텐서플로우를 활용해 이미지 분류하는 모델을 설계해보자.
데이터셋 준비
고양이와 강아지 데이터를 가지고 분류 모델을 만들 예정이다.
tensorflow_datasets 패키지를 이용해 데이터셋을 갖고 온다.
import tensorflow_datasets as tfds
(raw_train, raw_validation, raw_test), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
/----------------------------------------------------------/
# 출력
Downloading and preparing dataset 786.68 MiB (download: 786.68 MiB, generated: Unknown size, total: 786.68 MiB) to /aiffel/tensorflow_datasets/cats_vs_dogs/4.0.0...
Dl Completed...: 100%
1/1 [00:08<00:00, 8.49s/ url]
Dl Size...: 100%
786/786 [00:08<00:00, 93.74 MiB/s]
Generating train examples...: 45%
10515/23262 [00:05<00:06, 2023.91 examples/s]
Dataset cats_vs_dogs downloaded and prepared to /aiffel/tensorflow_datasets/cats_vs_dogs/4.0.0. Subsequent calls will reuse this data.print(raw_train)
print(raw_validation)
print(raw_test)
/-------------------/
# 출력
<PrefetchDataset shapes: ((None, None, 3), ()), types: (tf.uint8, tf.int64)>
<PrefetchDataset shapes: ((None, None, 3), ()), types: (tf.uint8, tf.int64)>
<PrefetchDataset shapes: ((None, None, 3), ()), types: (tf.uint8, tf.int64)>이미지는 (height, width, channel)로 3차원 데이터이기 때문에 (None, None, 3)과 같이 나타난다. 이때 height와 width가 None으로 나타난 이유는 무엇일까? 모든 이미지의 크기가 전부 다르기 때문이다. 뒤의 3은 이미지의 색을 표현하는 채널의 수를 나타낸다. 컬러 이미지의 경우, 항상 3개의 채널을 가지고 있어야 하고, 흑백 이미지는 white/black만 나타내면 되므로 단 하나의 채널만 있어도 충분하다.
label은 특정 이미지가 강아지인지, 혹은 고양이인지를 나타내는 단일 값이다.
데이터 전처리
데이터를 이용하기 위해서는 데이터를 일정하게 만드는 전처리가 필요하다. 우선 시각화를 통해 데이터를 확인해보자.
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
plt.figure(figsize=(10, 5))
get_label_name = metadata.features['label'].int2str
for idx, (image, label) in enumerate(raw_train.take(10)): # 10개의 데이터를 가져온다.
plt.subplot(2, 5, idx+1)
plt.imshow(image)
plt.title(f'label {label}: {get_label_name(label)}')
plt.axis('off')
/---------------------------------------------------------------------------------/
# 출력
강아지는 label 1로, 고양이는 label 0으로 설정되어 있다. 모델을 학습시킬 때에는 이미지 사이즈를 통일시켜 주는 작업을 해야한다.
format_example() 함수를 이용해 이미지를 같은 포맷으로 통일 시켜보자.
아래 코드는 이미지의 사이즈를 160x160 픽셀로 통일시킬 뿐만 아니라, 각 픽셀값의 scale을 수정해주는 역할도 한다.
🌈 간단 상식 - 타입캐스팅(Type Casting)
형변환이라고도 불리는 타입개스팅은 다른 데이터 타입으로 형(타입)을 바꿔주는 것을 의미한다. 정수형을 실수형으로 바꾸기 위해 float()를 사용하는 것이 타입캐스팅의 한 예이다.
이제 format_example() 함수를 raw_train, raw_validation, raw_test 에 map() 함수로 적용시켜서 원하는 모양의 train, validataion, test 데이터셋으로 변환해보자.
IMG_SIZE = 160 # 리사이징할 이미지의 크기
def format_example(image, label):
image = tf.cast(image, tf.float32) # image=float(image)같은 타입캐스팅의 텐서플로우 버전.
image = (image/127.5) - 1 # 픽셀값의 scale 수정
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
return image, label
train = raw_train.map(format_example)
validation = raw_validation.map(format_example)
test = raw_test.map(format_example)
print(train)
print(validation)
print(test)
/---------------------------------------------------------------------------------------/
# 출력
<MapDataset shapes: ((160, 160, 3), ()), types: (tf.float32, tf.int64)>
<MapDataset shapes: ((160, 160, 3), ()), types: (tf.float32, tf.int64)>
<MapDataset shapes: ((160, 160, 3), ()), types: (tf.float32, tf.int64)>(160, 160, 3)으로 변경된 것을 확인할 수 있다.
plt.figure(figsize=(10, 5))
get_label_name = metadata.features['label'].int2str
for idx, (image, label) in enumerate(train.take(10)):
plt.subplot(2, 5, idx+1)
image = (image + 1) / 2
plt.imshow(image)
plt.title(f'label {label}: {get_label_name(label)}')
plt.axis('off')
/------------------------------------------------------/
# 출력
모든 이미지의 크기가 균일해진 것을 확인할 수 있다.
