냄비와 함께 살 할인 식품을 추천해주세요!- query: bought together(같이 산 상품)라는 필드에 냄비가 index되어있는 상품을 찾아줌
- filter: category 는 식품으로 걸어주고
- boost: 할인율
- 추가 정렬: 고기, 생선, 야채를 번갈아서 보여주자(추가적인 reranking)
4. 더 나은 추천을 위해
1. feature 개발 - LTR
- 쿼리 튜닝

feature가 많아 질 수록, 이 것들을 모델에 적용할 때, 어떻게 가중치를 주고 할지를 매뉴얼로 정하는 것은 비효율적
- Learning to Rank
: 쿼리 튜닝을 모델에게 맡기자
- 상품 feature + 상품 연관성 feature (= 추천 후보 상품의 feature vector)
- 적당한 label로 머신러닝 모델을 학습시키면 -> 이 상품의 점수가 된다
- search cluster 노드는 모델을 들고 각자의 추천 후보 상품을 리랭킹
- 모델의 결과가 이상할 수 있기 때문에, 리뷰/ctr등으로 보정(휴리스틱)
- LTR Training
- 어떤 상품이 어떤 feature를 가지고 추천되었는지, 그때의 반응이 어땠는지를 알아야함
- 이때, 새로운 feature를 도입하면, 이 feature에 대해서는 로그가 없기 때문에 LTR 학습을 바로 적용할 수 없다? -> 로그를 이용해서 쿼리를 재현하여 작은 크롤링 클러스터를 띄워서 feature를 backfill해서 사용 -> 유저의 반응은 2-3일 만에 한번씩 반영
2. feature engineering - 실시간 개인화
- 실시간 개인화
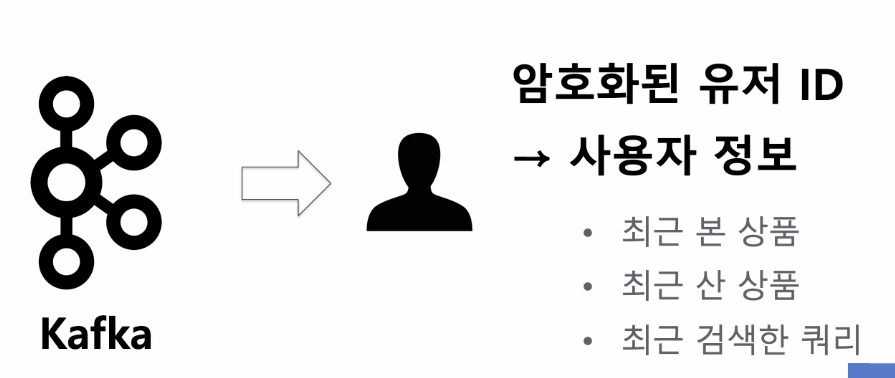
-
유저의 최근 행동을 관리
-
사용자 분석 모델(선호 카테고리, 선호 가격대, 브랜드...)
-
유저 상품 연관성
- 유저 세그먼트
모든 유저와 모든 아이템에 대해 클러스터를 만드는 것은 비효율적 -> 유저 세그먼트로!
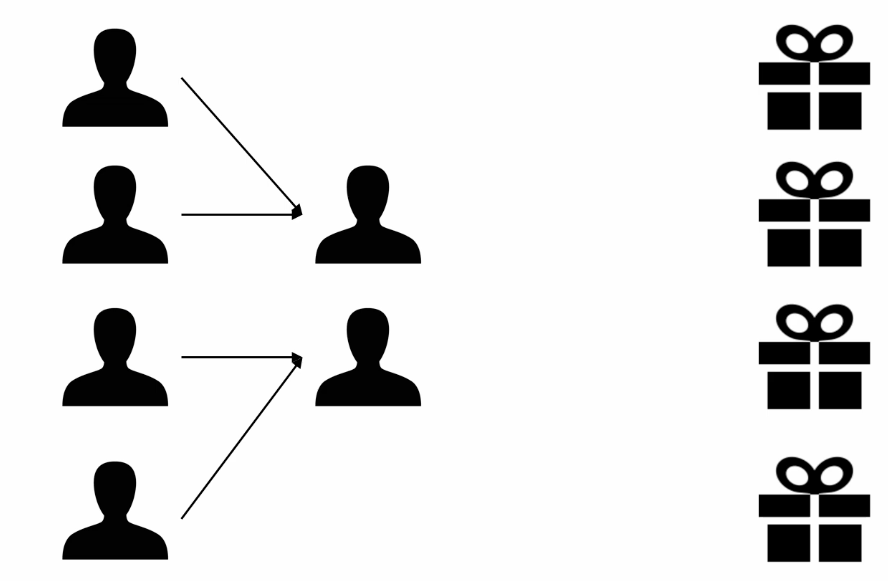
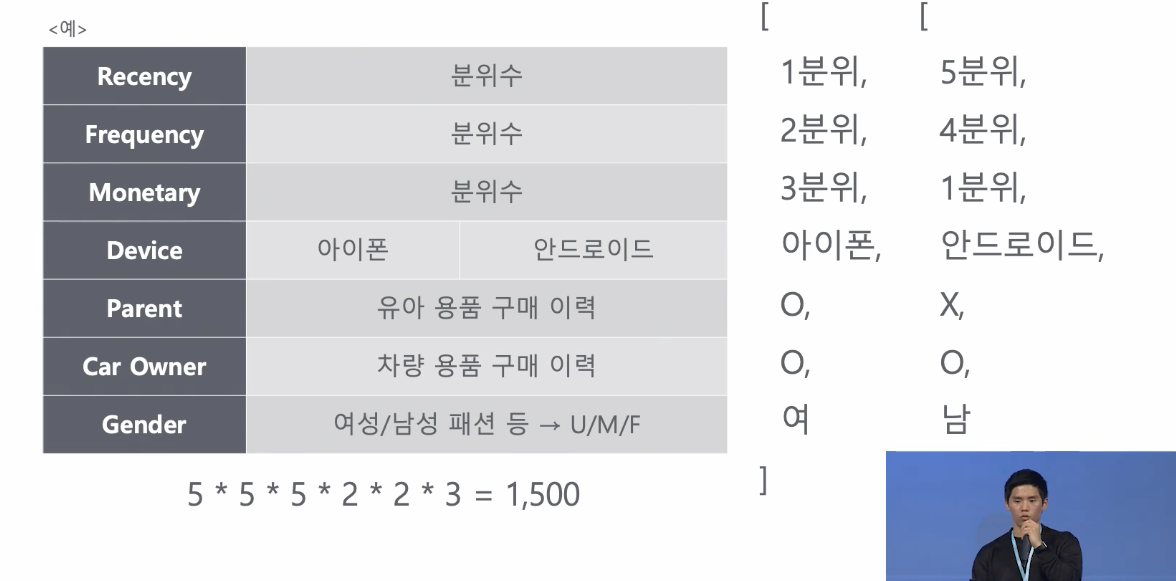
-
추천 후보군에 있는 상품의 실시간 퍼포먼스를 어떻게 볼까?
~~