모델 구조 설계
데이터 준비가 끝났으니 학습할 모델을 만들어보자.
먼저 모델 생성에 필요한 다음 함수들을 가져온다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, MaxPooling2Dmodels는 모델 그 자체를 구축하기 위한 함수들을 포함하고 있고, layers에는 모델의 구성 요소인 여러 가지 종류의 레이어(layer), 즉 "층"이라는 함수들을 가지고 있다. Sequential은 말 그대로 "연속적인" 모델을 쌓기 위한 함수이다. Sequential 함수 안에 연속적으로 여러 가지 레이어들이 들어간다.
model = Sequential([
Conv2D(filters=16, kernel_size=3, padding='same', activation='relu', input_shape=(160, 160, 3)),
MaxPooling2D(),
Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'),
MaxPooling2D(),
Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'),
MaxPooling2D(),
Flatten(),
Dense(units=512, activation='relu'),
Dense(units=2, activation='softmax')
])
model.summary()
/-------------------------------------------------------------------------------------------------/
# 출력
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 160, 160, 16) 448
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 80, 80, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 80, 80, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 40, 40, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 40, 40, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 20, 20, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 25600) 0
_________________________________________________________________
dense (Dense) (None, 512) 13107712
_________________________________________________________________
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 13,132,322
Trainable params: 13,132,322
Non-trainable params: 0
_________________________________________________________________Conv2D, MaxPooling2D, Flatten, Dense라는 네 가지 종류의 레이어를 사용했다. summary() 메소드는 모델의 전체 구조를 한눈에 보여준다.
출력된 표를 보면 shape는 모두 (None, height, width, channel)로 4차원이다. 첫 번째 차원은 데이터의 개수를 나타낸다. 여기서는 정해지지 않은 수라는 None 기호로 표시된다. None은 배치(batch) 사이즈에 따라 모델에 다른 수의 입력이 들어올 수 있음을 나타낸다.
데이터는 6개의 레이어를 지나면서 height와 width는 점점 작아지고, channel은 점점 커지다가, flatten 계층을 만나 25,600(20x20x64)이라는 하나의 숫자로, 즉 1차원으로 shape가 줄어든다.
앞의 CNN(Convolutional Neural Net)에서 점점 작은 feature map이 출력되다가, Flatten과 Dense 레이어를 거쳐 1차원으로 shape이 줄어드는 네트워크는 CNN을 사용한 딥러닝 모델의 가장 대표적인 형태이다.
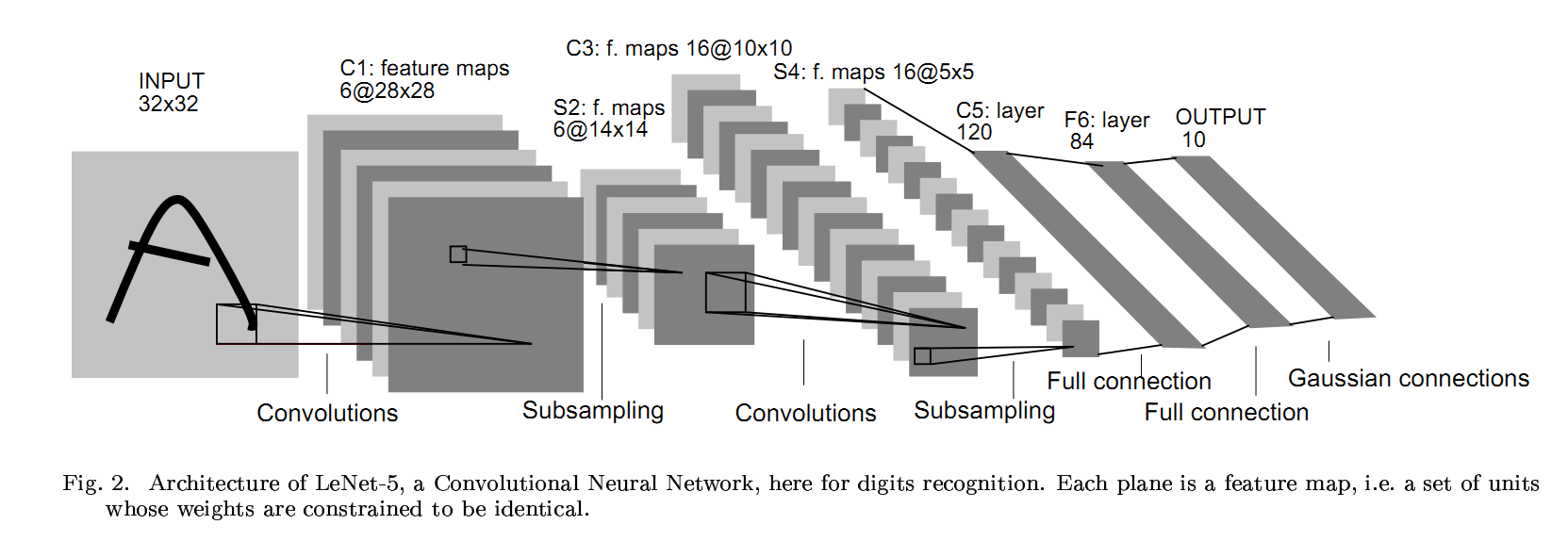
[출처 논문] : [Gradient-Based Learning Applied to Document Recognition]
맨 왼쪽처럼 이미지 한 장이 입력되면 그 이미지는 Convolutional(합성곱) 연산을 통해 그 형태가 점점 길쭉해지다가, Flatten 레이어를 만나면 오른쪽처럼 한 줄로 펴진다. 3차원의 이미지를 1차원으로 펼치는 것이다.
Flatten을 조금 더 직관적으로 이해하기 위해 배열을 이용해보자.
import numpy as np
image = np.array([[1, 2], [3, 4]])
print(image.shape)
print(image)
image.flatten()
/--------------------------------/
# 출력
(2, 2)
[[1 2]
[3 4]]
array([1, 2, 3, 4])모델에서 flatten 레이어를 통과한다는 것도 위와 같이 모든 숫자를 일렬로 펼쳐놓는 것과 같다. 그 후 Dense 레이어에서 512개의 노드로 축소시켜 최종 출력은 단 두 개의 숫자로 구성된 하나의 확률분포를 내뱉게 된다. 이 두 숫자는 각각 입력된 이미지가 강아지일 확률과 고양이인 확률을 의미하게 될 것이다.
모델 학습
모델 설계를 끝냈으면 데이터를 모델에 넣어 학습시켜야한다. 모델을 학습할 수 있는 형태로 변환해주기 위해서는 compile을 사용한다.
learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])compile을 하기 위해서는 optimizer, loss, metrics 세 가지가 필요하다.
optimizer는 학습을 어떤 방식으로 시킬 것인지 결정한다. 어떻게 최적화시킬 것인지를 결정하기 때문에 최적화 함수라고 부르기도 한다.loss는 모델이 학습해나가야 하는 방향을 결정한다. 이 문제에서는 모델의 출력은 입력받은 이미지가 고양이인지 강아지인지에 대한 확률분포로 두었으므로, 입력 이미지가 고양이(label=0)일 경우 모델의 출력이 [1.0, 0.0]에 가깝도록, 강아지(label=1)일 경우 [0.0, 1.0]에 가까워지도록 하는 방향을 제시한다.metrics는 모델의 성능을 평가하는 척도이다. 분류 문제를 풀 때, 성능을 평가할 수 있는 지표는 정확도(accuracy), 정밀도(precision), 재현율(recall) 등이 있고, 이 모델에서는 정확도를 사용했다.
성능 평가 지표란?
compile을 마무리 했으니 데이터를 준비한다.
한 스텝에 학습시킬 데이터 개수인 BATCH_SIZE와 학습 데이터를 적절히 섞어줄 SHUFFLE_BUFFER_SIZE를 설정한다. BATCH_SIZE에 따라 32개의 데이터를 랜덤으로 뿌려줄 train_batches, validation_batches, test_batches를 만들어 준다. train_batches는 모델이 끊임없이 학습될 수 있도록 전체 데이터에서 32개를 랜덤으로 뽑아 계속 제공해 줄 것이다.