- feature selection

- 모델이 해당 피처를 얼마나 중요하게 생각하는지
- 피처의 증감에 따른 모델 결과의 증감
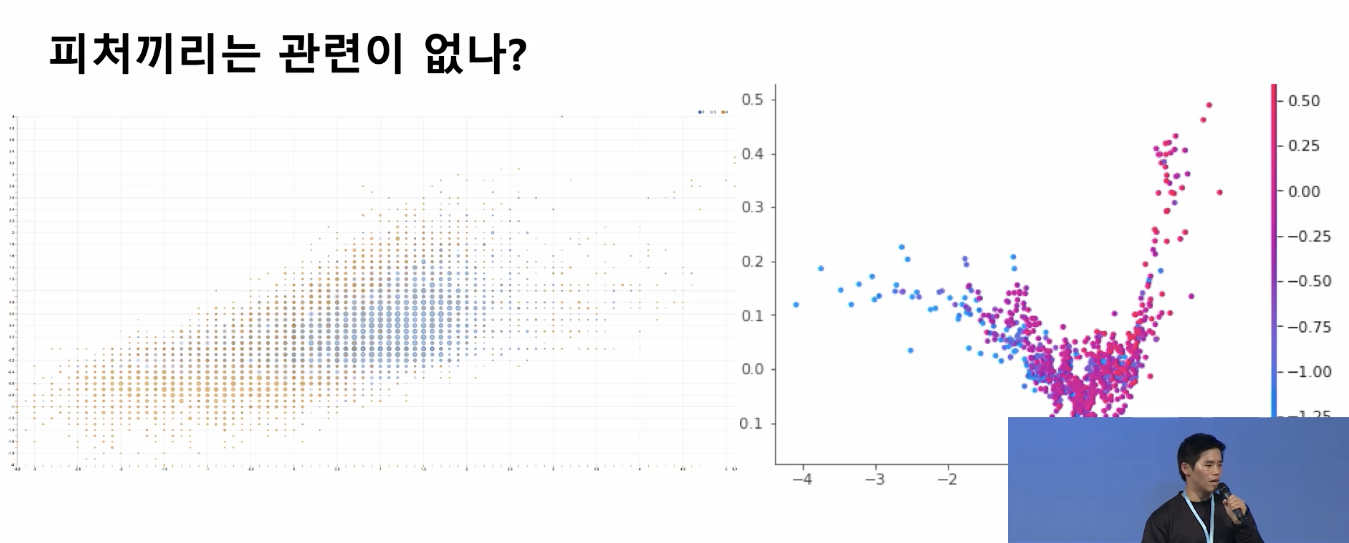
- 피처간의 상관관계
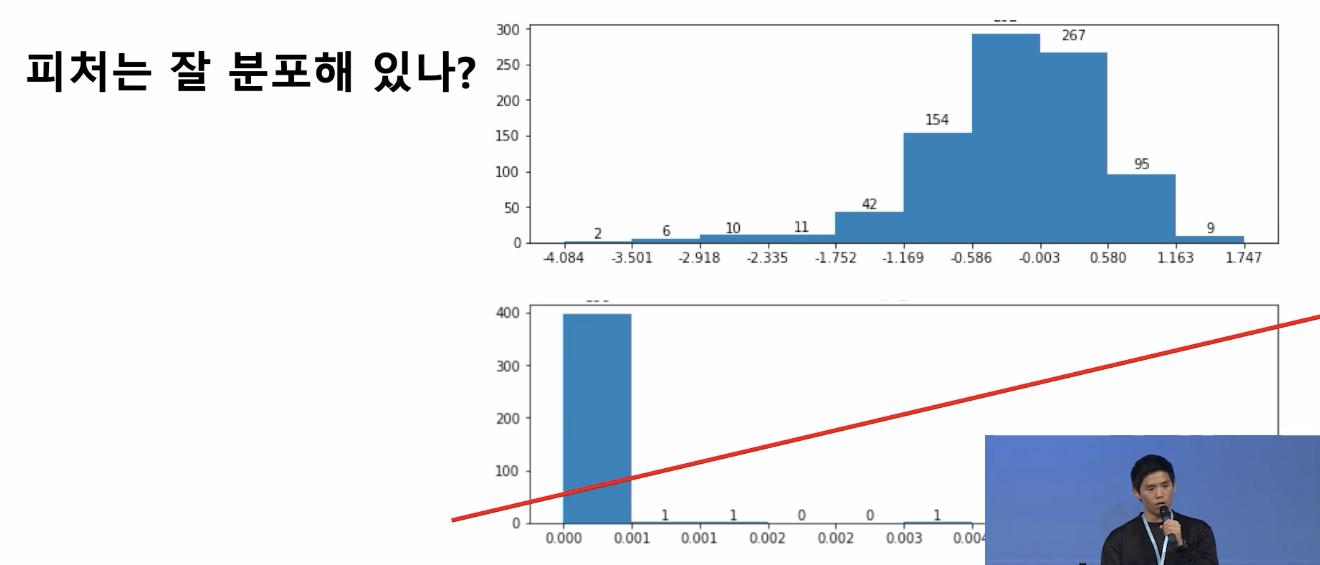
- 피처의 분포가 고르게 분포되어있나?
- 그 밖의...

- raw feature: 각 feature가 해당 모델에 어떤 영향을 갖는지를 해석하기에는 쉽지만, 각 feature간의 상관관계가 높을 수 있음 -> corr을 작도록 정제

- feature engineering >> parameter tuning
5. QnA
- cold start
유저의 행동 로그를 통해 유저 선호를 파악 - 추천 성능 지표: AB 테스트
- LTR 모델: decision tree

재밌는게 재밌는거다