BATCH_SIZE = 32
SHUFFLE_BUFFER_SIZE = 1000
train_batches = train.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
validation_batches = validation.batch(BATCH_SIZE)
test_batches = test.batch(BATCH_SIZE)
for image_batch, label_batch in train_batches.take(1):
pass
image_batch.shape, label_batch.shape
/------------------------------------------------------------------/
# 출력
(TensorShape([32, 160, 160, 3]), TensorShape([32]))image_batch의 shape는 [32, 160, 160, 3]을, label_batch의 shape는 [32]를 나타낸다.
이제 학습을 해보자.
EPOCHS = 10
history = model.fit(train_batches,
epochs=EPOCHS,
validation_data=validation_batches)
/-----------------------------------------------------/
# 출력
...
...
...
loss: 0.1181 - accuracy: 0.9609 - val_loss: 0.6526 - val_accuracy: 0.7820학습 단계에 따른 정확도 변화를 그래프로 확인해 보자.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs_range = range(EPOCHS)
plt.figure(figsize=(12, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend()
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend()
plt.title('Training and Validation Loss')
plt.show()
/---------------------------------------------------------/
# 출력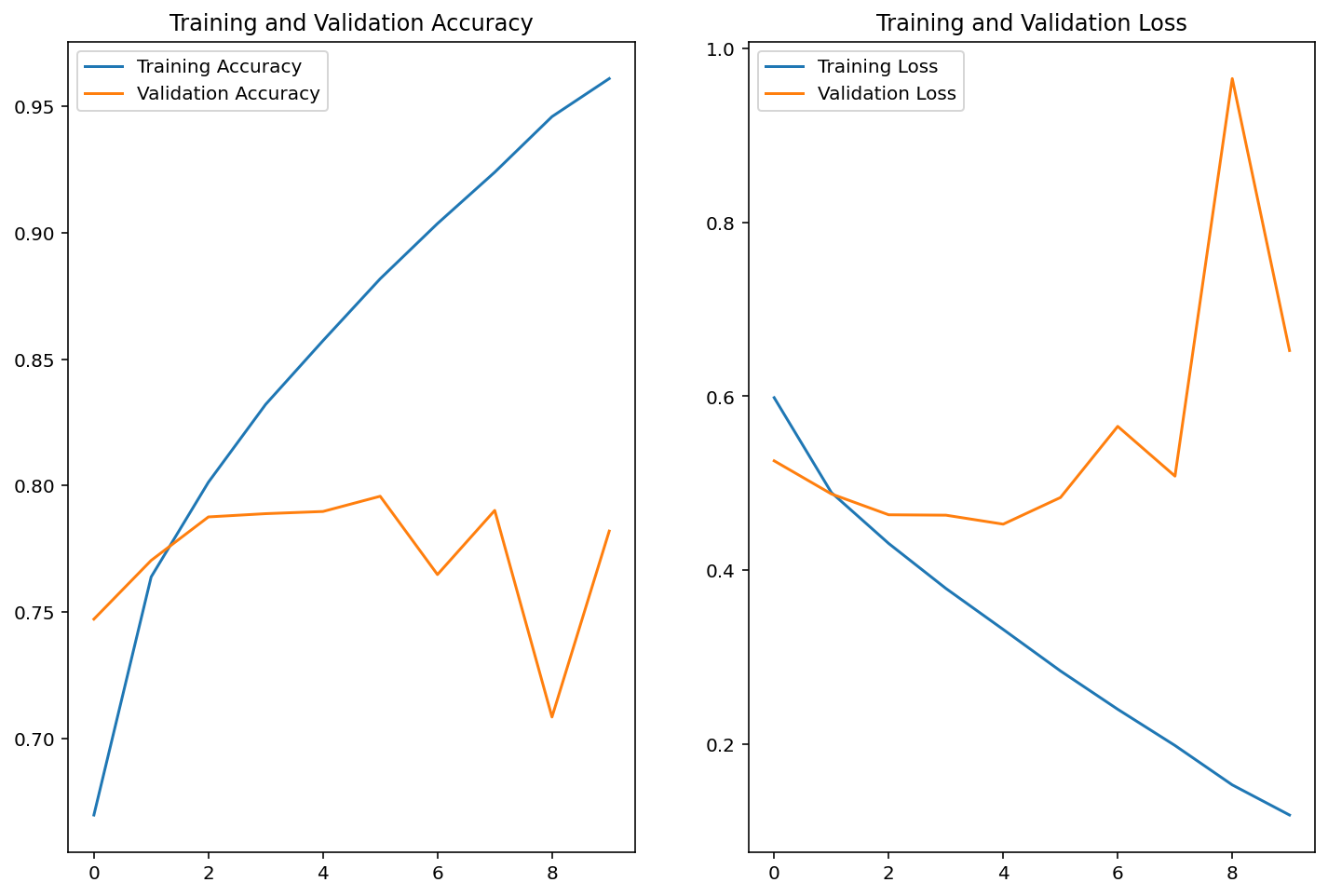
training accuracy는 꾸준히 오르지만 validation accuracy는 어떤 한계선을 넘지 못한다. 심지어 loss 그래프에서 training loss는 계속 안정적으로 줄어들지만, validation loss값은 특정 순간 이후로 다시 커지는 모습을 보인다.
이러한 문제를 과적합(Overfitting, 오버피팅) 이라고 한다. 모델의 성능이 제대로 올라가려면 "학습하지 않은" 데이터에 대해서도 성능이 좋아야 하는데, 훈련 데이터만으로 계속 학습하다 보니 그 데이터에만 과도하게 적합(fitting) 되어서 일반화 능력이 떨어지게 되는 것이다.
딥러닝 모델을 학습시킬 때는 과적합 문제를 예민하게 다루고, 과적합이 되지 않는 순간을 잘 잡아내 일반화가 잘 되는 모델로 학습시키는 것이 중요하다.
모델의 예측 결과를 확인하고 싶을 때는 다음과 같이 model.predict를 활용한다.
for image_batch, label_batch in test_batches.take(1):
images = image_batch
labels = label_batch
predictions = model.predict(image_batch)
pass
predictions
/---------------------------------------------------/
# 출력
array([[9.99950409e-01, 4.95602690e-05],
[8.37983608e-01, 1.62016422e-01],
[1.75595254e-01, 8.24404716e-01],
[9.99983311e-01, 1.66616992e-05],
[9.05693352e-01, 9.43066701e-02],
[1.92084864e-01, 8.07915151e-01],
[1.28201023e-01, 8.71798933e-01],
[2.66628772e-01, 7.33371198e-01],
[4.24812168e-01, 5.75187862e-01],
[4.65652466e-01, 5.34347534e-01],
[3.55241805e-01, 6.44758165e-01],
[9.99755442e-01, 2.44517520e-04],
[9.99969125e-01, 3.09017341e-05],
[1.01581449e-02, 9.89841878e-01],
[9.72879410e-01, 2.71206144e-02],
[9.99597371e-01, 4.02642938e-04],
[7.48997927e-01, 2.51002073e-01],
[7.62127966e-05, 9.99923825e-01],
[8.59040320e-01, 1.40959665e-01],
[9.95459974e-01, 4.53995680e-03],
[8.54554772e-01, 1.45445198e-01],
[9.48256910e-01, 5.17430119e-02],
[9.99906659e-01, 9.32905532e-05],
[9.24814463e-01, 7.51855299e-02],
[6.96107388e-01, 3.03892583e-01],
[5.97292304e-01, 4.02707696e-01],
[9.99828815e-01, 1.71174295e-04],
[7.10226774e-01, 2.89773196e-01],
[9.98970628e-01, 1.02933706e-03],
[9.77889359e-01, 2.21105758e-02],
[9.99987483e-01, 1.25691795e-05],
[9.94895279e-01, 5.10470290e-03]], dtype=float32)이 값은 모델이 판단한 [고양이일 확률, 강아지의 확률]인데, [1.0, 0.0]에 가까울수록 label이 0인 고양이로, [0.0, 1.0]에 가까울수록 label이 1인 강아지로 예측했다고 볼 수 있다.
prediction 값들을 실제 추론한 라벨(고양이:0, 강아지:1)로 변환해 보자.
predictions = np.argmax(predictions, axis=1)
predictions
/------------------------------------------/
# 출력
array([0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0])시각화해보자.
plt.figure(figsize=(20, 12))
for idx, (image, label, prediction) in enumerate(zip(images, labels, predictions)):
plt.subplot(4, 8, idx+1)
image = (image + 1) / 2
plt.imshow(image)
correct = label == prediction
title = f'real: {label} / pred :{prediction}\n {correct}!'
if not correct:
plt.title(title, fontdict={'color': 'red'})
else:
plt.title(title, fontdict={'color': 'blue'})
plt.axis('off')
/--------------------------------------------------------------------------------/
# 출력
32개 이미지에 대해 예측 정확도는 몇일까? 직접 코드로 구현해보자.
count = 0 # 정답을 맞춘 개수
for image, label, prediction in zip(images, labels, predictions):
correct = label == prediction
if correct:
count = count + 1
print(count / 32 * 100)
/--------------------------------------------------------------/
# 출력
78.125